Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Deep learning algorithms, renowned for their ability to extract intricate patterns from complex datasets, have proven particularly adept at handling the multifaceted time-series data characteristic of smart city IoT applications. Deep learning architectures model complex relationships through a series of nonlinear layers—the set of nodes of each intermediate layer capturing the corresponding feature representation of the input.
- machine learning
- deep learning
- IoT
- smart cities
- time series
1. Introduction
A smart city is a place where traditional networks and services are improved by utilizing and embracing contemporary technological principles for the benefit of its citizens [1]. Smart cities are being rapidly implemented to accommodate the continuously expanding population in urban cities and provide them with increased living standards [2]. Going beyond the use of digital technologies for better resource use and less emissions, the development of smart cities entails smarter urban transportation networks, more responsive and interactive administration, improved water supply and waste disposal facilities, more efficient building lighting and heating systems, safer public places, and more. To this end, smart cities employ Internet of Things (IoT) devices, such as connected sensors, embedded systems, and smart meters, to collect various measurements at regular intervals (time-series data), which are subsequently analyzed and ultimately used to improve infrastructure and services [3].
Deep learning algorithms [4], renowned for their ability to extract intricate patterns from complex datasets, have proven particularly adept at handling the multifaceted time-series data characteristic of smart city IoT applications. These algorithms are designed to capture the dynamics of multiple time series concurrently and harness interdependencies among these series, resulting in more robust predictions [5]. Consequently, deep learning techniques have found application in various time-series forecasting scenarios across diverse domains, such as retail [6], healthcare [7], biology [8], medicine [9], aviation [10], energy [11], climate [12], automotive industry [13] and finance [14].
Remarkable examples of these technologies in action include Singapore’s Smart Nation Program around traffic-flow forecasting, Beijing’s Environmental Protection Bureau ‘Green Horizon’, the City of Los Angeles’ ‘Predicting What We Breathe’ air-quality forecasting projects, and the United States Department of Energy SunShot initiative around renewable energy forecasting. More specifically, in Singapore, the Land Transport Authority has created a traffic management system powered by AI that analyzes real-time data to optimize traffic flow and alleviate congestion. In Beijing, IBM’s China Research Lab has developed one of the world’s most advanced air-quality forecasting systems, while across multiple cities in the United States, IBM is making renewable energy-demand and supply forecasts.
Beyond their technical implications, the implementation of such technologies brings profound socioeconomic and environmental outcomes for cities and their residents [15]. Indicatively, it can foster economic growth by attracting talented individuals and entrepreneurs, potentially turning cities into innovation hubs, which, in turn, can lead to job creation and increased economic competitiveness [16]. As smart cities become more prosperous through economic growth, healthcare and education become more accessible and more inclusive, which results in more engaged and empowered citizens, contributing to social cohesion and overall well-being [17]. Moreover, AI-driven efficiency improvements in resource management can make cities more environmentally sustainable, addressing global challenges such as climate change [18].
There have been several surveys around deep learning for time-series forecasting, both in theoretical [5] and experimental [19] contexts. Looking at smart cities, deep learning has been used in various domains, but since this is still an emerging application area, only a few surveys have studied the current state-of-the-art models. Many of these, such as [20,21], describe deep learning as part of a broader view of machine learning approaches and examine a limited number of models. Other studies focusing on deep learning methods consider a wide set of data types, such as text and/or images [22,23,24,25], or address tasks beyond forecasting (e.g., classification), thus not providing a comprehensive overview on time-series forecasting in IoT-based smart city applications.
2. Deep Learning Architectures for Multivariate Time-Series Forecasting
Deep learning architectures model complex relationships through a series of nonlinear layers—the set of nodes of each intermediate layer capturing the corresponding feature representation of the input [26]. In a time-series context, these feature representations correspond to relevant temporal information up to that point in time, encoded into some latent variable at each step. In the final layer, the very last encoding is used to make a forecast. In this section, the most common types of deep learning building blocks for multivariate time-series forecasting are outlined.
