Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Subjects:
Engineering, Electrical & Electronic
Maritime traffic monitoring systems are particularly important in Mediterranean ports, as they provide more comprehensive data collection compared to traditional systems such as the Automatic Identification System (AIS), which is not mandatory for all vessels.
- maritime surveillance
- distance estimation
- pinhole camera model
- instance segmentation
1. Introduction
Analysis of maritime traffic density plays an important role in efficiently managing port operations and ensuring safe navigation. Conventionally, this analysis relies on data obtained from radar-based systems, the Automatic Identification System (AIS), and human observation—each method has its own challenges and limitations. As a result, it is difficult to distinguish between different types of vessels such as passenger ships, fishing vessels, recreational boats, etc. [1]. This lack of specificity hinders a comprehensive analysis of maritime traffic density and complicates the decision-making processes of port authorities. On the other hand, AIS, a transponder-based system, provides data on a vessel’s identity, type, position, course, and additional safety-related information. In previous research, it was demonstrated that exclusive reliance on AIS data leads to an incomplete representation of maritime traffic in the Mediterranean, primarily due to the high number of vessels operating without AIS [2]. Results showed that automated maritime video surveillance, employing Convolutional Neural Networks (CNN) for detailed vessel classification, can capture 386% more traffic than the AIS alone. This highlights the significant potential of automated maritime video surveillance systems to enhance maritime security and traffic monitoring. These systems can overcome the shortcomings of traditional methods by providing more detailed, reliable, and comprehensive maritime surveillance.
The existing real-time maritime traffic counting system based on a neural network, presented in [2], is used to monitor incoming and outgoing traffic in the port of Split, Croatia. This research aims to improve this system by introducing distance estimation between the camera and the vessels, an important component of advanced monitoring systems for analyzing maritime traffic density. Distance estimation methods from images or videos, i.e., the extraction of 3D information from 2D sources, is an area that has been intensively researched over the last decade. Its applicability extends across various fields, including autonomous driving [3], traffic safety [4], animal ecology [5], assistive technologies for the visually impaired [6], etc.
As shown in Figure 1, the existing counting system uses a single static long-range video camera to monitor traffic. The captured video stream is then processed by an object detection module that identifies and classifies vessels, which are then tracked and quantitatively counted. Vessels are expected to pass through the monitored zone at distances ranging from 150 m to 500 m from the camera. To implement distance estimation, a monocular approach using the pinhole camera model in conjunction with triangle similarity is investigated. This technique requires knowledge of the height (or width) of the observed vessel, as well as a reference height (or width) for each class of vessels to enable accurate distance estimation. It is important to acknowledge that the pinhole camera model can incur estimation errors of up to 20%, as noted in [5][6][7].
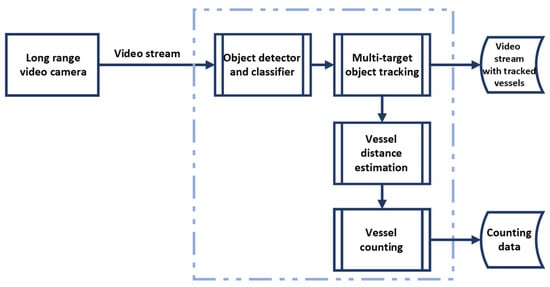
Figure 1. Illustration of the real-time maritime traffic counting system.
Initially, the Vessel-Focused Distance Estimation (VFDE) method was developed using pinhole camera model. This method estimates the distance directly by focusing on the vessel as a whole, using the vessel’s height as a parameter for the distance calculation. VFDE integrates the YOLOv4 object detector [8], a component already integrated into the existing counting system. While the preliminary results of VFDE were promising, it was found that significant height variability within certain vessel classes led to increased estimation errors. These errors depend on the discrepancy between the reference and actual heights of the vessels [5][7].
