Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Fernando Camarena and Version 2 by Rita Xu.
Artificial intelligence’s rapid advancement has enabled various applications, including intelligent video surveillance systems, assisted living, and human–computer interaction. These applications often require one core task: video-based human action recognition.
- video-based human action recognition
- action recognition
- human action
1. Introduction
Artificial intelligence (AI) redefines theour understanding of the world by enabling high-impact applications such as intelligent video surveillance systems [1], self-driving vehicles [2], and assisted living [3]. In addition, AI is revolutionizing areas such as education [4], healthcare [5], abnormal activity recognition [6], sports [7], entertainment [4][8][4,8], and human–computer interface systems [9]. These applications frequently rely upon the core task of video-based human action recognition, an active research field to extract meaningful information by detecting and recognizing what a subject is doing in a video [10][11][12][10,11,12]. Since its critical role in computer vision applications, the action recognition study can lead to innovative solutions that can benefit society in various ways. Nevertheless, it can take time to introduce oneself to the subject thoroughly.
2. Understanding Video-Based Human Action Recognition
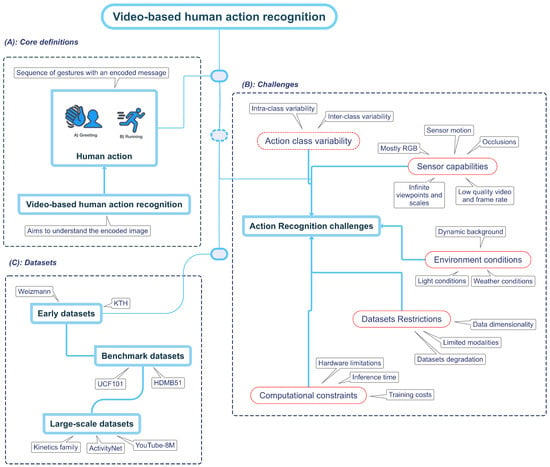
Figure 1. Video-based human action recognition overview. Part (A) represents human action; rwesearchers instinctively associate a sequence of gestures with an action. For example, researcherswe might think of the typical hand wave when researcherswe think of the action greeting. On the contrary, imagining a person running will create a more dynamic scene with movement centered on the legs. Part (B) explains current challenges in the field, and Part (C) shows the relevant dataset used.
2.1. What Is an Action?
To understand the idea behind an action, picture the image of a person greeting another. Probably, the mental image constructed involves the well-known waving hand movement. Likewise, if reswearchers create a picture of a man running, theywe may build a more dynamic image by focusing on his legs, as depicted in Figure 1. RWesearchers unconsciously associate a particular message with a sequence of movements, which theywe call “an action” [4][13][4,28]. In other words, human action is an observable entity that another entity, including a computer, can decode through different sensors. The human action recognition goal is to build approaches to understand the encoded message in the sequence of gestures.2.2. Challenges Involved in Video-Based Human Action Recognition
While humans have a natural ability to perceive and comprehend actions, computers face various difficulties when recognizing such human actions [14][26]. RWesearchers categorize the challenges into five primary categories: action-class variability, sensor capabilities, environment conditions, dataset restrictions, and computational constraints. By understanding these challenges, researcherswe may build strategies to overcome them and, consequently, improve the model’s performance.2.2.1. Action Class Variability
Both strong intra- and inter-class variations of an action class represent a challenge for video-based human action recognition [14][26]. The intra-class variations refer to differences within a particular action class [15][29]. These variations stem from various factors, such as age, body proportions, execution rate, and anthropometric features of the subject [16][30]. For example, the running action significantly differs between an older and a younger individual. Additionally, reswearchers have repeated some of the actions so many times that researcherswe already perform them naturally and unconsciously, making it difficult even for the same person to act precisely the same way twice [14][16][26,30]. Finally, cultural contexts can impact how humans act, such as in the case of the greeting action class [17][31]. Due to the variability, developing a single model that accurately represents all instances of the same class is challenging [14][26]. Therefore, mitigating intra-class variation is a crucial research area in computer vision to represent all instances of the same class accurately. Conversely, inter-class variation refers to the dissimilarities between distinct action classes [14][26], representing a significant challenge because some actions could share major feature vectors [18][27]. For example, while standing up and sitting down may be perceived as distinct actions, they share the same structure and semantics, making it challenging to differentiate one from another if the model approach does not consider their temporal structure [19][32]. A similar case is the walking and running actions, which, despite being different, can be seen as variations of the same underlying action. Therefore, to make computer vision applications more accurate and valuable, it is essential to make models that can handle inter-class variations.2.2.2. Sensor Capabilities
