Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Against the backdrop of ongoing urbanization, issues such as traffic congestion and accidents are assuming heightened prominence, necessitating urgent and practical interventions to enhance the efficiency and safety of transportation systems. A paramount challenge lies in realizing real-time vehicle monitoring, flow management, and traffic safety control within the transportation infrastructure to mitigate congestion, optimize road utilization, and curb traffic accidents.
- vehicle inspection
- YOLOv7
- deep learning
- attention mechanism
1. Introduction
An intelligent transportation system (ITS) represents a crucial form of technology that efficiently addresses common traffic issues and enhances overall traffic safety [1]. It can be divided into four aspects: reducing travel time, ensuring traffic safety, relieving traffic congestion, and reducing traffic pollution. The ITS has the undeniable potential to ensure safer and smoother traffic on the road [2].
As the global population continues to grow and urbanization accelerates, problems such as road congestion and increased pollution emissions are becoming more serious, and the need for intelligent transportation is becoming more and more urgent. According to market monitoring data, the global intelligent transport market is expected to exceed USD 250 billion by 2025 [3]. The intelligent transportation industry concentration is relatively low, and the financial strength and scale of enterprises in the same industry are generally small. The market competition is also mainly concentrated in a certain regional scope and a small number of enterprises. The emerging Internet and IT giants having cross-border access to the intelligent transportation industry will greatly impact the competition and development of the industry; moreover, it is generally expected that the market concentration of the intelligent transportation industry will further increase in the future.
Ultimately, traffic congestion results from disruptions to the typical flow of vehicles, particularly those moving in a straight direction. The pivotal factor contributing to these disruptions is the alteration of traffic light signals [4], significantly hindering most vehicles’ smooth operation. Traffic congestion is generated precisely because the traffic light signals are not set up reasonably. Traffic signals are a silent commander on the highway, playing an irreplaceable role in traffic safety to improve driving efficiency and ensure the lack of traffic congestion; however, it is often unsatisfactory.
2. Breif Introduction of YOLOv7
2.1. YOLOv7 Object Detection Algorithm
As we know, the YOLOv7 series has eight variants: YOLOv7-tiny, YOLOv7, YOLOv7-W6, YOLOv7-X, YOLOv7-E6, YOLOv7-E6E, and other two models which use leaky ReLU and SiLU as the activation function of the model. YOLOv7 contains four modules: input, backbone, head, and neck.
2.1.1. Input
The input side of YOLOv7 follows the overall logic of YOLOv5 and does not introduce new tricks. The logic mainly calculates the scaling ratio between the native size of the image and the input size to obtain the scaled image size. It then finally performs adaptive filling to obtain the final input image. After inputting the image into the model, it is normalized and converted into many layers of 640×640×3640×640×3 images, and the processed image is fed into the backbone later.
2.1.2. Backbone
In YOLOv7, the primary function of the backbone network is to extract features from the input image. Feature extraction is a critical step that transforms the original image into a series of feature maps with high-level semantic information that will be used in subsequent target detection tasks.
2.1.3. Neck
The neck acts as a bridge between the backbone and head modules. The neck plays a crucial role in target detection. It is used for multi-scale feature fusion and further feature processing. Therefore, one of the main functions of the neck is to fuse feature maps from different backbone network layers. Since the backbone network usually includes multiple feature maps from different layers, the neck fuses these feature maps so that the model can simultaneously process information at multiple scales. This is important for detecting targets of different sizes.
2.1.4. Head
The detection header of the target detection model is a vital component of the entire YOLOv7 architecture and is responsible for generating the final target detection results. The detailed functions of the detection head in YOLOv7 are below:
-
Bounding Box RegressionThe target’s position in the input image is usually represented as the bounding box coordinates. For each detection box, the header generates four values representing the coordinates of the bounding box’s upper left and lower right corners.
-
Class ClassificationAnother critical function is to categorize the detected targets. The detection header generates a category probability distribution for each detection frame, indicating the probability that the target belongs to each possible category. Usually, the model selects the category with the highest probability as the predicted category.
-
Object Confidence EstimationIn addition to location and category, the detection header generates a target confidence score, which indicates the model’s confidence in whether each bounding box contains a valid target. This score is typically used to filter out detections with high confidence.
-
Other function
In multi-scale processing for multi-scale target detection, the detection head needs to be able to process information from different layers and sizes of feature maps. It is responsible for merging this information to detect small and large targets. Activation functions: the detection head usually includes activation functions for classification and regression tasks, such as sigmoid for confidence score generation and softmax for category probability calculation. For loss function calculation, the detection header is also responsible for computing loss functions for the target detection task. These loss functions typically include location regression loss, category classification loss, and confidence loss. These loss functions are used to train the model to optimize target detection accuracy. The detailed framework of the YOLOv7 is in Figure 1 below.
