In the same way that specialized DNA polymerases (DNAPs) replicate cellular and viral genomes, only a handful of dedicated proteins from various natural origins as well as engineered versions are appropriate for competent exponential amplification of whole genomes and metagenomes (WGA). Different applications have led to the development of diverse protocols, based on various DNAPs. Isothermal WGA is currently widely used due to the high performance of Φ29 DNA polymerase, but PCR-based methods are also available and can provide competent amplification of certain samples. Replication fidelity and processivity must be considered when selecting a suitable enzyme for WGA. However, other properties, such as thermostability, capacity to couple replication, and double helix unwinding, or the ability to maintain DNA replication opposite to damaged bases, are also very relevant for some applications.
1. WGA Protocols Based on PCR
Unquestionably, polymerase chain reaction was one of the most groundbreaking biotechnological methods developed in the 20th century [
10,
11]. PCR’s crucial role in detecting pathogens is well known, as it has been widely used to investigate viruses and microorganisms, including SARS-CoV-2, HIV, cytomegalovirus, influenza,
E. coli, or tuberculosis [
12,
13]. The specificity of PCR for detecting DNA sequences is supported by specific oligonucleotides that hybridize to the target sequences. However, in the case of WGA, the goal is to fully amplify all DNA molecules of the sample, irrespective of its sequence. In fact, the DNA input sequence is often unknown, and WGA is a prior step required for sequencing and further analysis. In these situations, the high specificity of PCR would be a disadvantage. Likewise, PCR methods can also have some other shortcomings, such as limitations in the amplification of long fragments or sequences with very high GC content [
14]. Nonetheless, a great variety of PCR protocols have been successfully developed to overcome this limitation and to achieve competent whole genome amplification.
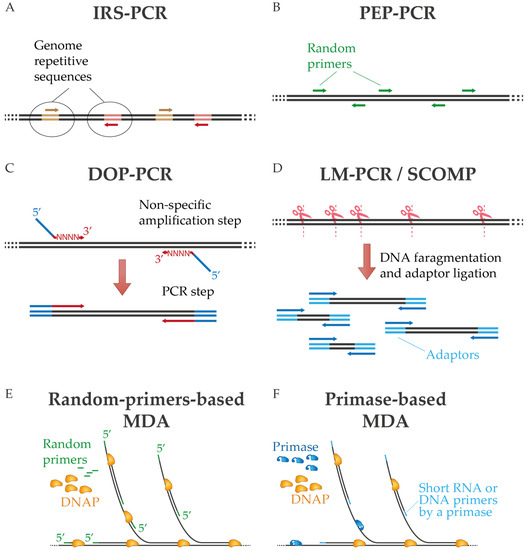
One of the first approaches of non-specific amplification by PCR was interspersed repetitive sequence PCR (IRS-PCR), in which oligonucleotides are directed to repetitive sequences of the genome [
15,
16]. The need to know these repetitive sequences in advance limits its use to applications related to known samples, mostly involving the human genome (
Figure 1A). Alternatively, sequence-independent, single-primer-amplification (SISPA) was developed by Reyes and Kim [
17] to amplify unknown sequences using random primers tagged with a known sequence. SISPA has been mainly used for amplification and detection of metaviromes due to the possibility of generating a sufficient amount of cDNA for cloning and then sequencing [
18,
19], although this method has been further developed [
20,
21]. In degenerate oligonucleotide primed PCR (DOP-PCR), partially degenerate oligonucleotides are used to perform primary non-specific amplification followed by exponential replication by PCR. In this technique, the oligonucleotides have random 3′ tails that can anneal throughout the genome during the first rounds of amplification and a fixed 5′ region for PCR amplification during subsequent cycles (
Figure 1C) [
22,
23]. A related approach is primer extension preamplification PCR (PEP-PCR), in which completely random primers are used to generate an amplified representation of the original input that is subsequently further amplified (
Figure 1B) [
24,
25,
26]. In ligation-mediated PCR (LM-PCR), on the other hand, the genomic sample is digested by chemical cleavage to generate 5′-phosphate-free ends that are ligated with a linker. This linker provides a common sequence for amplification by PCR [
27]. Similarly, in comparative genomic single cell hybridization (SCOMP), adaptors are attached to the enzymatically digested genome [
28,
29] (
Figure 1D).
Figure 1. Diagram of diverse PCR-based WGA techniques (A–D) and multiple displacement amplification (E,F). In MDA are represented methods that use random primers or a dedicated primase. See text for details.
With these true PCR-based approaches, it is possible to achieve complete amplification of the genome from different nucleic acid samples for applications in biomedical or forensic sciences, as described in other comprehensive reviews [
30,
31]. However, isothermal protocols are widely used for WGA and can achieve higher coverage breadth and lower false positive rates than PCR-based methods.