2. Distance Estimation Approach for Maritime Traffic Surveillance Using Instance Segmentation
Camera-based distance estimation methods can be divided into two main categories: the use of a monocular camera and a stereo vision [9]. Stereo vision emulates how human eyes perceive depth, employing two cameras placed at a certain distance apart. The major advantage of these systems is their ability to provide rich, accurate, and detailed depth information in real-time. However, stereo vision systems are more complex and expensive due to the need for two cameras, and they require careful calibration to ensure the two cameras are properly aligned [7]. Monocular vision systems, on the other hand, use only one camera to capture images or videos. Since there is only one input, these systems do not natively provide depth information. Instead, they rely on other cues to estimate depth, such as object size, perspective, and shadows. Moreover, some articles proposed adding RFID [10] as a complement to the surveillance camera for distance estimation, or additional sensors such as a LiDAR sensor [11] or Kinect sensor [12].
The paper [13] proposes a monocular vision-based method for estimating face-to-camera distance using a single camera. The approach includes three steps: extraction and location of feature region, calculation of the pixel area of the characteristic triangle, and construction of a measurement formula (derived from the pinhole camera model). According to the experimental analysis, the proposed method shows over 95% accuracy with a processing time of about 230 ms. Authors in [14] evaluated three distance estimation methods for road obstacles. The methods are based on the pinhole camera model: one uses the geometry of similar triangles, another utilizes the cross-ratio of a set of collinear points, and the last relies on camera matrix calibration. Results suggest that the triangle similarity method is more suitable for distance estimation at wide angles. For accurate distance estimation to the object (from a vehicle) using a single camera, the paper [15] presented the technique that treats the camera as an ideal pinhole model. This technique employs the principle of triangle similarity for distance estimation after determining the camera’s focal length in pixels. Object detection is achieved through image processing techniques, and the known width of the object, along with the calculated focal length, is used by the algorithm to calculate the distance after identification. Experimental results showed satisfactory accuracy at short range distances for objects of varying widths, while it is noted that the technique may not perform as well with unknown or variable width objects. While in [7], an experiment is conducted to calculate human distance using a single camera, pinhole camera model, and triangle similarity concept to estimate the distance. The results reveal that for shorter distances, an estimation error ranges from less than 10% [5][7] up to 17% [6], while the error rate increases to 20% [7] for longer distances. It is noted that the error depends on the difference between the reference height and the actual height of the target [5][7].
Prior to distance estimation, there were two main approaches for object detection in the literature: traditional machine learning techniques [10][13][15], and neural network methods [3][6][7][16][17][18]. The results indicate that the accuracy of distance estimation is closely related to the quality of the detection results. Furthermore, Ref. [18] argues for future improvements by using more sophisticated CNN models that include object segmentation. The goal of segmentation is to make detailed predictions by assigning labels to each pixel of an image, and classifying each pixel based on the object or region it belongs to [19]. Instance segmentation, which combines the tasks of object detection and segmentation [20], has evolved into a technique in its own right. It is characterized by its ability to identify and separate individual objects of the same class, which enables detailed examination at the pixel level [19][21].
This entry is adapted from the peer-reviewed paper 10.3390/jmse12010078
References
- Petković, M.; Vujović, I.; Lušić, Z.; Šoda, J. Image Dataset for Neural Network Performance Estimation with Application to Maritime Ports. J. Mar. Sci. Eng. 2023, 11, 578.
- Petković, M.; Vujović, I.; Kaštelan, N.; Šoda, J. Every Vessel Counts: Neural Network Based Maritime Traffic Counting System. Sensors 2023, 23, 6777.
- Arabi, S.; Sharma, A.; Reyes, M.; Hamann, C.; Peek-Asa, C. Farm Vehicle following Distance Estimation Using Deep Learning and Monocular Camera Images. Sensors 2022, 22, 2736.
- Liu, L.C.; Fang, C.Y.; Chen, S.W. A Novel Distance Estimation Method Leading a Forward Collision Avoidance Assist System for Vehicles on Highways. IEEE Trans. Intell. Transp. Syst. 2017, 18, 937–949.
- Leorna, S.; Brinkman, T.; Fullman, T. Estimating Animal Size or Distance in Camera Trap Images: Photogrammetry Using the Pinhole Camera Model. Methods Ecol. Evol. 2022, 13, 1707–1718.
