Machine learning assists with food process optimization techniques by developing a model to predict the optimal solution for given input data. Machine learning includes unsupervised and supervised learning, data pre-processing, feature engineering, model selection, assessment, and optimization methods. Various problems with food processing optimization could be resolved using these techniques. Machine learning is increasingly being used in the food industry to improve production efficiency, reduce waste, and create personalized customer experiences. Machine learning may be used to improve ingredient utilization and save costs, automate operations such as packing and labeling, and even forecast consumer preferences to develop personalized products. Machine learning is also being used to identify food safety hazards before they reach the consumer, such as contaminants or spoiled food. The usage of machine learning in the food sector is predicted to rise as more businesses understand the potential of this technology to enhance customer experience and boost productivity.
1. Introduction
Machine learning (ML) is an area of artificial intelligence (AI) that allows computers to learn and improve on their own without being explicitly programmed. Machine learning is concerned with the creation of computer programs that can acquire data and utilize it to learn on their own. The learning process starts with observation or data, such as examples, direct experience, or teaching, to search for trends in data and make better future decisions based on the examples we provide
[1]. The fundamental goal is for computers to learn on their own without user intercession or support and then alter their activities accordingly. Building models capable of discovering trends and connections from training data includes machine learning, which does not require explicit programming. The models are trained using algorithms, which let them learn from the data and make predictions or judgments based on the learned patterns, as opposed to being directly coded. The model is given a labeled dataset during the training phase, where the input data are matched with the appropriate output or goal values. By changing its internal parameters, the model gains the ability to recognize patterns and correlations in the data. This method is frequently known as “learning from examples.” Once trained, the model can utilize the patterns and relationships it has discovered to generate predictions or judgments about fresh, unobserved data. Evaluation metrics, which gauge how closely the model’s predictions match the evaluation dataset’s actual values, are used to assess the model’s performance. This evaluation stage aids in determining the model’s correctness and generalizability. When used in real-world circumstances to make predictions or judgments based on fresh, unforeseen data, the model can be implemented if it exhibits good accuracy and performs well on the assessment data. The model’s learned patterns can be used for a variety of tasks, including image recognition, natural language processing, recommendation systems, and many other activities
[2].
In a variety of ways, ML algorithms can be used to ensure the safety of fruits and vegetables. Support vector machines (SVMs), for example, are supervised learning algorithms that can be used to identify potential contaminants in food products. SVMs can also detect possible microbial contamination in fruits and vegetables
[3]. Unsupervised learning algorithms such as k-means clustering can be used to group similar food items and identify outliers that could be contamination sources. Anomaly detection algorithms, such as isolation forests, can be used to identify unusual patterns that may indicate food safety concerns. Finally, reinforcement learning algorithms can be used to create an optimal inspection and response process to address fruit and vegetable safety concerns
[4].
Machine learning can be used to help with fruit preservation in several ways. For example, machine learning algorithms can be used to monitor the quality of stored fruit and alert when conditions are not ideal. Machine learning can also monitor environmental conditions such as temperature and humidity and adjust the environment to optimize fruit preservation. ML helps to predict the optimal time for harvest, packaging, and distribution of the fruit to ensure it is fresh for the customer
[5].
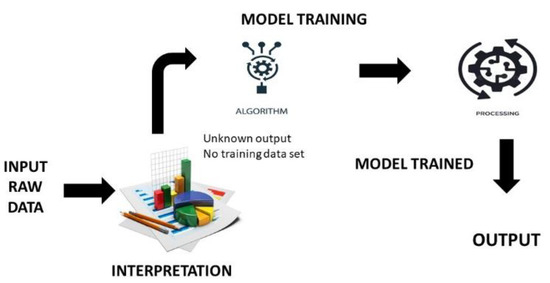
Figure 1 depicts the principle of machine learning.
Figure 1. Principle behind working of machine learning in food interpretation.
The basic principle of machine learning applied to ready-to-eat fruits is to use large amounts of data to identify patterns, apply algorithms, and then create models that can be used to make predictions. For example, data regarding the soil, climate, and other factors that influence fruit quality can be used to create a predictive model that can recommend the best types of fruit to buy and even the best time of year to buy them
[6].
This model can then be applied to data gathered from numerous sources to make better decisions about the quality of the fruit or even the best time of year to purchase it. ML is used in fresh-cut fruits in various ways. It has the potential to monitor the quality of fresh-cut fruit by detecting and analyzing any visible defects. It can also be used to determine the physical properties of the fruits and their freshness. It can also be used to track the freshness of stored fruit and alert the user when it is no longer in optimal condition. This technology is used to forecast the life span of fresh-cut fruit based on its current condition
[7].
