Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Camila Xu and Version 1 by SONAIN JAMIL.
Vision transformers (ViTs) are designed for tasks related to vision, including image recognition. Originally, transformers were used to process natural language (NLP). As a special type of transformer, vision transformers (ViTs) can be used for various computer vision (CV) applications.
- vision transformers
- computer vision
- deep learning
- image coding
1. Introduction
Vision transformers (ViTs) are designed for tasks related to vision, including image recognition [1]. Originally, transformers were used to process natural language (NLP). Bidirectional encoder representations from transformers (BERT) [2] and generative pretrained transformer 3 (GPT-3) [3] were the pioneers of transformer models for natural language processing. In contrast, classical image processing systems use convolutional neural networks (CNNs) for different computer vision (CV) tasks. The most common CNN models are AlexNet [4[4][5],5], ResNet [6], VGG [7], GoogleNet [8], Xception [9], Inception [10[10][11],11], DenseNet [12], and EfficientNet [13].
To track attention links between two input tokens, transformers are used. With an increasing number of tokens, the cost rises inexorably. The pixel is the most basic unit of measurement in photography, but calculating every pixel relationship in a normal image would be time-consuming; memory-intensive [14]. ViTs, however, take several steps to do this, as described below:
-
ViTs divide the full image into a grid of small image patches.
-
ViTs apply linear projection to embed each patch.
-
Then, each embedded patch becomes a token, and the resulting sequence of embedded patches is passed to the transformer encoder (TE).
-
Then, TE encodes the input patches, and the output is given to the multilayer perceptron (MLP) head, with the output of the MLP head being the input class.
Figure 1 shows the primary illustration of ViTs. In the beginning, the input image is divided into smaller patches. Each patch is then embedded using linear projection. Tokens are created from embedded patches that are given to the TE as inputs. Multihead attention and normalization are used by the TE to encode the information embedded in patches. The TE output is given to the MLP head, and the MLP head output is the input image class.
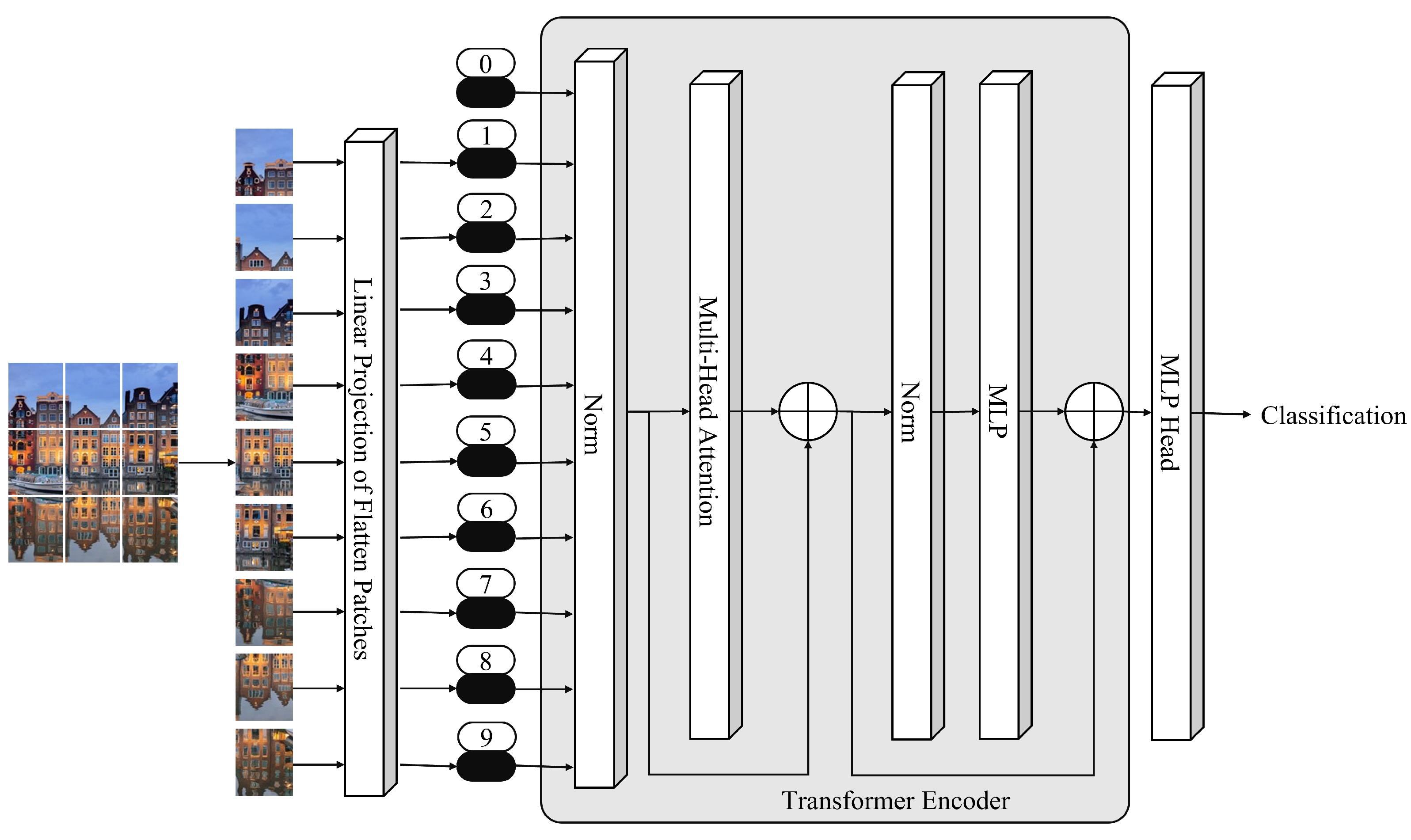
Figure 1.
ViT for Image Classification.
For image classification, the most popular architecture uses the TE to convert multiple input tokens. However, the transformer’s decoder can also be used for other purposes. As described in 2017, transformers have rapidly spread across NLP, becoming one of the most widely used and promising designs [15].
