With the rise in piano teaching in recent years, many people have joined the ranks of piano learners. However, the high cost of traditional manual instruction and the exclusive one-on-one teaching model have made learning the piano an extravagant endeavor. Most existing approaches, based on the audio modality, aim to evaluate piano players' skills. These methods overlook the information contained in videos, resulting in a one-sided and simplistic evaluation of the piano player's skills.
- piano performance
- skills
- media
1. Introduction
2. Methodology
We detail the audio-visual fusion model used for assessing the skill levels of piano performers. Figure 1 shows the framework of our proposal. It consists of three main components: data pre-processing, feature extraction and fusion, and performance evaluation. First, the video data are framed and cropped to serve as the input for the visual branch. The raw audio is then converted to the corresponding Mel-spectrogram using signal processing techniques and spectral analysis methods. Second, we feed the processed video and audio data into the audio-visual fusion model to extract their respective features and fuse the extracted features to form multimodal representations. Finally, we pass the multimodal features as input to the fully connected layer and then perform prediction.
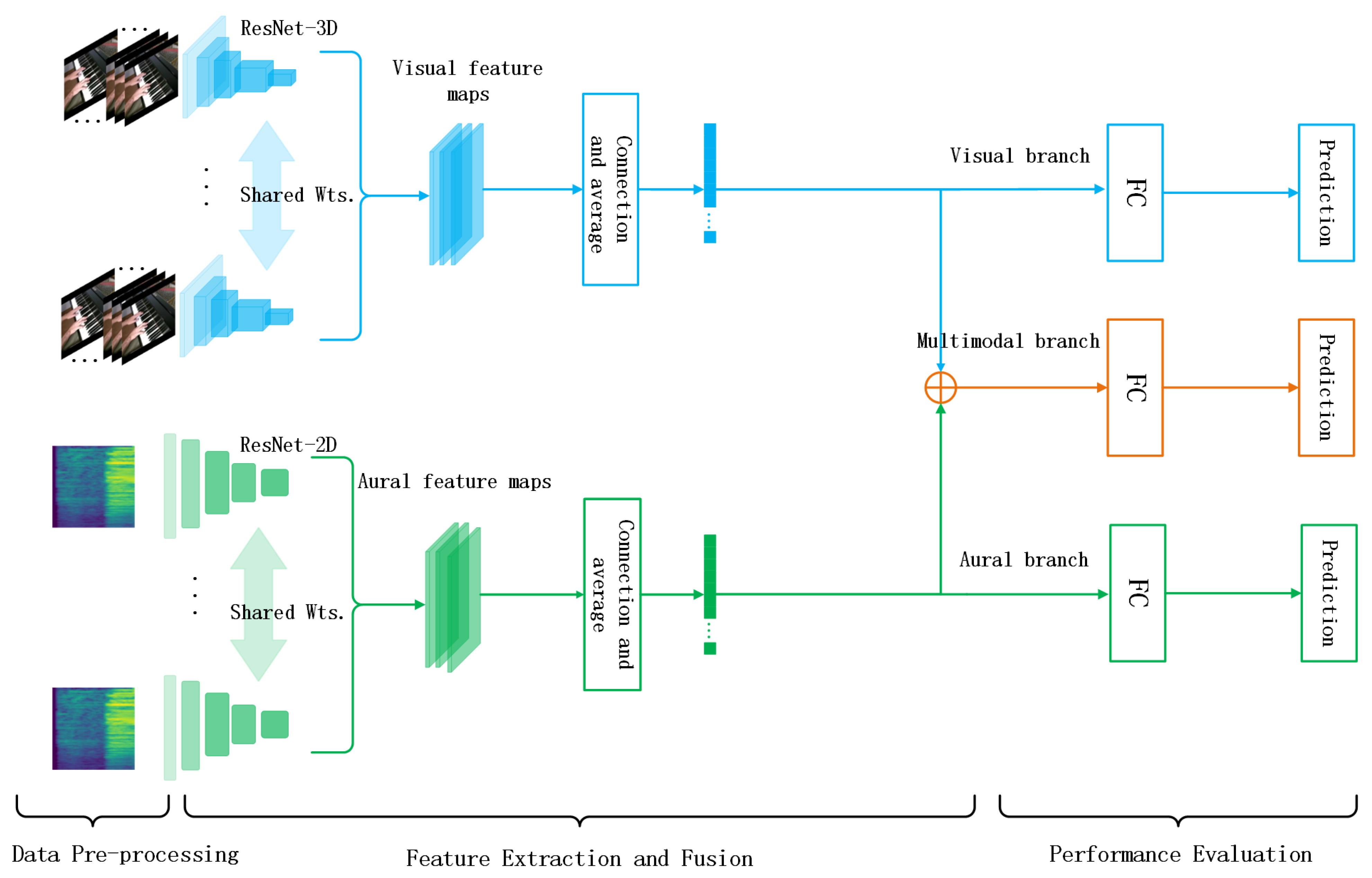
Figure 1. Framework of audio-visual fusion model for piano skills evaluation.