2.1. Recurrent Neural Networks
Recurrent neural networks have a long and well-established history when it comes to time-series forecasting [27] that continues to date. The core building block of RNNs is the RNN cells that essentially act as an internal memory state. Their purpose is to maintain a condensed summary of past information deemed useful by the network for forecasting future values. At each time step, the network is presented with fresh observations, and cells are updated accordingly with new information. The standard structure of an RNN and its unfolded-in-time version are shown in Figure 1. In the case of multivariate time series, the inputs x and outputs t are multidimensional in each of the time steps.
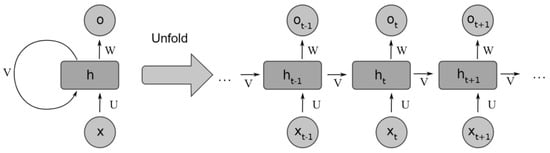
Figure 1. RNN unfolding—adapted from [28].
Older versions of RNNs were notorious for failing to adequately capture long-term dependencies, a problem commonly known as ’exploding and vanishing gradients’ [29]. More specifically, the lack of restriction on their look-back window range meant that the RNNs cells were unable to contain all the relevant information from the beginning of the sequence [30]. The advent of long short-term memory networks (LSTMs) [31] and other closely related variants, such as the gated recurrent units (GRUs [32]), largely alleviated this problem, by allowing the gradients to flow more stably within the network. In Figure 2, the different cells used by the LSTMs and GRUs are displayed.
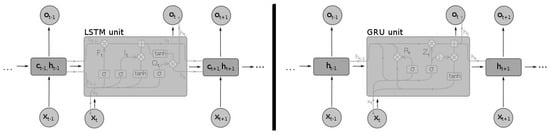
Figure 2. Different recurrent neural network cells: LSTM (left) and GRU (right)—adapted from [33].
Another shortcoming of conventional RNNs was the inability to make use of future time steps. To overcome this limitation, a new type of architecture, bidirectional RNNs (BiRNNs), was proposed by Schuster and Paliwal [34]. The novelty of BiRNNs was that they could be trained in both time directions at the same time, using separate hidden layers for each direction: forward layers and backward layers. Later on, Graves and Schmidhuber [35] introduced the LSTM cell to the BiRNN architecture, creating an improved version: the bidirectional LSTM (BiLSTM). Using the same principles, the bidirectional paradigm can be extended to GRUs to create BiGRU networks. A very common and powerful end-to-end approach to sequence modeling that utilizes LSTMs, GRUs, or their bidirectional versions is the sequence-to-sequence (Seq2seq) or encoder-decoder framework [36]. This framework originally had a lot of success in natural language processing tasks, such as machine translation, but can also be used in time-series prediction [37]. Under this framework, a neural network (the encoder) is used to encode the input data in a fixed-size vector, while another neural network takes the produced fixed-size vector as its own input to produce the target time series. Any of the mentioned RNN variants can act as the encoder or the decoder. Such an architecture can produce an entire target sequence all at once. All these advances and improvements to RNNs have resulted in them being established as the driving force behind many modern state-of-the-art multivariate time-series forecasting architectures, which use them as their main building blocks [38,39,40,41,42].
When utilizing RNNs and their variants, careful attention should be given to their hyperparameter tuning [43], especially in the selection of the number of hidden units, hidden layers, the learning rate, and the batch size. The number of hidden units and layers should align with the data complexity, and the more complex the data, the higher the number of layers and neural networks as a general rule of thumb. Adaptive learning rate techniques are essential to address nonstationarity, while the right batch size can ensure a smoother learning process. Lastly, for such models to thrive, it is important that the length of the input sequences should match the time patterns in it, especially if long-term connections are to be captured.
