Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Subjects:
Others
Sensor Data Fusion (SDT) algorithms and methods have been utilised in many applications ranging from automobiles to healthcare systems. They can be used to design a redundant, reliable, and complementary system with the intent of enhancing the system’s performance. SDT can be multifaceted, involving many representations such as pixels, features, signals, and symbols.
- sensing solution
- thermal sensor
- Radar sensor
- sensor fusion
- data mining
- in-home
1. Introduction
Sensor Data Fusion (SDT) is the combination of datasets from homogeneous or heterogeneous sensors in order to produce a complementary, cooperative or competitive outcome [1]. Data from multiple sensors can also be fused for better accuracy and reliability [2]. Processes involved in SDT depend primarily on the type of data and algorithms. The processes typically include data integration, aggregation, filtering, estimation, and time synchronisation [1].
1.1. Sensor Data Fusion Architectures
SDT architectures can be categorised into three broad groups, namely centralised, distributed, and hybrid architectures. The centralised architecture is often applied when dealing with homogeneous sensing solutions (SSs) [3]. It involves time-based synchronisation, correction, and transformation of all raw sensing data for central processing. Other steps include data merging and association, updating, and filtering, as presented in Figure 1 [4].
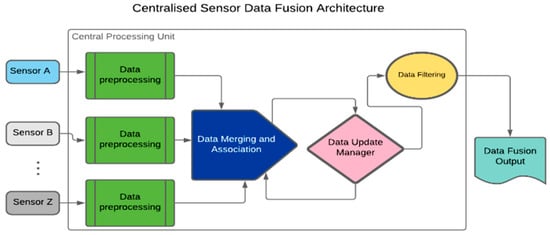
Figure 1. Centralised Sensor Data Fusion architecture outlining the arrangement of processes.
In Figure 1, sensor data are pre-processed in the Central Processing Unit (CPU). The pre-processing procedures entail data cleaning and alignment. The data algorithm requires sub-processes such as data integration, aggregation, and association. Moreover, a Data Update Manager (DUM) algorithm keeps a trail of changes in the output’s status. A DUM is easily implemented in a centralised architecture because of the availability of all raw data in the CPU. Filtering and output prediction follow the data merging and association.
In a distributed SDT architecture, data pre-processing for each sensor takes place separately before the actual fusion process, as presented in Figure 2. Unlike with the centralised architecture, gating, association, local track management, filtering, and prediction are performed locally for each sensor before the fusion of the local tracks (Figure 2) [5]. This architecture is best suited for heterogeneous sensors with dissimilar data frames such as datasets from infrared and Radar sensors [6]. Data filtering for each sensor associated with the distributed SDT architecture can be performed by a Kalman Filter (KF) and extended KF [7].
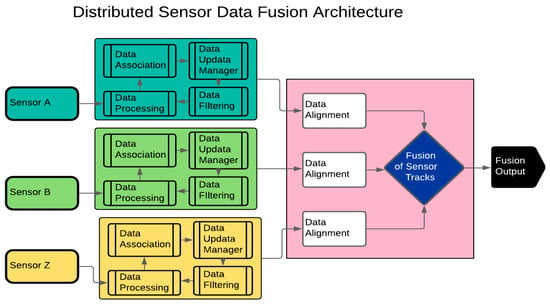
Figure 2. Distributed Sensor Data Fusion architecture showing pre-processing of sensors’ data before filtering and fusion of sensors’ tracks.
The hybrid SDT architecture unifies the attributes of centralised and distributed architectures. Their capabilities depend on computational workload, communication, and accuracy requirements. The hybrid SDT also has centralised architecture characteristics, such as accurate data association, data tracking, and direct logic implementation. Nevertheless, it is complex and requires high data transfer between the central and local trackers compared with the centralised and distributed architectures. SDT architectures can be implemented using machine learning (ML) and data mining (DM) algorithms.
1.2. Data Mining Concepts
DM is an iterative process for exploratory analysis of unstructured, multi-feature, and varied datasets. It involves the use of machine learning, deep learning, and statistical algorithms to determine patterns, clusters, and classes in a dataset [8]. The two standard analyses with the use of DM tools are descriptive and predictive [9]. Whilst descriptive analysis seeks to identify patterns in a dataset, predictive analysis uses some variables in a dataset to envisage some undefined variables [10].
DM can also be categorised into tasks, models, and methods. Tasks-based DM seeks to discover rules, perform predictive and descriptive modelling, and retrieve contents of interest. DM methods include clustering, classification, association, and time-series analysis [11,12]. Clustering is often used in descriptive research, while classification is always associated with predictive analysis [10].
In DM, there is a slight distinction between classification and clustering. Classification is a supervised machine learning approach to group datasets into predefined classes or labels. On the other hand, clustering involves unlabelled data grouping based on similarities of instances such as inherent characteristics of the datasets [10]. Table 1 presents an overview of classification and clustering techniques.