For CV tasks, ViTs were applied in 2020 [16]. The aim was to construct a sequence of patches that, once reconstructed into vectors, are interpreted as words by a standard transformer. Imagine that the attention mechanism of NLP transformers was designed to capture the relationships between different words within the text. In this case, the CV takes into account how the different patches of the image relate to one another.
In 2020, a pure transformer outperformed CNNs in image classification [16]. Later, a transformer backend was added to the conventional ResNet, drastically lowering costs while enhancing accuracy [17,18][17][18].
In the same year, several key ViT versions were released. These variants were more efficient, accurate, or applicable to specific regions. Swin transformers are the most prominent variants [19]. Using a multistage approach and altering the attention mechanism, the Swin transformer achieved cutting-edge performance on object detection datasets. There is also the TimeSformer, which was proposed for video comprehension issues and may capture spatial and temporal information through divided space–time attention [20].
ViT performance is influenced by decisions such as optimizers, dataset-specific hyperparameters, and network depth. Optimizing a CNN is significantly easier. Even when trained on data quantities that are not as large as those required by ViTs, CNNs perform admirably. Apparently, CNNs exhibit this distinct behavior because of some inductive biases that they can use to comprehend the particularities of images more rapidly, even if they end up restricting them, making it more difficult for them to recognize global connections. ViTs, on the other hand, are devoid of these biases, allowing them to capture a broader and more global set of relationships at the expense of more difficult data training [21].
ViTs are also more resistant to input visual distortions such as hostile patches and permutations [22]. Conversely, preferring one architecture over another may not be the best choice. The combination of convolutional layers with ViTs has been shown to yield excellent results in numerous CV tasks [23,24,25][23][24][25].
To train these models, alternate approaches were developed due to the massive amount of data required. It is feasible to train a neural network virtually autonomously, allowing it to infer the characteristics of a given issue without requiring a large dataset or precise labeling. It might be the ability to train ViTs without a massive vision dataset that makes this novel architecture so appealing.
ViTs have been employed in numerous CV jobs with outstanding and, in some cases, cutting-edge outcomes. The following are some of the important application areas:
-
Image classification;
-
Anomaly detection;
-
Object detection;
-
Image compression;
-
Image segmentation;
-
Video deepfake detection;
-
Cluster analysis.