2. WGA Protocols Based on Multiple Displacement Amplification (MDA)
Most of isothermal DNA amplification techniques rely on the use of DNAPs endowed with high processivity and the ability to couple DNA replication and unwinding of the double helix (i.e., strand displacement capacity), such as Geobacillus stearothermophilus polymerase I Klenow Large Fragment (Bst) and Bacillus virus Φ29 DNA polymerase (Φ29DNAP). These methods offer several advantages over PCR protocols because they can amplify tiny amounts of DNA and, thanks to strand displacement capacity, are performed at a constant temperature, eliminating the need for specialized thermal cycler equipment.
Diverse isothermal DNA amplification protocols, such as loop-mediated isothermal amplification (LAMP), strand displacement amplification (SDA), or rolling circle amplification (RCA), are highly sensitive methods that are useful in bioanalysis and point-of-care diagnostics [
32]. However, like PCR, those protocols require prior knowledge of the sequence of interest to design primers, which on the one hand makes them highly sensitive but, on the other hand, unsuitable for generalized DNA amplification, as is the case with whole genome amplification (WGA).
In contrast, multiple displacement DNA amplification (MDA) is a very powerful isothermal whole genome amplification technique that can amplify very small amounts of circular or linear DNA without the need for primer design. In MDA, the newly synthesized product serves as a template without the need for repeated denaturing cycles, resulting in an exponentially growing DNA network at constant temperature. To achieve efficient and reliable genomic amplification, MDA requires a DNAP with high level of processivity and fidelity. While
Bst DNA polymerase is used in several isothermal amplification methods due to its robustness, performance, and thermostability, its moderate processivity and fidelity make it less appropriate for MDA. Instead, Φ29DNAP is the most suitable enzyme for amplification of large DNA sequences, spanning plasmids, viral and cellular genomes, and metagenomic samples [
9,
33,
34]. Although the first application of Φ29DNAP in isothermal rolling circle DNA amplification dates back more than 30 years [
35], this enzyme is still used in most MDA techniques today [
36], and it could be considered a fundamental discovery in the field of nucleic acid amplification.
Standard MDA protocols use random primers, commonly DNA hexamers, that anneal erratically throughout the DNA sample, usually after a previous denaturation step. The phosphodiester link between the last two 3′-terminal nucleotides must be replaced with a phosphorothioate bond to resist degradation by the 3′-5′ exonuclease activity of Φ29DNAP [
37]. Since the optimal temperature for Φ29DNAP is 30 °C, WGA by MDA with this enzyme can be completed isothermally in a few hours (2–16 h, depending on the protocol) [
36]. These primers are then processively elongated by the enzyme, generating long amplicons that subsequently harbor new primers to start new amplicons many times in succession (
Figure 1E), as is well described in other publications [
36,
37]. However, random primers have been reported to be a potential source of bias and artifacts in MDA (see
Section 5) [
38,
39]. Therefore, alternative MDA methods have been developed to avoid the addition of exogenous primers. That is the case of pWGA, which relies on the synthesis of RNA primers by the primase activity of bacteriophage T7 primase/helicase [
40] or the entire T4 replisome [
41]. Then, the phage replicative DNAP processively extends these RNA primers, generating long amplicons. These amplification methods generate hybrid molecules that contain short RNA regions, which could hinder sequence libraries’ preparation or sequencing. Similarly, TruePrime uses the DNA primase-polymerase (PrimPol) from
Thermus thermophilus to generate the short primers, which in that case are DNA primers [
42], avoiding the generation of hybrid RNA/DNA structures. Even though PrimPol has low fidelity [
43], since DNA primers are extended by the high processive Φ29DNAP, these errors are negligible compared with the entire sequence of produced DNA (
Figure 1F). PrimPol-based MDA aims to overcome some of the problems of random primers-based MDA methods, particularly in single-cell amplification protocols. Overall, these primase-based methods result in successful amplification of some samples with reduced artifacts and bias against high-GC sequences for some samples [
44,
45], but others have pointed out some drawbacks [
46]. More recently, a primer-independent B-family DNA polymerase (piPolB) has been used to initiate and extend DNA fragments in the absence of primers. The so-called piMDA protocol combines this method with the efficient extension capability of Φ29DNAP to achieve competent amplification, especially for samples with high-GC content [
47,
48].
A number of hybrid methods have also been developed, such as multiple Annealing and Looping–Based Amplification Cycles (MALBAC), a quasi-linear isothermal amplification method. MALBAC combines cycles of strand-displacement replication and a subsequent PCR amplification. The heat-denaturing cycles requires the employment of thermoresistant enzymes, and, thus, Φ29DNAP is substituted by other DNAP such as
Bst [
9,
49].
This entry is adapted from the peer-reviewed paper 10.3390/ijms24119331