Table 1. Classification and clustering techniques in data mining.
| Classification Techniques | Application of Classification Techniques | Clustering Techniques | Application of Clustering Techniques |
|---|---|---|---|
| Neural Network | E.g., stock market prediction [13] | Partition-based | E.g., medical datasets analysis [14] |
| Decision Tree | E.g., Banking and finance [15] | Model-based | E.g., multivariate Gaussian mixture model [16] |
| Support Vector Machine | E.g., big data analysis [17] | Grid-based | E.g., large-scale computation [18] |
| Association-based | E.g., high dimensional problems [19] | Density-based | Applications with noise. E.g., DBSCAN [20] |
| Bayesian | E.g., retrosynthesis [21] | Hierarchy-based | E.g., Mood and abnormal activity prediction [22,23] |
Data clustering techniques such as partition-based, model-based, grid-based, density-based and hierarchical clustering can be used for data grouping [8]. Whilst the density-based approach is centred on the discovery of non-linear structures in datasets, model- and grid-based methods utilise neural networks and grids creation, respectively. The Hierarchical Clustering Technique (HCT) involves the structural representation of datasets as binary trees based on similarities of instances. The HCT also accommodates sub-clusters in nested arrangements. The two main approaches in the HCT are division and agglomeration [24].
The Partitioning Clustering Technique (PCT) groups data by optimising an objective function [8]. The PCT is a non-HCT technique that involves partition iterations to improve the accuracy of formed groups. A popular algorithm in PCT is the K-Means++ Algorithm (KMA) [24,25]. The KMA utilises uncovered characteristics in datasets to improve the similarities of instances. It also reduces data complexities by minimising their variance and noise components [25].
2. Object Detection
Kim et al. [29] proposed a Radar and infrared sensor fusion system for object detection based on a Radar ranging concept, which required the use of a calibrated infrared camera alongside the Levenberg–Marquardt optimisation method. The purpose of using dual sensors in [29] was to compensate for the deficiencies of each sensor used in the experiment. The implementation of the fusion system was performed on a car with magenta and green cross marks as calibrated points positioned at different distances. The performance of this experiment using the fusion of sensor data was rated 13 times better compared with baseline methods. Work in [30] proposed the fusion of LiDAR and vision sensors for a multi-channel environment detection system. The fusion algorithm enabled image calibration to remove distortion. The study indicated improved performance in terms of communication reliability and stability compared with non-fusion-based approaches.
3. Automobile Systems
In automated vehicles with driver assist systems, data from front-facing cameras such as vision, LiDAR, Radar, and infrared sensors are combined for collision avoidance and pedestrian, obstacle, distance, and speed detection [31]. The multi-sensor fusion enhanced the redundancy of measured parameters to improve safety since measurement metrics are inferred from multiple sensors before actions are taken. A multimodal advanced driver assist system simultaneously monitors the driver’s interaction to predict risky behaviours that can result in road accidents [31]. Other LiDAR-based sensor fusion research included the use of vision sensors to enhance environmental visualisation [32].
4. Healthcare Applications
Chen and Wang [33] researched the fusion of an ultrasonic and an infrared sensor using the Support Vector Machine (SVM) learning approach. The study used SDT to improve fall detection accuracy by more than 20% compared with a stand-alone sensor on continuous data acquisition. Kovacs and Nagy [34] investigated the use of an ultrasonic echolocation-based aid for the visually impaired using a mathematical model that allowed the fusion of as many sensors as possible, notwithstanding their positions or formations. Huang et al. [35] proposed the fusion of images from a depth sensor and a hyperspectral camera to improve high-throughput phenotyping. The initial results from the technique indicated more accurate information capable of enhancing the precision of the process. Other studies on the fusion of depth with other SSs can be found in [36,37,38]. The work in [39] involved gait parameters’ measurement of people with Parkinson’s disease, by the fusion of depth and vision sensor systems. An accuracy of more than 90% was obtained in the study. Also, in Kepski and Kwolek [40], data from a body-worn accelerometer was fused with depth maps’ metrics from depth sensors to predict falls in ageing adults. The proposed method was highly efficient and reliable, showing the added advantages of sensor fusion. Work in [41] proposed the fusion of an RGB-depth and millimetre wave Radar sensor to assist the visually impaired. Experimental results from the study indicated the extension of the effective range of the sensors and, more importantly, multiple object detection at different angles.
5. Cluster-Based Analysis
The integration of SDT algorithms with ML and DM models can help predict risky behaviours and accidents [33,42,43,44,45]. Work in [46] discussed the use of Cluster-Based Analysis (CBA) for a data-driven correlation of ageing adults that required hip replacement in Ireland. Experimental results from the study suggested three distinct clusters with respect to patients’ characteristics and care-related issues. In [47], data evaluation using CBA helped in clustering healthcare records such as illness and treatment methods. A combined method, including CBA for user activity recognition in smart homes, was proposed in [48]. Experimental results indicated higher probabilities for activity recognition owing to the use of a combination of a K-pattern and artificial neural network. Work in [49,50,51] proposed the use of the CBA method in health-related data analysis. Experimental results indicated the suitability of the method for pattern identification and recognition in datasets.
This entry is adapted from the peer-reviewed paper 10.3390/s23218661
This entry is offline, you can click here to edit this entry!