Figure 2 shows that the percentage of the application of ViTs for image classification, object detection, image segmentation, image compression, image super-resolution, image denoising, and anomaly detection is 50%, 40%, 3%, less than 1%, less than 1%, 2%, and 3% respectively.
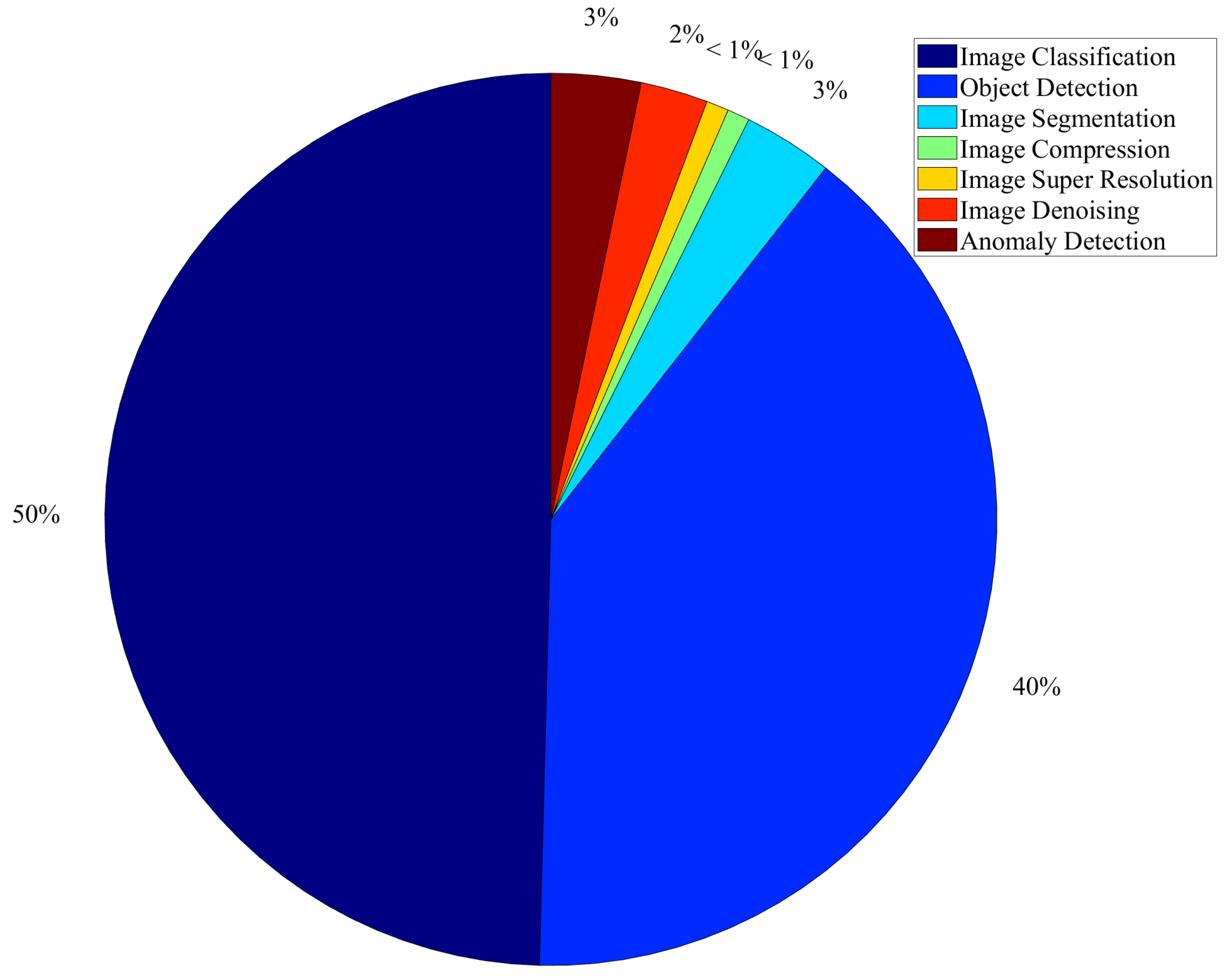
Figure 2.
Use of ViTs for CV applications.
