Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
在城市化进程不断的背景下,交通拥堵和事故等问题日益突出,需要采取紧急和实际的干预措施,以提高交通系统的效率和安全性。在交通基础设施中实现车辆实时监控、流量管理和交通安全控制,以缓解拥堵、优化道路利用率并遏制交通事故,这是一个最大的挑战。为了应对这一挑战,本研究利用先进的计算机视觉技术,采用深度学习算法进行车辆检测和跟踪。由此产生的识别结果为交通管理领域提供了可操作的见解,通过实时数据分析优化交通流量管理和信号灯控制。该研究证明了本文提出的SE-Lightweight YOLO算法的适用性,在车辆识别方面表现出了95.7%的准确率。作为一项前瞻性研究,该研究有望成为城市交通管理的关键参考,为未来更高效、更安全、更精简的交通系统奠定基础。
为了解决车辆类型识别中现有的车辆检测问题,需要提高识别和检测精度,同时解决检测速度慢等问题。本文在YOLOv7框架的基础上进行了创新性修改:在骨干模块中加入了SE注意力传递机制,模型取得了更好的效果,与原来的YOLOv7相比提升了1.2%。同时,将SPPCSPC模块替换为SPPFCSPC模块,增强了模型的特征提取。之后,我们将SE-Lightweight YOLO应用于交通监控领域。这可以帮助与交通相关的人员进行交通监控,并有助于创建交通大数据。因此,这项研究具有良好的应用前景。
- vehicle inspection
- YOLOv7
- deep learning
- attention mechanism
1. Introduction
An intelligent transportation system (ITS) represents a crucial form of technology that efficiently addresses common traffic issues and enhances overall traffic safety [1]. It can be divided into four aspects: reducing travel time, ensuring traffic safety, relieving traffic congestion, and reducing traffic pollution. The ITS has the undeniable potential to ensure safer and smoother traffic on the road [2].
As the global population continues to grow and urbanization accelerates, problems such as road congestion and increased pollution emissions are becoming more serious, and the need for intelligent transportation is becoming more and more urgent. According to market monitoring data, the global intelligent transport market is expected to exceed USD 250 billion by 2025 [3]. The intelligent transportation industry concentration is relatively low, and the financial strength and scale of enterprises in the same industry are generally small. The market competition is also mainly concentrated in a certain regional scope and a small number of enterprises. The emerging Internet and IT giants having cross-border access to the intelligent transportation industry will greatly impact the competition and development of the industry; moreover, it is generally expected that the market concentration of the intelligent transportation industry will further increase in the future.
Ultimately, traffic congestion results from disruptions to the typical flow of vehicles, particularly those moving in a straight direction. The pivotal factor contributing to these disruptions is the alteration of traffic light signals [4], significantly hindering most vehicles’ smooth operation. Traffic congestion is generated precisely because the traffic light signals are not set up reasonably. Traffic signals are a silent commander on the highway, playing an irreplaceable role in traffic safety to improve driving efficiency and ensure the lack of traffic congestion; however, it is often unsatisfactory.
2. Breif Introduction of YOLOv7
2.1. YOLOv7 Object Detection Algorithm
As we know, the YOLOv7 series has eight variants: YOLOv7-tiny, YOLOv7, YOLOv7-W6, YOLOv7-X, YOLOv7-E6, YOLOv7-E6E, and other two models which use leaky ReLU and SiLU as the activation function of the model. YOLOv7 contains four modules: input, backbone, head, and neck.
2.1.1. Input
The input side of YOLOv7 follows the overall logic of YOLOv5 and does not introduce new tricks. The logic mainly calculates the scaling ratio between the native size of the image and the input size to obtain the scaled image size. It then finally performs adaptive filling to obtain the final input image. After inputting the image into the model, it is normalized and converted into many layers of 640×640×3640×640×3 images, and the processed image is fed into the backbone later.
2.1.2. Backbone
In YOLOv7, the primary function of the backbone network is to extract features from the input image. Feature extraction is a critical step that transforms the original image into a series of feature maps with high-level semantic information that will be used in subsequent target detection tasks.
2.1.3. Neck
The neck acts as a bridge between the backbone and head modules. The neck plays a crucial role in target detection. It is used for multi-scale feature fusion and further feature processing. Therefore, one of the main functions of the neck is to fuse feature maps from different backbone network layers. Since the backbone network usually includes multiple feature maps from different layers, the neck fuses these feature maps so that the model can simultaneously process information at multiple scales. This is important for detecting targets of different sizes.
2.1.4. Head
The detection header of the target detection model is a vital component of the entire YOLOv7 architecture and is responsible for generating the final target detection results. The detailed functions of the detection head in YOLOv7 are below:
-
Bounding Box RegressionThe target’s position in the input image is usually represented as the bounding box coordinates. For each detection box, the header generates four values representing the coordinates of the bounding box’s upper left and lower right corners.
