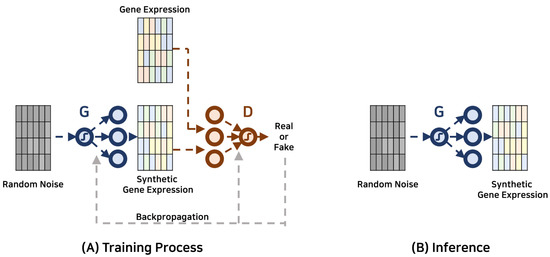
A generative adversarial network (GAN) is essentially a two-player game composed of a generator and a discriminator. The generator’s role is to create synthetic data, while the discriminator’s task is to distinguish between real and generated data. During the training process, the generator strives to produce data that the discriminator cannot differentiate from the real data, whereas the discriminator continually improves its ability to distinguish real from generated data. This adversarial training regimen imbues GANs with the capability to model complex data distributions and produce high-quality synthetic data. Notably, their application to gene expression data systems is a fascinating and rapidly growing focus area.
- generative adversarial networks
- gene expression data
- deep learning
- genomic data
- artificial intelligence
1. Introduction
| Author | Contributions |
|---|---|
| Yu et al. [22] | Developed MichiGAN, a network combining VAEs and GANs to generate disentangled single-cell gene expression data. |
| Yelmen et al. [23] | Utilized GANs and RBMs to generate artificial human genomes enhancing data imputation quality for low frequency alleles. |
| Hazra et al. [24] | Used GANs to create synthetic nucleic acid sequences of the cat genome, achieving high correlation with original data. |
| Zrimec et al. [25] | Prototyped ExpressionGAN, generating synthetic regulatory DNA with targeted mRNA levels, exceeding natural controls in expression. |
| Ahmed et al. [26] | Introduced omicsGAN, integrating multi-omics data, enhancing predictive signals for cancer outcomes in synthetic data. |
| Vinas et al. [27] | Utilized a conditional GAN for generating realistic transcriptomics data preserving tissue- and cancer-specific properties. |
| Marouf et al. [28] | Developed cscGAN, generating realistic single-cell RNA-seq data, enhancing marker gene detection and classifier reliability. |
| Chaudhari et al. [29] | Developed MG-GAN to augment gene expression data, enhancing cancer classification accuracy significantly. |
| Kwon et al. [30] | Used GAN for augmenting samples, enhancing prediction of cancer stages significantly. |
| Mendez-Lucio et al. [31] | Introduced GAN model generating molecules inducing desired transcriptomic profile, a promising approach to drug discovery. |
| Chen et al. [32] | Developed Tox-GAN, generating gene activities and expression profiles, aiding in chemical-based read-across. |
2. Recent Studies: 2019–2023
3. Trends, Challenges, and Future Directions in Recent Studies
This entry is adapted from the peer-reviewed paper 10.3390/math11143055
References
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. OpenAI Technical Report. 2019. Available online: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (accessed on 15 May 2023).
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901.
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. OpenAI Technical Report. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 15 May 2023).
- Lee, M. A Mathematical Investigation of Hallucination and Creativity in GPT Models. Mathematics 2023, 11, 2320.
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; et al. Photorealistic text-to-image diffusion models with deep language understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36479–36494.
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794.
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695.
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851.
- Yeom, T.; Lee, M. DuDGAN: Improving Class-Conditional GANs via Dual-Diffusion. arXiv 2023, arXiv:2305.14849.
- Jabbar, A.; Li, X.; Omar, B. A survey on generative adversarial networks: Variants, applications, and training. ACM Comput. Surv. CSUR 2021, 54, 1–49.
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative adversarial network: An overview of theory and applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004.
- Ko, K.; Lee, M. ZIGNeRF: Zero-shot 3D Scene Representation with Invertible Generative Neural Radiance Fields. arXiv 2023, arXiv:2306.02741.
- Yinka-Banjo, C.; Ugot, O.A. A review of generative adversarial networks and its application in cybersecurity. Artif. Intell. Rev. 2020, 53, 1721–1736.