ViTs have been widely utilized in CV tasks. ViTs can solve the problems faced by CNNs. Different variants of ViTs are used for image compression, super-resolution, denoising, and segmentation. With the advancement in the ViTs for CV applications, a state-of-the-art survey is needed to demonstrate the performance advantage of ViTs over current CV application approaches.
2. Advanced ViTs
In addition to their promising use in vision, some transformers have been particularly designed to perform a specific task or to solve a particular problem.2.1. Task-Based ViTs
Task-based ViTs are those ViTs that are designed for a specific task and perform exceptionally well for that task. Lee et al. in [120][26] proposed the multipath ViT (MPViT) for dense prediction by embedding features of the same sequence length with the patches of the different scales. The model achieved superior performance for classification, object detection, and segmentation. However, the model is specific to dense prediction. In [121][27], the authors proposed the coarse-to-fine ViT (C2FViT) for medical image registration. C2FViT uses convolutional ViT [24,122][24][28] an ad multiresolution strategy [123][29] to learn global affine for image registration. The model was specifically designed for affine medical image registration. Similarly, in [124][30], the authors proposed TransMorph for medical image registration and achieved state-of-the-art results. However, these models are task-specific, which is why they are categorized as task-based ViTs here.2.2. Problem-Based ViTs
Problem-based ViTs are those ViTs which are proposed to solve a particular problem that cannot be solved by pure ViTs. These types of ViTs are not dependent on tasks but rather on problems. For example, ViTs are not flexible. To make a ViT more flexible and to reduce its complexity, the authors in [125][31] proposed a messenger (MSG) transformer. They used specialized MSG tokens for each region. By manipulating these tokens, one can flexibly exchange visual information across the regions. This reduces the computational complexity of ViTs. Similarly, it has been discovered that mixup-based augmentation works well for generalizing models during training, especially for ViTs because they are prone to overfitting. However, the basic presumption of earlier mixup-based approaches is that the linearly interpolated ratio of targets should be maintained constantly with the percentage suggested by input interpolation. As a result, there may occasionally be no valid object in the mixed image due to the random augmentation procedure, but there is still a response in the label space. Chen et al. in [126][32] proposed TransMix for bridging this gap between the input and label spaces. TransMix blends labels based on the attention maps of ViTs. In ViTs, global attention is computationally expensive, whereas local attention provides limited interactions between tokens. To solve this problem, the authors in [127][33] proposed the CSWin transformer based on the cross-shaped window self-attention. This provided efficient computation of self-attention and achieved better results than did the pure ViTs.3. Open Source ViTs
This section summarizes the available open-source ViTs with potential CV applications. Table 1 presents the comprehensive summary of the open-source ViTs for the different applications of CV such as image classification, object detection, instance segmentation, semantic segmentation, video action classification, and robustness evaluation.Table 1.
Summary of the open-source ViTs present in the literature for different applications of CV.
| Research | Year | Model Name | CV Application | Source Code |
|---|---|---|---|---|
| [1] | 2021 | PiT α� | ||
|
Table 2.
ViTs for drone imagery.
