Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Subjects:
Automation & Control Systems
Modern online music services have changed the way people search for and listening to music, offering an extensive array of diverse song catalogues while concurrently enhancing user experiences through personalized optimization. Knowledge graphs (KGs) are a rich source of semantic information for entities and relations, allowing for improved modeling and analysis of entity relations to enhance recommendations.
- music information retrieval
- multi-modal knowledge graph
- graph convolutional networks
1. Introduction
Modern online music services have changed the way people search for and listening to music, offering an extensive array of diverse song catalogues while concurrently enhancing user experiences through personalized optimization [1,2]. In this context, the development of music information retrieval [3] has become crucial in enhancing user experience and improving the profitability of these platforms [4]. Music recommender systems, as the core technology of music information retrieval, can provide personalized music recommendations to users based on their preferences and behavioral patterns, thereby increasing user satisfaction, loyalty, and ultimately promoting revenue growth of the music platform [5,6]. Therefore, the importance of music recommender systems is paramount.
Traditional content-based recommendation methods [4] usually only consider the features of the music itself, neglecting the potential relations between music and other entities, such as artists, albums, and playlists. As a result, they fail to uncover deeper semantic information behind the music [7]. Collaborative filtering (CF) methods [8,9], on the other hand, require a large amount of user behavior data, making them less effective for new users or cold-start problems. Additionally, with the development of mobile internet, the data used for recommendation has become more specific and diverse, including user ratings, music tags, and multi-modal data such as texts, images, audios, and sentiment analysis of the music itself. Therefore, there are still challenges in effectively utilizing side information and multi-modal data to enhance the performance of music recommender systems.
2. Convolutional Neural Networks
In recent years, convolutional neural networks (CNNs) have shown impressive performance in the domains of video [17] and images [18]. However, when it comes to non-Euclidean data structures, such as social networks and knowledge graphs, CNNs’ efficacy is limited. To address this issue, researchers have proposed graph convolutional networks (GCNs), which are an extension of CNNs in the non-Euclidean domain. By integrating the features and labeling information of both the central node and its neighboring nodes, GCNs provide a regular expression form of each node in the graph and input it into CNNs. In this way, GCNs can combine multi-scale information to create higher-level expressions, effectively utilizing both the graph structure information and attribute information. Due to their powerful modeling capabilities, GCNs have found widespread use in recommender systems [19,20]. There are two primary methods for GCNs to perform convolution operations: (1) spectral decomposition graph convolution, which is an eigen decomposition using the Laplacian matrix of the graph, and (2) spatial graph convolution, which leverages the spatial characteristics of graph structure data to explore the representation of neighbor nodes, making the representation of each node’s neighboring nodes uniform and regular, which is convenient for convolution operations [21]. KGCN [22] samples the neighbors around a node and dynamically computes local convolutions based on the sampled neighbors to enhance the item embedding representation. LightGCN [23] proposes a lightweight GCN based on an interaction graph by learning users and linearly propagating embedding items on a user–item bipartite graph, and using the weighted sum of embedding item learning across all levels as the final embedding.
MKGCN uses spatial graph convolution for a GCN. While GCNs have been effective in modeling high-order representations of items in KGs, they often neglect modeling user preferences.
3. Multi-Modal Knowledge Graph
Multi-modal knowledge graphs (MMKGs) have become increasingly important in the field of artificial intelligence due to the prevalence of multi-modal data in various domains. MMKGs integrate information from different modalities, such as text, image, and audio, into traditional KGs, which typically only contain structural triples, to improve the performance of downstream KG-related tasks [24]. Figure 3 illustrates the two main approaches for constructing MMKGs. (Please note that the face images in the figure are sourced from the open-source Generated Faces dataset. The dataset can be accessed via the link: https://generated.photos/datasets#, accessed on 6 June 2023.) The first approach, attribute-based MMKGs, considers multi-modal data as specific attribute values of entities or concepts, such as the “poster” and “audio” of a music entity in Figure 3a. The second approach, entity-based MMKGs, treats multi-modal data as separate entities in the KG, as shown by the image-based representation of singer and country entities in Figure 3b. However, entity-based MMKGs do not fuse multi-modal data and therefore limit the exploitation of multi-modal information [25,26].
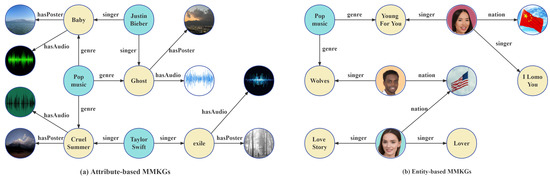
Figure 3. Illustration of the multi-modal knowledge graph. The left subfigure shows an illustration of an attribute-based MMKG and the right subfigure shows an illustration of an entity-based MMKG.
4. Recommendations with MMKGs
As MMKGs are a relatively new concept, there is limited related work on MMKG-based recommender systems. Researchers propose three classifications of existing MMKG-based recommender systems from the perspective of multi-modal feature fusion [27]: (1) The feature-fusion method, also known as the early-fusion method, concatenates features extracted from different modalities into a single high-dimensional feature vector that is then fed into a downstream task. For instance, MKGAT [28] first performs separate feature representations of multi-modal data such as text, image, and triples, and then aggregates the embedding representation of the feature vectors from each modality to make recommendations. However, this method is limited in its ability to model complex relations between modalities. (2) The result-fusion method, also known as the post-fusion method, obtains decisions based on each modality and then integrates these decisions by applying algebraic combination rules for multiple prediction class labels (e.g., maximum, minimum, sum, mean, etc.) to obtain the final result. For example, MMGCN [29] is based on a knowledge graph of three different modalities (text, image, and audio) and then performs user–item interaction predictions on all three knowledge graphs simultaneously. It then linearly aggregates the prediction scores for each modality to obtain the final prediction score. However, this method cannot capture the interconnections between different modalities and requires corresponding multi-modal data for each item. (3) The model-fusion method is a deeper fusion method that produces more optimal joint discriminative feature representations for classification and regression tasks. For instance, MKRLN [30] generates path representations by combining structural and visual information of entities and incorporates the idea of reinforcement learning to iteratively introduce visual features to determine the next step in path selection.
This entry is adapted from the peer-reviewed paper 10.3390/electronics12122688
This entry is offline, you can click here to edit this entry!