2.2. Convolutional Neural Networks
Convolutional neural networks were originally used for computer vision tasks. By making strong, but to a great degree correct, assumptions about the nature of images in terms of the stationarity of statistics and locality of pixel dependencies, CNNs are able to learn meaningful relationships and extract powerful representations [44].
CNNs typically consist of a series of convolutional layers followed by pooling layers, with one or more dense layers in the end. Convolutional layers perform a convolution operation of their input series with a filter matrix to construct high-level representations. The purpose of the pooling operation is to reduce the dimensionality of these representations while preserving as much information as possible. In addition, the produced representations are rotationally and positionally invariant. CNNs for time-series data, usually referred to as temporal CNNs and similar to standard/spatial CNNs, make invariance assumptions. In this case, however, such assumptions are about time instead of space, as they maintain the same set of filter weights across each time step. For CNNs to be transferred from the domain of computer vision to time-series forecasting, some modifications are needed [45,46]. A main concern is that the look-back window of CNNs is controlled by and limited by the size of its filter, also known as the receptive field. As a result, choosing the right filter size is crucial for the network’s capability to pick up all the relevant historical information, and finding an optimal size is not an easy task and is usually considered part of the hyperparameter tuning process [46]. Another consideration is related to the leakage of data from the future into the past; in [45], the so-called causal convolutions were developed to make sure that there is no leakage from the future into the past and only past information is used for forecasting. Lastly, to capture long-term temporal dependencies, a combination of very deep networks, augmented with residual layers, along with dilated convolutions, are employed, which are able to maintain very long effective history sizes [46]. An example of a CNN architecture for multivariate time-series forecasting can be seen in Figure 3. Since the number of parameters grows in line with the size of the look-back window, the use of standard convolutional layers can be computationally expensive, especially in cases where strong long-term dependencies are formed. To decrease the computational burden but maintain the desired results, newer architectures [45,47] often employ so-called dilated convolutional layers. Dilated convolutions can be viewed as convolutions of a downsampled version of the lower-level features, making it much less expensive to incorporate information from past time steps. The degree of downsampling is controlled by the dilation rate, applied on a layer basis. Dilated convolutions can, therefore, gradually accumulate information from various time blocks by increasing the dilation rate with each layer, allowing for more efficient utilization of historic information [5].
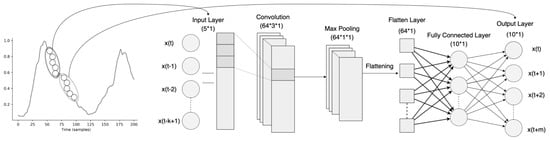
Figure 3. Convolutional neural network architecture for multivariate time-series forecasting—adapted from [48].
When it comes to hyperparameter tuning, focus should be directed towards the alignment of the number of filters, the filter sizes, the number of convolutional layers, and pooling strategies with the inherent patterns of the data [47]. More specifically, the more intricate and diverse the data are, the greater the number of filters and layers needed to capture it. Longer sequences contain more information and context and usually require larger filters to capture broader patterns and dependencies over extended periods. If the data are noisy, then pooling layers can help cut through the noise and improve the model’s focus on the features that matter.
2.3. Attention Mechanism
LSTMs acted to mitigate the problem of vanishing gradients, however, they did not eradicate it. While, in theory, the LSTM memory can hold and preserve information from the previous state, in practice, due to vanishing gradients, the information retained by these networks at the end of a long sequence is deprived of any precise, contextual, or extractable information about preceding states.
This problem was addressed by the attention mechanism [49,50], originally used in transformer architectures for machine translation [51,52,53]. Attention is a technique that helps neural networks focus on the more important parts of the input data and deprioritize the less important ones. Which parts are more relevant is learned by the network through the input data itself and is derived by the context. This is achieved by making all the previous states at any preceding point along the sequence available to the network; through this mechanism the network can access all previous states and weight them according to a learned measure of relevancy, providing relevant information even from the distant past. Outside of natural language processing tasks, attention-based architectures have demonstrated state-of-the-art performance in time-series forecasting [54,55,56]. The two most broadly used attention techniques are dot-product attention and multihead attention. The former calculates attention as the dot product between vectors, while the latter incorporates various attention mechanisms—usually different attention outputs are independently computed and are subsequently concatenated and linearly transformed into the expected dimension. These two different types of attention are shown in Figure 4.