| Ref. | Model | Dataset | Objective | Perf. Metric | Value | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| [142][53] | TransVisDrone †† |
|
|
Drone detectionhttps://github.com/naver-ai/pit (accessed on 19 April 2023) | ||||||
| AP@0.5IoU |
|
|
[16] | |||||||
| [146][57 | 2020 | ] |
|
|
https://github.com/google-research/vision_transformer (accessed on 19 April 2023) | |||||
| Date palm trees | Segmentation | mIoU α� |
|
[19] | 2021 | Swin Transformer |
| |||
| [146][57] |
|
|
https://github.com/microsoft/Swin-Transformer (accessed on 19 April 2023) | |||||||
| Date palm trees | Segmentation | mF-Score | β� |
|
[32][34] | |||||
| [ | 2021 | 146][57] |
|
|
https://github.com/IBM/CrossViT (accessed on 19 April 2023) | |||||
|
|
[122][28] | ||||||||
| [150 | 2021 | ][61] | TPH-YOLOv5 ††††CeiT γ� |
|
https://github.com/rishikksh20/CeiT-pytorch (accessed on 19 April 2023) | |||||
| VisDrone2021 | Object detection | mAP | δ� |
|
[128][35] | |||||
| [151][ | 2022 | 62] |
|
|
https://github.com/microsoft/Swin-Transformer (accessed on 19 April 2023) | |||||
| VisDrone-DET2021 | Object detection | AP |
|
[129][36] | 2021 | DVT †† |
|
https://github.com/blackfeather-wang/Dynamic-Vision-Transformer (accessed on 19 April 2023) | ||
| [130][37] | 2021 | PVT †††† |
|
https://github.com/whai362/PVT (accessed on 19 April 2023) | ||||||
| [131][38] | 2021 | Twins |
|
https://github.com/Meituan-AutoML/Twins (accessed on 19 April 2023) | ||||||
| [132][39] | 2021 | Mobile-ViT |
|
https://github.com/apple/ml-cvnets (accessed on 19 April 2023) | ||||||
| [133][40] | 2021 | Refiner |
|
https://github.com/zhoudaquan/Refiner_ViT (accessed on 19 April 2023) | ||||||
| [134][41] | 2021 | DeepViT †††††† |
|
https://github.com/zhoudaquan/dvit_repo (accessed on 19 April 2023) | ||||||
| [135][42] | 2021 | DeiT †††††††† |
|
https://github.com/facebookresearch/deit (accessed on 19 April 2023) | ||||||
| [136][43] | 2021 | Visformer |
|
https://github.com/danczs/Visformer (accessed on 19 April 2023) |
α� Pooling-based Vision Transformer, ∗* Vision transformer, †† Dynamic vision transformer, †††† Pyramid vision transformer, †††††† Deeper vision transformer, †††††††† Data-efficient image Transformer, γ� Convolution-enhanced image Transformer; a� Image classification, b� Detection, c� Segmentation, d� Video action classification, e Robustness evaluation.
4. ViTs and Drone Imagery
In drone imagery, unmanned aerial vehicles (UAVs) or drones capture images or videos. Images of this type can provide a birds-eye view of a particular area, which can be useful for various applications, such as land surveys, disaster management, agricultural planning, and urban development. Initially, DL models such as CNNs [137][44], recurrent neural networks (RNNs) [138][45], fully convolutional networks (FCNs) [139][46], and generative adversarial networks (GANs) [140][47] were widely used for tasks in which drone image processing was involved. CNNs are commonly used for image classification and object detection using drone images. These are particularly useful, as these models can learn to detect features such as buildings, roads, and other objects of interest. Similarly, RNNs are commonly used for processing time-series data, such as drone imagery. These models are able to learn to detect changes in the landscape over time. These are useful for tasks such as crop monitoring and environmental monitoring. FCNs are mainly used for semantic segmentation tasks, such as identifying different types of vegetation in drone imagery. These can be used to create high-resolution maps of the landscape, which can be useful for various applications. GANs are commonly used for image synthesis tasks, such as generating high-resolution images of the landscape from low-resolution drone imagery. These can also be used for data augmentation, which can help to improve the performance of other DL models. When it comes to drone imagery, ViTs can be used for a variety of tasks because of the advantages of ViTs over traditional DL models [26,27,28,31][48][49][50][51]. ViTs use a self-attention mechanism that allows these models to focus on relevant parts of the input data [21]. This is particularly useful when processing drone imagery, which may contain a lot of irrelevant information, such as clouds or trees, that can distract traditional DL models. By selectively attending to relevant parts of the image, transformers can improve their accuracy. Similarly, traditional DL models typically process data in a sequential manner, which is slow and inefficient, especially when dealing with large amounts of data. ViTs, on the other hand, can process data in parallel, making them much faster and more efficient. Another advantage of ViTs over traditional DL models is efficient transfer learning ability [141][52], as ViTs are pretrained on large amounts of data, allowing them to learn general features that can be applied to a wide range of tasks. This means that they can be easily fine-tuned for specific tasks, such as processing drone imagery, with relatively little training data. Moreover, one of the most important advantages is the ability to handle variable-length input as drone imagery can vary in size and shape, making it difficult for traditional DL models to process. ViTs, on the other hand, can handle variable-length input, making them better suited for processing drone imagery. Similarly, another main advantage of using ViTs for drone imagery analysis is their ability to handle long sequences of inputs. This is particularly useful for drone imagery, where large images or video frames must be processed. Additionally, ViTs can learn complex spatial relationships between different image features, leading to more accurate results than those produced with other DL models. ViTs are used for object detection, disease detection, prediction, classification, and segmentation using drone imagery. This section briefly summarizes the applications of ViT using drone imagery. In [142]| Date palm trees | |||||
| Segmentation | mAcc | γ | � |
| |
†† https://github.com/tusharsangam/TransVisDrone (accessed on 19 April 2023), †††† https://github.com/cv516Buaa/tph-yolov5 (accessed on 19 April 2023); α� mean intersection over union, β� mean F-Score, γ� mean accuracy, δ� mean average precision. red color text: Worst performing model, green color text: best-performing model.