2.1 Data Pre-Processing

2.2 Feature Extraction and Fusion
Visual branch: The movements of fingers captured in videos involve both the appearance and temporal dynamics of the video sequences. The efficient modeling of the spatio-temporal dynamics of these sequences is crucial for extracting robust features, which, in turn, improves the performance of the model. Specifically, we consider ResNet-3D [5] to extract the spatio-temporal features of the performance clips from a video sequence. Compared to conventional 3D CNNs, ResNet-3D can effectively capture the spatio-temporal dynamics of the video modality with higher computational efficiency. For ResNet-3D, we stack multiple 3D convolutional layers to model motion features in the temporal dimension and utilize 3D pooling layers and fully connected layers for feature descent and combination. In this way, we can extract rich visual features from the video data, including information such as the object's shape and color, to capture finger motion patterns. In addition, we can utilize a pre-trained model to improve the model's performance.
Aural branch: Information such as the pitch and rhythm of a piano performance is contained in the audio data, and both raw audio waveforms [6] [7] and spectrograms [8] [9] can be used to extract the auditory features. However, the spectrogram can provide more detailed and accurate audio features. Specifically, we convert the raw audio data into the corresponding Mel-spectrogram, which can be regarded as image data, due to its two-dimensional matrix form. We then feed the obtained Mel-spectrogram to the auditory network. Further, ResNet-2D [10] outperforms the traditional 2D CNN in terms of computational efficiency and feature extraction. Additionally, it can utilize a pre-trained model to improve performance. Therefore, we prefer to use ResNet-2D for feature extraction from the Mel-spectrogram. By stacking 2D convolutional layers, we can capture the patterns and variations in the audio data in the frequency and time dimensions.
Multimodal branch: By utilizing the ResNet-3D and ResNet-2D networks, we have obtained visual and aural features. To better capture the semantic association and complementary information between the video and audio modalities, we adopt a joint representation approach for the features extracted from the video and audio data. This helps to create a more comprehensive and accurate feature representation.
Aggregation option: During the piano performance, the score obtained by the players can be perceived as an additive operation. It is often advantageous to perform linear operations on the learned features, which enhances the interpretability and expressiveness of the learned features. Linear operations can also be utilized to reduce the dimensionality of the features, which enhances the efficiency and generalization capabilities of the model. Consequently, we propose the utilization of linear averaging as the preferred aggregation scheme. Figure 3 shows the details of the linear averaging.
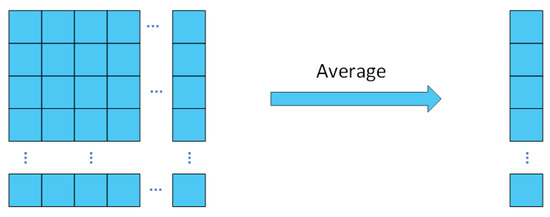
Figure 3. Feature average option.
2.3 Performance Evaluation
In the visual and aural branches, to reduce the dimensionality of the features to 128, we pass them through a linear layer, as shown in Figure 4, and finally input them into the prediction layer. In the multimodal branch, our operations are similar to those of others, except that we do not back-propagate from the multimodal branch to a separate modal backbone to avoid cross-modal contamination.
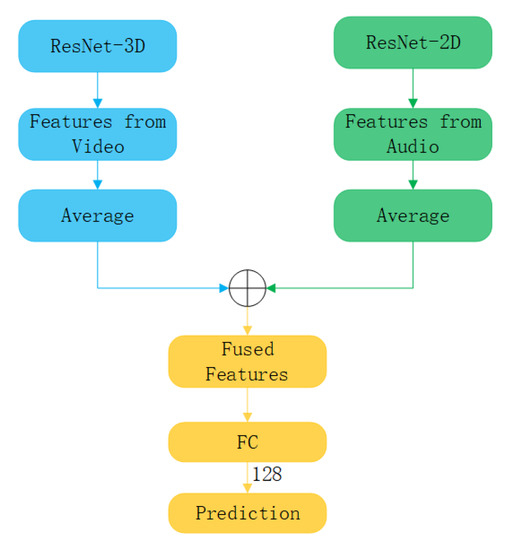
Figure 4. The structure of feature fusion.