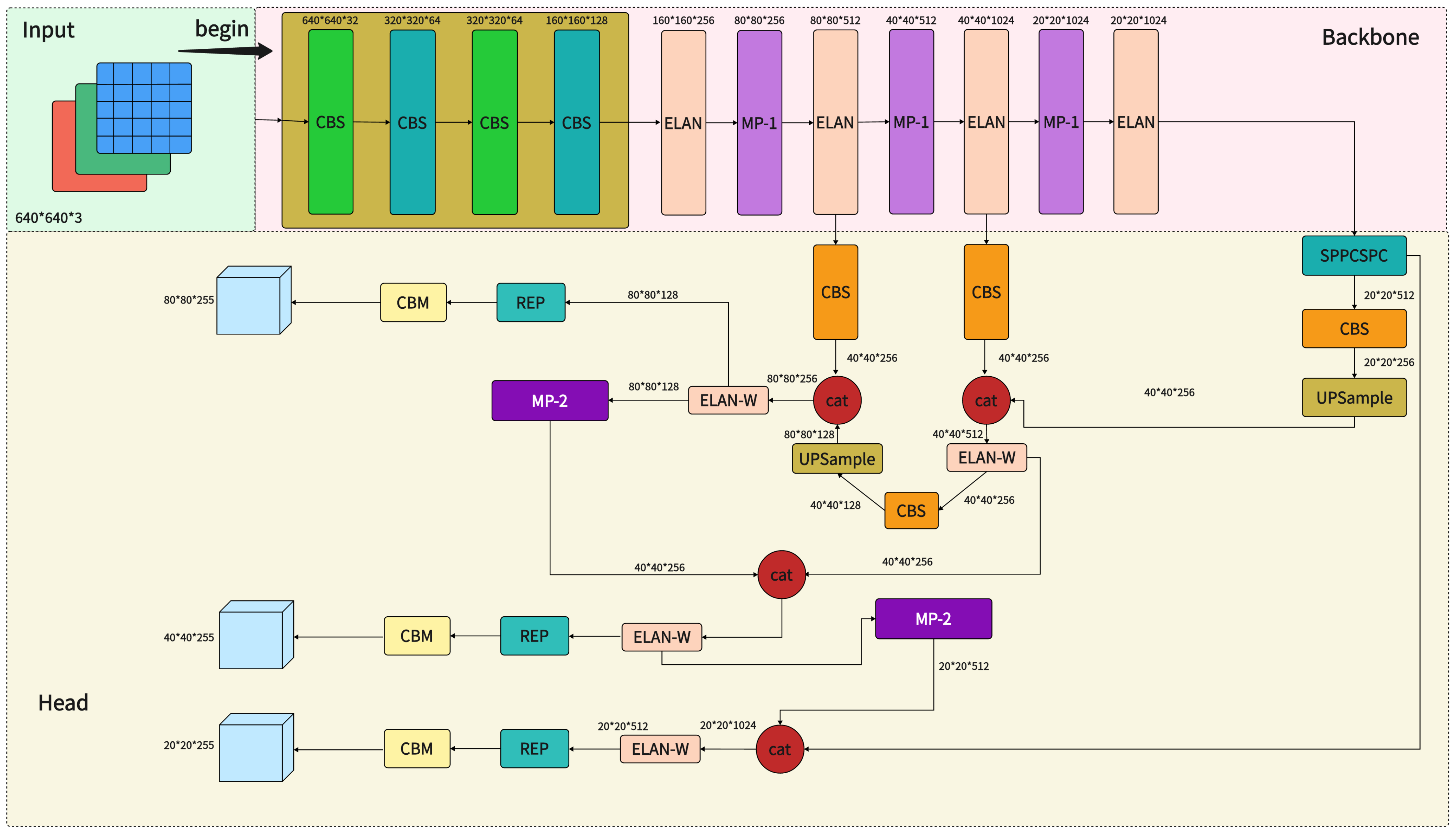
Figure 1. YOLOv7 modeling framework.
This entry is adapted from the peer-reviewed paper 10.3390/app132413052
References
- Dimitrakopoulos, G.; Demestichas, P. Intelligent Transportation Systems. IEEE Veh. Technol. Mag. 2010, 3, 77–84.
- Zeng, Y. Optimal Control and Application of Traffic Light Timing Based on Fuzzy Control. Master’s Thesis, Changsha University of Technology, Changsha, China, 2020.
- Issues Report: Smart Transportation Market. Manufacturing Close-Up. 2020. Available online: https://www.researchandmarkets.com/ (accessed on 26 October 2023).
- Cao, Z.W. Research on highway congestion mitigation technology based on intelligent transport. Intell. Build. Smart City 2023, 168–170.
This entry is offline, you can click here to edit this entry!