References
- Heo, B.; Yun, S.; Han, D.; Chun, S.; Choe, J.; Oh, S.J. Rethinking spatial dimensions of vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 11936–11945.
- Tenney, I.; Das, D.; Pavlick, E. BERT rediscovers the classical NLP pipeline. arXiv 2019, arXiv:1905.05950.
- Floridi, L.; Chiriatti, M. GPT-3: Its nature, scope, limits, and consequences. Minds Mach. 2020, 30, 681–694.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90.
- Jamil, S.; Rahman, M.; Ullah, A.; Badnava, S.; Forsat, M.; Mirjavadi, S.S. Malicious UAV detection using integrated audio and visual features for public safety applications. Sensors 2020, 20, 3923.
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133.
- Hammad, I.; El-Sankary, K. Impact of approximate multipliers on VGG deep learning network. IEEE Access 2018, 6, 60438–60444.
- Yao, X.; Wang, X.; Karaca, Y.; Xie, J.; Wang, S. Glomerulus classification via an improved GoogLeNet. IEEE Access 2020, 8, 176916–176923.
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258.
- Wang, C.; Chen, D.; Hao, L.; Liu, X.; Zeng, Y.; Chen, J.; Zhang, G. Pulmonary image classification based on inception-v3 transfer learning model. IEEE Access 2019, 7, 146533–146541.
- Jamil, S.; Fawad; Abbas, M.S.; Habib, F.; Umair, M.; Khan, M.J. Deep learning and computer vision-based a novel framework for himalayan bear, marco polo sheep and snow leopard detection. In Proceedings of the 2020 International Conference on Information Science and Communication Technology (ICISCT), Karachi, Pakistan, 8–9 February2020; pp. 1–6.
- Zhang, K.; Guo, Y.; Wang, X.; Yuan, J.; Ding, Q. Multiple feature reweight densenet for image classification. IEEE Access 2019, 7, 9872–9880.
- Wang, J.; Yang, L.; Huo, Z.; He, W.; Luo, J. Multi-label classification of fundus images with efficientnet. IEEE Access 2020, 8, 212499–212508.
- Hossain, M.A.; Nguyen, V.; Huh, E.N. The trade-off between accuracy and the complexity of real-time background subtraction. IET Image Process. 2021, 15, 350–368.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 18 April 2023).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929.
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677.
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 2021, 34, 30392–30400.
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 10012–10022.
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In ICML; PMLR, 2021; Volume 2, p. 4. Available online: https://proceedings.mlr.press/v139/bertasius21a.html (accessed on 18 April 2023).
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128.
- Naseer, M.M.; Ranasinghe, K.; Khan, S.H.; Hayat, M.; Shahbaz Khan, F.; Yang, M.H. Intriguing properties of vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 23296–23308.
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977.
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 22–31.
- Coccomini, D.A.; Messina, N.; Gennaro, C.; Falchi, F. Combining efficientnet and vision transformers for video deepfake detection. In International Conference on Image Analysis and Processing; Springer: Cham, Switzerland, 2022; pp. 219–229.
- Lee, Y.; Kim, J.; Willette, J.; Hwang, S.J. MPViT: Multi-path vision transformer for dense prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7287–7296.
- Mok, T.C.; Chung, A. Affine Medical Image Registration with Coarse-to-Fine Vision Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20835–20844.