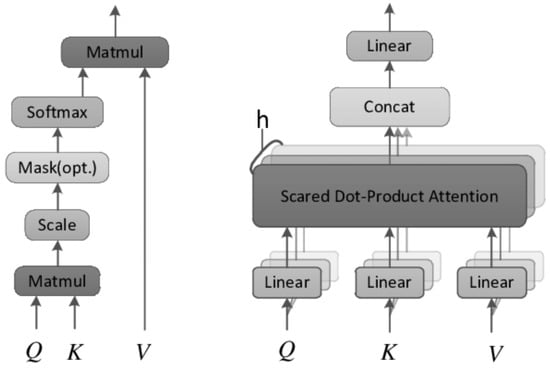
Figure 4. Attention mechanisms: dot-product (left) vs. multihead (right)—adapted from [57].
The choice of hyperparameters in attention models for time-series forecasting can be heavily influenced by the specific characteristics of the time-series data [58]. For instance, the series length can affect the number of attention heads and the attention window size. Longer sequences may require more attention heads to capture various dependencies and a wider attention window to consider longer-term patterns. Seasonality in the data may necessitate specialized attention mechanisms or attention spans to focus on recurring patterns, while nonstationary data may benefit from adaptive attention mechanisms to adapt to changing dynamics. The choice of attention mechanism type may also depend on the data characteristics; self-attention mechanisms like those in transformers are known for their ability to capture complex dependencies and intricate patterns.
2.4. Graph Neural Networks
In some cases, time-series problems are challenging because of the complex temporal and spatial dependencies. RNNs and temporal CNNs are capable of modeling the former, but they cannot solve the latter. Normal CNNs, to some degree, alleviate the problem by modeling the local spatial information; however, they are limited to cases of Euclidean structure data. Graph neural networks (GNNs), designed to exploit the properties of non-Euclidean structures, are capable of capturing the underlying spatial dependencies, offering a new perspective on approaching such forecasting problems, e.g., traffic-flow forecasting [59].
GNN-based approaches are generally divided into two categories: spectral and nonspectral approaches. For spectral approaches to function, a well-defined graph structure is required [60]. Therefore, a GNN trained on a specific structure that defines the relationships among the different variables cannot be directly applied to a graph with a different structure. On the other hand, nonspectral approaches define convolutions directly on the graph, operating on groups of spatially close neighbors; this technique operates by sampling a fixed-size neighborhood of each node, and then performing some aggregation function over it [61]. In any case, variables from multivariate time series can then be considered as nodes in a graph, where the state of a node depends on the states of its neighbors, forming latent spatial relationships.
To capture the spatial dependencies among their nodes, GNNs use a different type of convolution operation, called graph convolution [60]. The basic idea of graph convolutions is similar to that of traditional convolutions, often used in images, where a filter is applied to a local region of an image and produces a new value for each pixel in that region. Similarly, graph convolutions apply a filter to a local neighborhood of nodes in the graph, and a new value is computed for each node based on the attributes of its neighbors. This way, node representation is updated by aggregating information from their neighbors. Graph convolutions are typically implemented using some message-passing scheme that propagates information through the graph [62]. In Figure 5, such convolution operations on different nodes of a graph are exemplified.