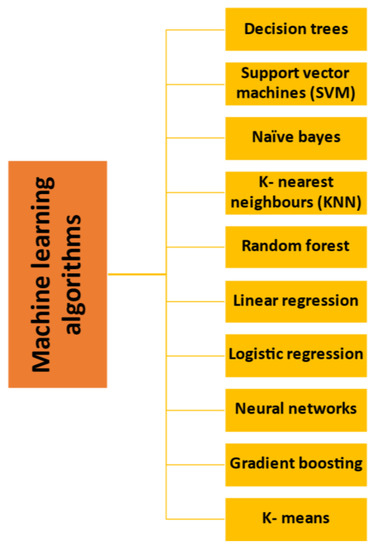
Figure 2 represents various algorithms used in machine learning operations of food processing.
Figure 2. Various algorithms used in machine learning interpretation in the food industry.
2. Spoilage Prediction
To forecast the possibility of rotting, machine learning algorithms can examine previous data on variables such as temperature, humidity, storage time, and quality characteristics. The model can notify food producers or suppliers when specific circumstances are about to occur that could cause spoilage by considering patterns and correlations in the data. This makes it possible to act quickly to change storage conditions, speed up distribution, or get rid of possibly ruined goods from the supply chain
[3]. The machine learning model may be trained to recognize rotten food indicators such as discoloration, mold, strange odors, and sliminess. This can be achieved by examining food image data and applying computer vision algorithms to recognize visual characteristics linked to deterioration. When food may be rotting and needs to be thrown out, this might be used to warn vendors and customers. It is possible to estimate how quickly food will spoil under various circumstances using machine learning. The program can identify key variables and how they interact to forecast how quickly food will decay by learning from historical data on food deterioration
[8].
3. Quality Monitoring
To evaluate the quality and freshness of food goods, machine learning algorithms can examine a variety of quality indicators, including color, texture, and chemical composition. The algorithm can learn to detect and recognize symptoms of deterioration or spoilage by training models on labeled data that indicate varying levels of quality. Using computer vision techniques, real-time monitoring can also be used to find visual signs of spoiling such as mold growth or color changes
[9]. It is possible to monitor the temperature, humidity, and other environmental conditions that impact food quality and freshness using other technologies, such as sensors, automated imaging, and blockchain. Using these data, it is possible to forecast when food may go bad and warn customers and retailers about potential food safety risks. Food may be tracked via blockchain technology from farm to consumer, enhancing openness and accountability throughout the food supply chain
[10].
4. Shelf-Life Estimation
Perishable food items’ remaining shelf life can be estimated using machine learning models based on a variety of variables, including storage circumstances, initial quality, and product attributes
[11]. The algorithm can provide precise estimates of how long a specific product will remain fresh and safe to consume by analyzing the deterioration patterns in the data. Utilizing this knowledge can improve inventory control, cut down on waste, and stop customers from buying spoiled goods
[4]. Machine learning algorithms can calculate the remaining shelf life of perishable foods depending on a range of factors, such as storage conditions, initial quality, and product characteristics. By analyzing the patterns of deterioration in the data, the computer can give precise estimations of how long a certain product will stay fresh and safe to ingest. Utilizing this information can enhance inventory management, reduce waste, and prevent customers from purchasing defective goods
[12].
5. Intelligent Storage Optimization
By examining vast volumes of data on temperature, humidity, ventilation, and other pertinent parameters, machine learning algorithms can optimize storage conditions. In light of each type of fruit and vegetable’s unique preservation needs, the models can determine the best storage conditions. The danger of spoilage can be reduced by continuously monitoring and modifying these variables based on real-time data and projections
[13]. Producers and merchants may decrease losses from spoiling, enhance inventory management, and boost productivity by utilizing machine learning to forecast the ideal storage conditions. The algorithms can also identify environmental changes that would endanger the stored produce, enabling farmers and retailers to take action to safeguard their stock. Machine-learning-driven recommendations can enhance the quality and shelf life of produce that is being stored, enabling farmers and retailers to increase earnings and reduce waste
[14].
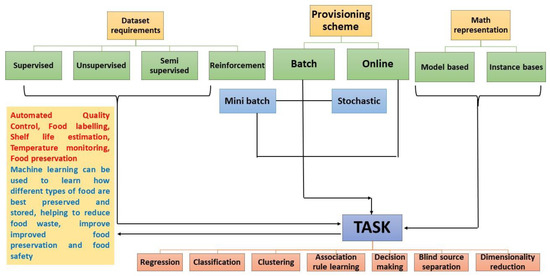
Figure 3 represents the taxonomic hierarchy of the machine learning.
Figure 3. Taxonomical hierarchy of machine learning.
6. Supply Chain Optimization
Machine learning can analyze data from every step of the food supply chain, from production to storage, to spot bottlenecks or locations where food spoiling is more likely to happen. By locating key supply chain nodes that influence food deterioration, effective interventions can be taken to streamline procedures, cut down on handling time, or optimize transit and storage methods
[15]. In order to determine which parts of a warehouse or transport vehicle are most likely to result in rotting, machine learning algorithms can analyze data on temperature, humidity, and other environmental conditions. Utilizing various packaging materials, altering the route taken for transportation, or improving humidity and temperature controls are just a few examples of how this information can be used to optimize storage and transportation techniques
[16].
This entry is adapted from the peer-reviewed paper 10.3390/pr11061720