- Yuan, K.; Guo, S.; Liu, Z.; Zhou, A.; Yu, F.; Wu, W. Incorporating convolution designs into visual transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 579–588.
- Sun, W.; Niessen, W.J.; Klein, S. Hierarchical vs. simultaneous multiresolution strategies for nonrigid image registration. In International Workshop on Biomedical Image Registration; Springer: Berlin/Heidelberg, Germany, 2012; pp. 60–69.
- Chen, J.; Frey, E.C.; He, Y.; Segars, W.P.; Li, Y.; Du, Y. TransMorph: Transformer for unsupervised medical image registration. Med. Image Anal. 2022, 82, 102615.
- Fang, J.; Xie, L.; Wang, X.; Zhang, X.; Liu, W.; Tian, Q. Msg-transformer: Exchanging local spatial information by manipulating messenger tokens. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12063–12072.
- Chen, J.N.; Sun, S.; He, J.; Torr, P.H.; Yuille, A.; Bai, S. Transmix: Attend to mix for vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12135–12144.
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12124–12134.
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 357–366.
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019.
- Wang, Y.; Huang, R.; Song, S.; Huang, Z.; Huang, G. Not all images are worth 16x16 words: Dynamic transformers for efficient image recognition. Adv. Neural Inf. Process. Syst. 2021, 34, 11960–11973.
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 568–578.
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366.
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178.
- Zhou, D.; Shi, Y.; Kang, B.; Yu, W.; Jiang, Z.; Li, Y.; Jin, X.; Hou, Q.; Feng, J. Refiner: Refining self-attention for vision transformers. arXiv 2021, arXiv:2106.03714.
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886.
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2021; pp. 10347–10357.
- Chen, Z.; Xie, L.; Niu, J.; Liu, X.; Wei, L.; Tian, Q. Visformer: The vision-friendly transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 589–598.
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote. Sens. Mag. 2016, 4, 22–40.
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote. Sens. Mag. 2017, 5, 8–36.
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440.
- Jozdani, S.; Chen, D.; Pouliot, D.; Johnson, B.A. A review and meta-analysis of generative adversarial networks and their applications in remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102734.
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient transformers: A survey. ACM Comput. Surv. (CSUR) 2020, 55, 1–28.
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41.
- Liu, Y.; Zhang, Y.; Wang, Y.; Hou, F.; Yuan, J.; Tian, J.; Zhang, Y.; Shi, Z.; Fan, J.; He, Z. A survey of visual transformers. arXiv 2021, arXiv:2111.06091.
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110.
- Zhou, H.Y.; Lu, C.; Yang, S.; Yu, Y. ConvNets vs. Transformers: Whose visual representations are more transferable? In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2230–2238.
- Sangam, T.; Dave, I.R.; Sultani, W.; Shah, M. Transvisdrone: Spatio-temporal transformer for vision-based drone-to-drone detection in aerial videos. arXiv 2022, arXiv:2210.08423.
- Li, J.; Ye, D.H.; Chung, T.; Kolsch, M.; Wachs, J.; Bouman, C. Multi-target detection and tracking from a single camera in Unmanned Aerial Vehicles (UAVs). In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4992–4997.
- Rozantsev, A.; Lepetit, V.; Fua, P. Detecting flying objects using a single moving camera. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 879–892.
- Liu, Z.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J.; et al. VisDrone-CC2021: The vision meets drone crowd counting challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2830–2838.
- Gibril, M.B.A.; Shafri, H.Z.M.; Al-Ruzouq, R.; Shanableh, A.; Nahas, F.; Al Mansoori, S. Large-Scale Date Palm Tree Segmentation from Multiscale UAV-Based and Aerial Images Using Deep Vision Transformers. Drones 2023, 7, 93.
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090.
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 7262–7272.
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 12179–12188.
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2778–2788.
- Cao, Y.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J.; et al. VisDrone-DET2021: The vision meets drone object detection challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2847–2854.
- Thai, H.T.; Tran-Van, N.Y.; Le, K.H. Artificial cognition for early leaf disease detection using vision transformers. In Proceedings of the 2021 International Conference on Advanced Technologies for Communications (ATC), Ho Chi Minh City, Vietnam, 14–16 October 2021; pp. 33–38.
More