Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Convolutional Neural Networks (CNNs) have demonstrated remarkable success with great accuracy in classification problems. Using an ensemble of neural networks offers a simple yet effective measure to improve performance and robustness beyond that of a single network.
- ensemble learning
- convolutional neural network
- class activation map
- fingerprint
1. Introduction
Ensembling of neural networks to enhance their accuracy and robustness has been a well-established concept since 1990 when it was first introduced by [1]. Subsequently, numerous ensemble techniques have been developed, such as the cross-validation ensemble [2], model averaging ensemble, weighted average ensemble, horizontal and vertical ensemble [3], which are notable among others. While these methods have achieved significant success at enhancing the accuracy of a model’s predictions, they are also associated with a large training cost. To address this issue, the authors of [4] proposed a method that uses a cyclic cosine annealing learning rate, as proposed by [5], to guide a neural network towards different local minima and to save the weights of the network at the end of each cycle. This approach produces diverse ensemble members under a single training session. Furthermore, in [6], the authors introduced Stochastic Weight Averaging, a method that forms an ensemble in the weight space by implementing a moving average of the weights of the models, as opposed to averaging the outputs of the models. These ensemble learning methods provide a convenient approach to enhance a network’s performance and robustness.
In security applications such as detecting spoof biometrics, maintaining the robustness of the network is crucial. While the ensemble method offers potential to enhance network robustness, it often involves various trade-offs. As depicted in Figure 1, implementing the snapshot ensemble method [4] in conjunction with the cyclic cosine annealing learning rate [5] for all four sets of sensor data present in the LivDet [7] dataset leads to the degradation of accuracy in a network that had already been producing state-of-the-art results. This observation suggests that in cases for which the training dataset is small and homogeneous in nature, the number of available local minima is very limited, and it is challenging to ensure diversity among the ensemble members. The availability of biometric datasets, such as a fingerprint dataset for training a spoof detection network, is limited due to the sensitive nature of the data. The small size of the dataset can introduce significant biases during training, which may cause a reduction in ensemble accuracy.
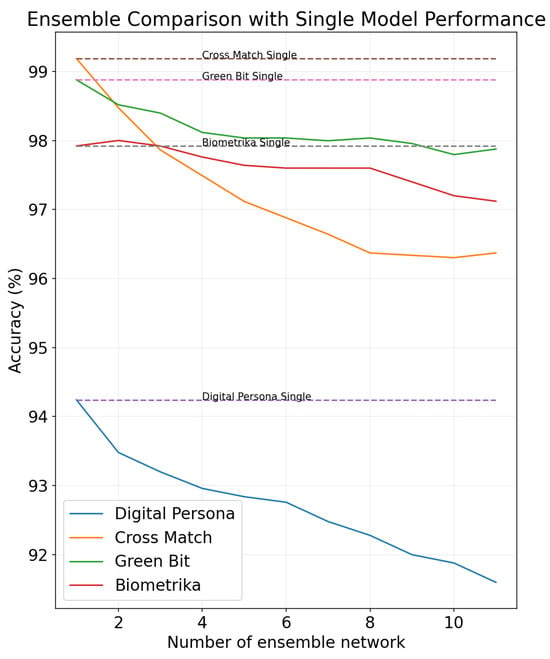
Figure 1. Performance variation of a CNN-based spoof detection network when subjected to an ensemble setting.
Explanation of the learned features of a network is instrumental to investigate potential failure modes resulting from biases in the dataset. Additionally, the ability to explain the functioning of a spoof detection network is imperative to enhance the system’s reliability. Recognizing the complexity associated with interpreting CNNs, various methodologies have been proposed, such as the Class Activation Map (CAM) [8] and the Gradient-weighted Class Activation Map (Grad-CAM) [9], to identify and visualize the specific image regions that the network utilizes for prediction. Thus, the explanations are mainly limited to the production of a saliency map, and the internal representation of the CNN is still mostly unexplainable. Furthermore, the produced saliency maps are specific for each sample, and the global interpretation of the network or the dataset is not easily found.
Nevertheless, sample-wise saliency maps can be effective information for training new networks that can use different regions for classification.
After analyzing the class activation map of a previously trained model, certain areas of the input image are entirely disregarded by the network for classification, despite containing critical features, as demonstrated in Figure 2. Additionally, strong activation regions are relatively small, which indicates that the network may ignore important parts of the input image, which could include essential information such as textures or patterns. This observation also suggests that activation perturbation of a network can be utilized to generate diverse models that can serve as ensemble members to enhance the network’s robustness and accuracy.
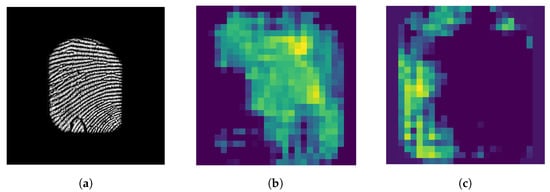
Figure 2. Impact of the proposed training method on the activation patterns of a CNN: (a) input fingerprint, (b) activation of the base network, and (c) activation of one of the ensemble members after being trained with the proposed method.