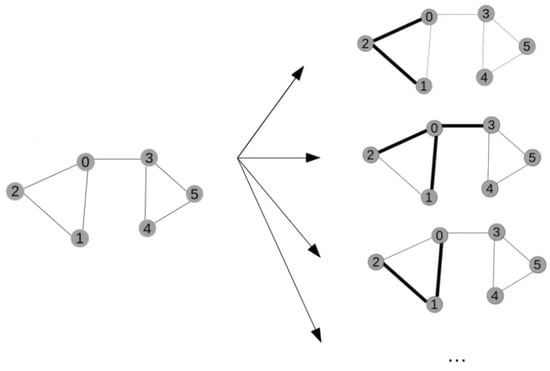
Figure 5. Graph convolutions applied to different nodes of a graph. Each node is denoted by a number (0–5).
Regarding the temporal dependencies, some GNN-based architectures may still use some type of RNN or temporal CNN to learn the temporal dependencies [63,64], while others have tried to jointly model both the intraseries temporal patterns and interseries correlations [65]. A new type of GNN, which incorporates the attention mechanism, called a graph attention network (GAT), was introduced by Veličković et al. [61]. The idea is to represent each node in the graph as a weighted average of the nonlinearly transformed features of only the neighboring nodes, using the attention coefficients. As a result, different importances are assigned to different nodes within a neighborhood, and at the same time, the need to know the entire graph structure upfront is eliminated. Even though recent advances in GNNs have demonstrated great potential by achieving state-of-the-art performance in various tasks, they have not been applied to time-series forecasting tasks to such a large extent as their RNN or CNN counterparts [66].
When applying GNNs to time-series data structured as graphs, key considerations captured by hyperparameters include defining node and edge representations, determining the number of message-passing layers to handle temporal dependencies, choosing aggregation functions for gathering information from neighboring nodes, and addressing dynamic graph structures for evolving time series [67]. More specifically, while simpler GNN architectures with fewer layers can suffice for short sequences or stable trends, longer sequences often require deeper GNNs to capture extended dependencies. Highly variable data patterns may demand more complex GNN structures, while the presence of strong seasonality may warrant specialized aggregation functions. Finally, the graph structure should mirror the relationships between variables in the time series, e.g., directed, weighted, or otherwise, to enable effective information propagation across the network.
2.5. Hybrid Approaches
Hybrid approaches combine different deep learning architectures, bringing together the benefits of each. Generally speaking, architectures integrating more than one learning algorithm have been shown to produce methods of increased robustness and predictive power, compared to single-model architectures [68]. Their increased robustness stems from the fact that, by using multiple types of neural networks, hybrids are less prone to noise and missing data, which helps them learn more generalizable representations of the data. At the same time, the combination of different types of neural networks increases the flexibility of the model, allowing it to be more easily tailored to the specific characteristics and patterns of the given time-series data [69]. A common approach in deep learning hybrids for time-series forecasting has been to combine models that are good at feature extraction such as CNNs or autoencoders, with models capable of learning temporal dependencies among those features, such as LSTMS, GRUs, or BiLSTMs. In Figure 6, a commonly used CNN–LSTM hybrid architecture is depicted.
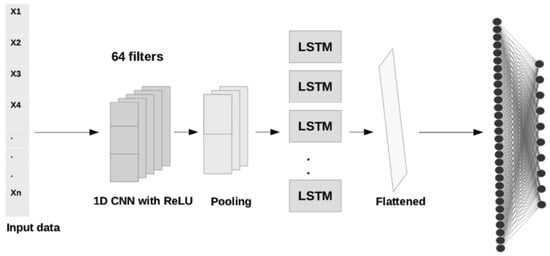
Figure 6. A simple CNN–LSTM hybrid architecture—adapted from [70].
Despite their advantages, hybrid models are often more computationally intensive, leading to longer training times and demanding more resources. Additionally, hyperparameter tuning becomes more challenging due to the increased complexity and the need to optimize settings for multiple components. They should, therefore, be considered mostly in cases where simpler models do not perform adequately.
This entry is adapted from the peer-reviewed paper 10.3390/smartcities6050114
This entry is offline, you can click here to edit this entry!