3. Results and Conclusions
Table 1 and Figure 5 present the results of the unimodal and audio-visual fusion models on the PISA dataset. Both models achieved good results; however, the audio-visual fusion model achieved better results than the unimodal model. This indicates that the multimodal method can effectively compensate for the inability of the audio model alone to utilize visual information, leading to more accurate and comprehensive evaluation results. In addition, our audio-visual fusion model obtained the best experimental results, achieving an accuracy rate of 70.80%.
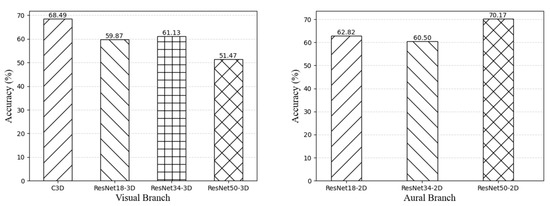
Figure 5. Performance (% accuracy) of unimodal evaluation.
| Model | V : A | Accuracy(%) |
| C3D + ResNet18-2D | 8 : 1 | 68.70 |
| ResNet18-3D + ResNet34-2D | 1 : 1 | 66.39 |
| ResNet34-34 + ResNet18-2D | 1 : 1 | 66.81 |
| Resnet34-3D + ResNet34-2D | 1 : 1 | 65.97 |
| ResNet50-3D + ResNet50-2D | 1 : 1 | 59.45 |
| ResNet18-3D + ResNet18-2D(Ours) | 1 : 1 | 70.80 |
Table 1. Performance (% accuracy) of multimodal evaluation. V:A: the ratio of the number of video features to audio features.
The results in Table 2 show that the accuracy improvement of the audio-visual fusion model was smaller when the ratio of the number of video features to audio features was relatively large. However, when the number of features in both modalities was closer, the accuracy improvement was relatively larger. The reason may be that the number of features of one modality had a significantly larger number of features than the other, which caused the model to place more emphasis on the modality with more features and overlook the modality with fewer features.
| Model | V : A | Accuracy(%) |
| C3D + ResNet18-2D | 8 : 1 | 68.70 |
| ResNet18-3D + ResNet50-2D | 1 : 4 | 65.55 |
| ResNet34-3D + ResNet50-2D | 1 : 4 | 67.02 |
| ResNet50-3D + ResNet18-2D | 4 : 1 | 64.50 |
| ResNet50-3D + ResNet34-2D | 4 : 1 | 61.34 |
| ResNet18-3D + ResNet18-2D(Ours) | 1 : 1 | 70.80 |
Table 2. Performance (% accuracy). V:A: the ratio of the number of video features to audio features.
The fusion of visual and auditory features enables the discovery of correlations and complementarities between audio and visual information, resulting in a more comprehensive and accurate feature representation. By utilizing ResNet as the backbone network, the proposed model leverages ResNet-3D and ResNet-2D to extract visual and auditory features from finger motions (visual) and audio features (auditory), respectively. Then, the visual and auditory features are combined by feature stitching to form multimodal features. Finally, the multimodal features are fed to the linear layer to predict the piano player's skill level.
This entry is adapted from the peer-reviewed paper 10.3390/app13137431
References
- Chang, X.; Peng, L. Evaluation strategy of the piano performance by the deep learning long short-term memory network. Wirel. Commun. Mob. Comput. 2022, 2022, 6727429.
- Zhang, Y. An Empirical Analysis of Piano Performance Skill Evaluation Based on Big Data. Mob. Inf. Syst. 2022, 2022, 8566721.
- Wang, W.; Pan, J.; Yi, H.; Song, Z.; Li, M. Audio-based piano performance evaluation for beginners with convolutional neural network and attention mechanism. IEEE/ACM Trans. Audio, Speech Lang. Process. 2021, 29, 1119–1133.
- O’Shaughnessy, D. Speech Communication: Human and Machine; Addison-Wesley Series in Electrical Engineering; Addison-Wesley Publishing Company: New York, NY, USA, 1987.
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6546–6555.
- Lee, J.; Park, J.; Kim, K.L.; Nam, J. Sample-level deep convolutional neural networks for music auto-tagging using raw waveforms. arXiv 2017, arXiv:1703.01789.
- Zhu, Z.; Engel, J.H.; Hannun, A. Learning multiscale features directly from waveforms. arXiv 2016, arXiv:1603.09509.
- Choi, K.; Fazekas, G.; Sandler, M. Automatic tagging using deep convolutional neural networks. arXiv 2016, arXiv:1606.00298.
- Nasrullah, Z.; Zhao, Y. Music artist classification with convolutional recurrent neural networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778.