Though spoof fingerprints can be easily created using low-cost and readily available materials such as wood glue, Play-Doh, gelatin, and latex-like substances [7,10] to deceive a biometric authentication system, fabricating such spoof fingerprint can be time consuming. As a result, the datasets available for training a spoof detection network are comparatively very small in size.
2. Enhancing Ensemble Learning Using Explainable CNN for Spoof Fingerprints
Using an ensemble of neural networks offers a simple yet effective measure to improve performance and robustness beyond that of a single network [11,12,13]. Notably, in high-profile competitions such as ImageNet [14] and Kaggle (www.kaggle.com, accessed on 26 November 2023), ensembles of deep learning architectures have consistently outperformed individual models. Prior studies have demonstrated that ensembling can enhance both accuracy and robustness by exploiting network diversity [15,16,17,18,19,20,21]. Despite these benefits, the use of ensembling for neural networks remains limited due to high training costs. In light of this problem, Snapshot Ensemble [4], Fast Geometric Ensemble [22], and Stochastic Weight Averaging ensemble [6] have been proposed, wherein the authors exploit model diversity and geometric properties of the loss surface to achieve the benefits of ensembling. However, these techniques have mainly been evaluated on relatively large datasets, wherein at least 50,000 images are available in the training set, and there has been limited exploration of their effectiveness on smaller datasets such as LivDet 2015 [7].
Grad-CAM has been successfully applied to explain classifiers in image classification, image segmentation [24], and visual question answering (VQA) [25]. Its success has led to the development of Grad-CAM++ [26], which further enhances the explanation capabilities of Grad-CAM and has been used for object detection and localization [27,28,29]. The authors in [30] employed Grad-CAM as a visualization tool to identify and highlight noise across various channels of a network when processing a fingerprint image. The use of CAM is also presented in the study by [31], where it was used for patch extraction during the inference stage.
The detection of spoof fingerprints remains a prominent research topic, and CNNs have proven to be a successful approach [32]. To stimulate further research efforts in this field, several spoof detection competitions (LivDet 2009–2021) have been organized [7,10,33,34]. Notably, in the LivDet 2015 competition, the authors of [35] employed a transfer learning approach using deep CNNs, specifically AlexNet [36] and VGGNet [37], which were pre-trained on the ImageNet [14] dataset, and fine-tuned some of the layers for spoof detection of fingerprints. Meanwhile, [38] proposed a CNN architecture with similar performance but reduced test time. Improving the robustness of CNN-based spoof detection systems has been explored by [39], who adopted a hybrid approach that combines hyper-parameter tuning of a CNN and Support Vector Machines (SVMs). Siamese network architecture has been employed by the authors of [40] to improve the robustness of a fingerprint spoof detection system. The authors of [41] have proposed an altered ResNet architecture to achieve smaller parameter size and computational efficiency for a practical spoof detection application. Additionally, [42] have improved the accuracy and robustness of their system using the MobileNet-V1 [43] architecture in conjunction with the fusion of minutiae-based center-aligned local patches. However, their approach involves several complex algorithms, such as minutiae detection, local patch extraction, and patch alignment, in the training and testing procedures. Several techniques [44,45,46,47] have been proposed to generate synthetic fingerprints by leveraging style-transfer techniques. The primary objective of these approaches is to increase the number of data samples in order to address challenges associated with limited dataset sizes. A brief summary of the relevant studies is presented in Table 2.
Table 2. Summary of studies focused on fingerprint spoof detection using CNNs.
| Method | Approach | Database | Performance |
|---|---|---|---|
| Emanuela et al. [40] | Employment of Siamese network | LivDet 2013 | Avg. Accuracy = 93.1%93.1% |
| Menotti et al. [39] | Combination of hyper-parameter tuning of a CNN and use of SVM for prediction | LivDet 2015 | Avg. Accuracy = 93.745%93.745% |
| Nogueira et al. [35] | Transfer learning using VGG network | LivDet 2015 | Avg.Accuracy = 95.5%95.5% |
| Jung et al. [38] | Liveness detection of probe fingerprint using template fingerprint through two sequential custom CNNs | LivDet 2015 | Avg. Accuracy = 96.99%96.99% |
| Chugh et al. [42] | Minutiae-centered local patch extraction and detection through MobileNet | LivDet 2011-2015 | ACE = 1.48%1.48% (LivDet 2015) |
| Zhang et al. [41] | Slim-ResCNN and patch extraction via center of gravity | LivDet 2017 | Avg. Accuracy = 95.25%95.25% |
| Chugh et al. [44] | Style transfer between known spoof materials to generate synthetic data for network training | LivDet 2017 | Avg. Accuracy = 95.88%95.88% |
| Liu et al. [31] | Fusion of global and local spoofness score and patch extraction using Grad-CAM during inference | LivDet 2017 | TDR = 91.19%91.19% @FDR = 1%1% |
| Proposed Approach | Ensemble of CAM-guided models generated from a pre-trained CNN | LivDet 2015 | Avg. Accuracy = 97.94% |
This entry is adapted from the peer-reviewed paper 10.3390/s24010187
This entry is offline, you can click here to edit this entry!