- Chou, K.S.; Wong, T.L.; Wong, K.L.; Shen, L.; Aguiari, D.; Tse, R.; Tang, S.K.; Pau, G. A Lightweight Robust Distance Estimation Method for Navigation Aiding in Unsupervised Environment Using Monocular Camera. Appl. Sci. 2023, 13, 11038.
- Saputra, D.E.; Senjaya, A.S.M.; Ivander, J.; Chandra, A.W. Experiment on Distance Measurement Using Single Camera. In Proceedings of the ICOIACT 2021—4th International Conference on Information and Communications Technology: The Role of AI in Health and Social Revolution in Turbulence Era, Yogyakarta, Indonesia, 30–31 August 2021; pp. 80–85.
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934.
- Aicardi, I.; Chiabrando, F.; Maria Lingua, A.; Noardo, F. Recent Trends in Cultural Heritage 3D Survey: The Photogrammetric Computer Vision Approach. J. Cult. Herit. 2018, 32, 257–266.
- Duan, C.; Rao, X.; Yang, L.; Liu, Y. Fusing RFID and Computer Vision for Fine-Grained Object Tracking. In Proceedings of the IEEE INFOCOM 2017—IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9.
- Heimberger, M.; Horgan, J.; Hughes, C.; McDonald, J.; Yogamani, S. Computer Vision in Automated Parking Systems: Design, Implementation and Challenges. Image Vis. Comput. 2021, 68, 88–101.
- Eric, N.; Jang, J.W. Kinect Depth Sensor for Computer Vision Applications in Autonomous Vehicles. In Proceedings of the International Conference on Ubiquitous and Future Networks, ICUFN, Milan, Italy, 4–7 July 2017; pp. 531–535.
- Dong, X.; Zhang, F.; Shi, P. A Novel Approach for Face to Camera Distance Estimation by Monocular Vision. Int. J. Innov. Comput. Inf. Control 2014, 10, 659–669.
- Nienaber, S.; Kroon, R.S.; Booysen, M.J. A Comparison of Low-Cost Monocular Vision Techniques for Pothole Distance Estimation. In Proceedings of the 2015 IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 7–10 December 2015; pp. 419–426.
- Megalingam, R.K.; Shriram, V.; Likhith, B.; Rajesh, G.; Ghanta, S. Monocular Distance Estimation Using Pinhole Camera Approximation to Avoid Vehicle Crash and Back-over Accidents. In Proceedings of the 10th International Conference on Intelligent Systems and Control (ISCO 2016), Coimbatore, India, 7–8 January 2016.
- Ahmed, I.; Ahmad, M.; Rodrigues, J.J.P.C.; Jeon, G.; Din, S. A Deep Learning-Based Social Distance Monitoring Framework for COVID-19. Sustain. Cities Soc. 2021, 65, 102571.
- Xu, X.; Chen, X.; Wu, B.; Yip, T.L. An Overview of Robust Maritime Situation Awareness Methods. In Proceedings of the 6th International Conference on Transportation Information and Safety: New Infrastructure Construction for Better Transportation (ICTIS 2021), Wuhan, China, 22–24 October 2021; pp. 1010–1014.
- Li, H.; Qiu, J.; Yu, K.; Yan, K.; Li, Q.; Yang, Y.; Chang, R. Fast Safety Distance Warning Framework for Proximity Detection Based on Oriented Object Detection and Pinhole Model. Measurement 2023, 209, 112509.
- Hafiz, A.M.; Bhat, G.M. A Survey on Instance Segmentation: State of the Art. Int. J. Multimed. Inf. Retr. 2020, 9, 171–189.
- Sharma, R.; Saqib, M.; Lin, C.T.; Blumenstein, M. A Survey on Object Instance Segmentation. SN Comput. Sci. 2022, 3, 1–23.
- Jung, S.; Heo, H.; Park, S.; Jung, S.U.; Lee, K. Benchmarking Deep Learning Models for Instance Segmentation. Appl. Sci. 2022, 12, 8856.
This entry is offline, you can click here to edit this entry!