- Cai, Z.; Xiong, Z.; Xu, H.; Wang, P.; Li, W.; Pan, Y. Generative adversarial networks: A survey toward private and secure applications. ACM Comput. Surv. CSUR 2021, 54, 1–38.
- Chen, Y.; Yang, X.H.; Wei, Z.; Heidari, A.A.; Zheng, N.; Li, Z.; Chen, H.; Hu, H.; Zhou, Q.; Guan, Q. Generative adversarial networks in medical image augmentation: A review. Comput. Biol. Med. 2022, 54, 105382.
- Lu, Y.; Chen, D.; Olaniyi, E.; Huang, Y. Generative adversarial networks (GANs) for image augmentation in agriculture: A systematic review. Comput. Electron. Agric. 2022, 200, 107208.
- Singh, N.K.; Raza, K. Medical image generation using generative adversarial networks: A review. In Health Informatics: A Computational Perspective in Healthcare; Springer: Berlin/Heidelberg, Germany, 2021; pp. 77–96.
- Ko, K.; Yeom, T.; Lee, M. Superstargan: Generative adversarial networks for image-to-image translation in large-scale domains. Neural Netw. 2023, 162, 330–339.
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144.
- Buccitelli, C.; Selbach, M. mRNAs, proteins and the emerging principles of gene expression control. Nat. Rev. Genet. 2020, 21, 630–644.
- Li, R.; Li, L.; Xu, Y.; Yang, J. Machine learning meets omics: Applications and perspectives. Briefings Bioinform. 2022, 23, bbab460.
- Yu, H.; Welch, J.D. MichiGAN: Sampling from disentangled representations of single-cell data using generative adversarial networks. Genome Biol. 2021, 22, 158.
- Yelmen, B.; Decelle, A.; Ongaro, L.; Marnetto, D.; Tallec, C.; Montinaro, F.; Furtlehner, C.; Pagani, L.; Jay, F. Creating artificial human genomes using generative neural networks. PLoS Genet. 2021, 17, e1009303.
- Hazra, D.; Kim, M.R.; Byun, Y.C. Generative Adversarial Networks for Creating Synthetic Nucleic Acid Sequences of Cat Genome. Int. J. Mol. Sci. 2022, 23, 3701.
- Zrimec, J.; Fu, X.; Muhammad, A.S.; Skrekas, C.; Jauniskis, V.; Speicher, N.K.; Boerlin, C.S.; Verendel, V.; Chehreghani, M.H.; Dubhashi, D.; et al. Controlling gene expression with deep generative design of regulatory DNA. Nat. Commun. 2022, 13, 5099.
- Ahmed, K.T.; Sun, J.; Cheng, S.; Yong, J.; Zhang, W. Multi-omics data integration by generative adversarial network. Bioinformatics 2022, 38, 179–186.
- Vinas, R.; Andres-Terre, H.; Lio, P.; Bryson, K. Adversarial generation of gene expression data. Bioinformatics 2022, 38, 730–737.
- Marouf, M.; Machart, P.; Bansal, V.; Kilian, C.; Magruder, D.S.; Krebs, C.F.; Bonn, S. Realistic in silico generation and augmentation of single-cell RNA-seq data using generative adversarial networks. Nat. Commun. 2020, 11, 166.
- Chaudhari, P.; Agrawal, H.; Kotecha, K. Data augmentation using MG-GAN for improved cancer classification on gene expression data. Soft Comput. 2020, 24, 11381–11391.
- Kwon, C.; Park, S.; Ko, S.; Ahn, J. Increasing prediction accuracy of pathogenic staging by sample augmentation with a GAN. PLoS ONE 2021, 16, e0250458.
- Mendez-Lucio, O.; Baillif, B.; Clevert, D.A.; Rouquie, D.; Wichard, J. De novo generation of hit-like molecules from gene expression signatures using artificial intelligence. Nat. Commun. 2020, 11, 10.
- Chen, X.; Roberts, R.; Tong, W.; Liu, Z. Tox-GAN: An Artificial Intelligence Approach Alternative to Animal Studies—A Case Study with Toxicogenomics. Toxicol. Sci. 2022, 186, 242–259.