-
Class ClassificationAnother critical function is to categorize the detected targets. The detection header generates a category probability distribution for each detection frame, indicating the probability that the target belongs to each possible category. Usually, the model selects the category with the highest probability as the predicted category.
-
Object Confidence EstimationIn addition to location and category, the detection header generates a target confidence score, which indicates the model’s confidence in whether each bounding box contains a valid target. This score is typically used to filter out detections with high confidence.
-
Other function
In multi-scale processing for multi-scale target detection, the detection head needs to be able to process information from different layers and sizes of feature maps. It is responsible for merging this information to detect small and large targets. Activation functions: the detection head usually includes activation functions for classification and regression tasks, such as sigmoid for confidence score generation and softmax for category probability calculation. For loss function calculation, the detection header is also responsible for computing loss functions for the target detection task. These loss functions typically include location regression loss, category classification loss, and confidence loss. These loss functions are used to train the model to optimize target detection accuracy. The detailed framework of the YOLOv7 is in Figure 1 below.
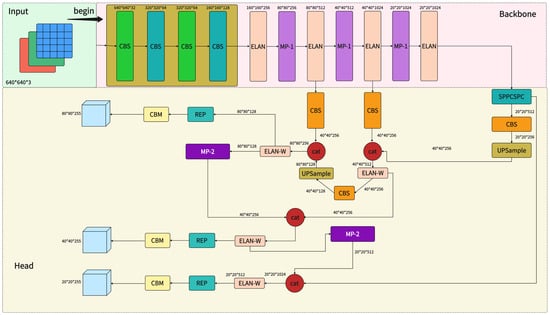
Figure 1. YOLOv7 modeling framework.
3. 用于车辆检查的YOLO检测精度更高
在对车辆识别相关论文进行综述后发现,相关领域需要有更深入的研究。Wang等[7]提出了YOLOv7模型来吸引目标检测领域。Li等人提出了用于遥感的RSI-YOLO(一种改进的YOLO)[8]。他们在原始模型中添加了CBAM注意力机制。Yang等[9]提出了一种改进的YOLOv5,用于弱势道路使用者检测。他们结合了完全交集联合损失 (CIoU-Loss) 和距离交集联合非极大值抑制 (DIoUNMS) 来提高模型的收敛速度。然而,由于收敛速度快,他们还没有考虑模型不稳定的可能性,因此没有实际应用。Sang等[10]提出了一种基于YOLOv2的新型车辆检测模型YOLOv2_Vehicle;他们使用 K-Means++ 聚类算法对训练模型上的车辆边界框进行聚类。虽然其准确率达到94.78%,但数据集视角单一,可能不具备相应的应用价值。Wang等[11]表示VV-YOLO模型的精度为90.68%,可能还有更大的改进空间。Song等提出了TSR-YOLO模型来检测中国交通标志[12],其mAP为92.77%。Wu等人提出了YOLOv3-spp模型来检测不同类型的车辆[13]。由于该模型没有添加注意力机制,因此特征提取能力可能更重要,可以更好地处理检测小目标和复杂背景。He等[14]提出了SPP模块,该模块有效避免了对图像区域进行裁剪和缩放操作时导致的图像失真问题,解决了使用卷积神经网络进行图相关的重复特征提取问题,显著提高了候选帧的生成速度,节省了计算成本。Wang等人构思了一种基于模型的YOLO来检测海上无人机数据[15];模型精度可达92.7%,但精度仍有提升潜力。邱等人提出了一种名为YOLO-GNS[16]的算法,该算法引入了单级无头(SSH)上下文结构,同时用线性变换取代了GhostNet的复杂卷积。但是,该算法的精度仍有更大的改进空间。NAFISEH ZAREI等[17]制作了一种名为YOLO-Rec的模型来检测车辆,该模型的精度为94%。但是,他们应该考虑参数的规模,这可能会导致模型效率低下。Liao等[18]提出了Eagle-YOLO模型,该模型改进了IoU,提高了损失函数的收敛速度。然而,仅与无人机相结合的场景应用由于视点差异显著,无法迁移到红绿灯交通领域。Li等[19]设计了一种RES-YOLO;该模型的识别类型单一,应用价值不高。Daniel Padilla Carrasco等[20]使用多层神经网络对YOLO进行了改进。他们提出了一个T-YOLO模型,但应用场景只针对停车场车辆,识别类别过于同质化。此外,许多研究人员s[21,22,23,24,25,26,27]与通用识别算法改进相关的工作也存在少量的识别场景,否则,场景应用被认为不适合在交通路口领域。由于一些研究是基于无人驾驶汽车的视角进行的[28,29,30,31],而不是与交通信号灯的实际交叉路口,因此在训练视角方面存在显着差异。此外,一些研究者专注于提取特征,而没有进一步[32,33,34]将其推广到特定的应用场景中,形成其应用价值,这属于特定环节的改进,并没有成为一个系统。
This entry is adapted from the peer-reviewed paper 10.3390/app132413052
This entry is offline, you can click here to edit this entry!