After the pandemic situation created by the novel coronavirus, it has become a necessity to encode the local language, conventionally written in pen and paper, in an electronic format. Optical character recognition (OCR) systems convert handwritten documents to a computer-editable digital form. Optical character recognition (OCR) converts pdf files, scanned documents, images containing text and printed and handwritten documents into editable electronic documents. OCR can be implemented for printed character recognition and handwritten character recognition. The latter is further categorized into online and offline recognition systems. Optical Character Recognition system for Malayalam handwritten documents has become an open research area. A major hindrance for this research is the unavailability of a benchmark database. Therefore, a new database of 402 Malayalam handwritten document images and ground truth images of 7535 text lines is developed for the implementation of the proposed technique. This paper proposes a technique for extracting text lines from handwritten documents in Malayalam language, specifically based on the handwriting of the writer. Text lines are extracted based on horizontal and vertical projection values, size of the handwritten characters, height of the text lines and the curved nature of Malayalam alphabets.
- handwritten document
- Malayalam
- text line extraction
1. Introduction
2. Text Line Segmentation from Malayalam Documents
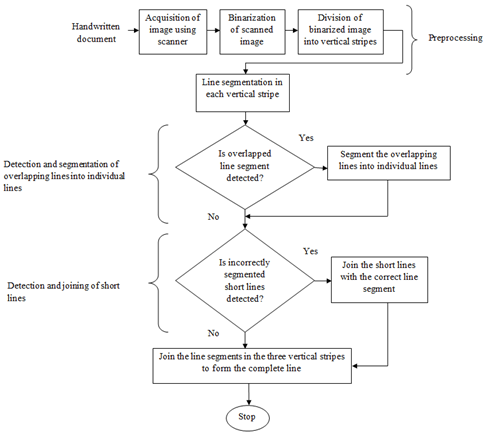
Figure 2. Flow of the processes involved in text line extraction of Malayalam handwritten document.
2.1. Database for Malyalam handwritten document
The database is created by collecting Malayalam handwritten documents from professionals, under graduate and post graduate students in the age group between 18 to 45. The articles for the manuscript is collected from leading Malayalam newspapers and text books which cover all the alphabets, consonant diacritics and conjunct consonants in Malayalam language. Initially a manuscript of the article is written in A4 size paper without any constrain on the pen, and script of Malayalam language. Even now, people write using a mix of old Malayalam script and new Malayalam script. 402 handwritten document collected from 200 people is scanned using the flatbed scanner Epson L310 with dpi 200.
A sample image from the newly developed LIPI database is shown in Figure 3 and the image after binarization is shown in Figure 4. The ground truth images created for text lines 1 and 4 in the image of Figure 4 are shown in Figure 5a and Figure 5b respectively. Ground truth images are created for each of the 7535 text lines in the handwritten document images. As it is shown in Figure 5a and Figure 5b, the exact position of the text lines in the document images is retained in the ground truth images.

Figure 3. Sample image of Malayalam handwritten document from LIPI database.

Figure 4. Sample image converted to binary.


Figure 5. (a) Ground truth of the first text line in the image shown in Figure 4; (b) Ground truth of fifth text line in the image shown in Figure 4.
Figure 6 shows the result of text lines extracted from the document image shown in Figure 4.

Figure 6. Text lines extracted from handwritten document image in Figure 3.
3. Conclusions
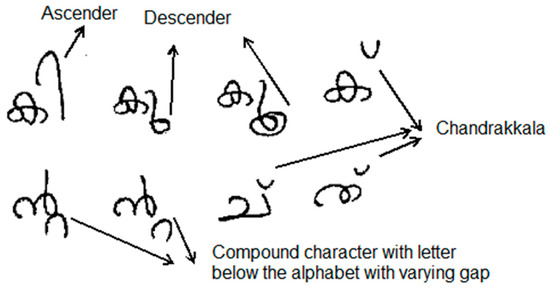
The diverse handwriting styles of the people make text line extraction from handwritten documents a difficult task. In this paper, a novel method based on the size variations of the written alphabets due to different handwriting styles is proposed to extract the text lines from handwritten Malayalam documents. Various thresholds are developed for performing text line extraction by measuring the average height and width of written characters in a document image. Therefore, these thresholds vary dynamically with handwriting styles. In the proposed technique horizontal projection (HP) values are used to find the positions to perform text line extraction. The two problems encountered while using horizontal projection values are, the extracted line segment with overlapped multiple lines, the varying gaps due to different handwriting styles between two characters when one character is written below another resulting in segmentation of such lines into two separate lines. These are addressed and solved effectively using the proposed method. 85.507% of the extracted text lines from the newly created LIPI database of Malayalam handwritten document images perfectly matches with the ground truth lines when evaluated using the metric MatchScore. Also, the technique proposed in this paper outperforms the language independent text line extraction algorithms like A* Path Planning and Piece-wise Painting algorithm on the LIPI database. Due to the unavailability of Malayalam handwritten document image database, a new database of 402 images is created and is named as LIPI. Another major contribution is the ground truth images created for the 7535 text lines in the document images. The proposed method is an initial step in digitizing Malayalam handwritten document which will be highly beneficial for the common people to share handwritten documents in their local language.
This entry is adapted from the peer-reviewed paper 10.3390/app13179712
References
- Liritzis, I.; Iliopoulos, I.; Andronache, I.; Kokkaliari, M.; Xanthopoulou, V. Novel Archaeometrical and Historical Transdisciplinary Investigation of Early 19th Century Hellenic Manuscript Regarding Initiation to Secret “Philike Hetaireia”. Mediterr. Archaeol. Archaeom. 2023, 23, 135–164.
- Andronache, I.; Liritzis, I.; Jelinek, H.F. Fractal Algorithms and RGB Image Processing in Scribal and Ink Identification on an 1819 Secret Initiation Manuscript to the “Philike Hetaereia”. Sci. Rep. 2023, 13, 1735.