In computer vision, a sensor detects and measures environmental properties such as light, temperature, pressure, and motion to convert them into electrical signals for computer processing [20][33]. Due to the capture of rich visual information, the RGB camera is the most common sensor used in video-based human action recognition, which senses the light intensity of three color channels (red, green, and blue) [4][20][4,33]. Using an RGB camera entails some challenges, including a reduced perspective due to the limited field of view [14][26], which may cause theour target to be partially or not present in the camera field; a partial temporal view of the target subject is known as occlusion [4][14][21][4,26,34] and can be caused either by an object, another subject, the same subject or even the light conditions. Dealing with missing information is difficult because the occlusion may hide the action’s representative features [14][26]. For example, if a player’s legs during a kick are not visible to the camera’s field of view throughout a soccer match, it can be challenging to establish if they made contact with the ball. Furthermore, there is no semantic of how to place the camera sensor, which implies that the target subject can appear in infinite perspectives and scales [22][35]. On the one hand, some perspectives may not help recognize an action [22][23][35,36]; for instance, when a person is reading a book, they will usually hold it in front of them; if the camera viewpoint is the subject’s back, it will not perceive the book, and therefore, it will not be able to recognize the action.2.2.3. Environment Conditions
Environmental conditions can significantly impact the classification accuracy of a model to recognize human actions by affecting the significance of the captured data [4][14][4,26]. To illustrate, poor weather conditions such as rain, fog, or snow reduce the target subject’s visibility and affect the appearance features extracted. Likewise, in “real” conditions, the target subject will find itself in a scene with multiple objects and entities, which will cause a dynamic, unpredictable, and non-semantic background [14][26]; the delineation and comprehension of the objective and background can become increasingly complex and challenging when additional factors or variables are presented, which obscure the distinction between the foreground and background. Additionally, environmental conditions can generate image noise that limits representative visual features’ extraction and complicates the subject track over time [24][40]. The environment light is also critical in identifying human actions [14][26], primarily if the model approach only relies on visual data for feature representation. Lighting conditions can cause subjects to be covered by shadows, resulting in occlusions or areas of high/low contrast, making taking clear, accurate, and visual-consistent pictures of the target subject complex. These circumstances may also result in images differing from those used during model training, confounding the recognition process even further.2.2.4. Dataset Restrictions
The effectiveness of a machine learning model for recognizing human actions heavily depends on the dataset’s quality used in its training phase [25][41]. The dataset’s features, such as the number of samples, diversity, and complexity, are crucial in determining the model’s performance. However, using a suitable dataset to boost the model’s accuracy takes time and effort [26][42]. The first approach is constructing the dataset from scratch, ensuring the action samples fit the application’s requirements. However, this process can be resource-intensive [26][42] because most effective machine learning models work under a supervised methodology, and consequently, a labeling process is required [27][43]. Data labeling [27][43] involves defining labeling guidelines, class categories, and storage pipelines to further annotate each action sample individually, either manually or by outsourcing to an annotation service to ensure consistent and high-quality data samples. For some application domains, data acquisition can be challenging due to various factors [28][44], such as the unique nature of the application, concerns regarding data privacy, or ethical considerations surrounding the use of certain types of data [29][45]. Consequently, data acquisition can be scarce, insufficient, and unbalanced in the action classes, presenting significant obstacles to developing effective models or conducting meaningful analyses [28][44]. The second approach involves utilizing well-known datasets with a predefined evaluation protocol, enabling researchers to benchmark their methodology against state-of-the-art techniques. Nevertheless, there are some limitations, including the availability of labeled data; for example, the UCF101 [30][46] and HMDB51 [31][47] are one of the most used benchmark datasets [32][21]. Still, their data dimensionality is insufficient to boost the deep-learning model [33][48]. Furthermore, current datasets for action recognition face the challenge of adequately representing and labeling every variation of a target action [14][26], which is nearly impossible due to the immense variability in human movements and environmental factors. This limitation can impact the accuracy and generalizability of action recognition models if the dataset does not represent the same data distribution of the target application [14][26]. Another main problem with publicly available datasets is their degradation over time [14][26]; for example, a researcher that aims to use the kinetics dataset [33][48] must download each video sample from the Internet. However, some download links may no longer work, and specific videos may have been removed or blocked. As a result, accessing the same dataset used in prior research is impossible, leading to inconsistent results [14][26]. Most of the datasets provide the video along with a textual label tag [34][13]. Although this is enough to train a model to recognize human action, they have two main limitations. On the one hand, there is no clear intuition that text label tags are the optimal label space for human action recognition [35][49], particularly in cases where a more nuanced or fine-grained approach to labeling is required or in an application scenario where multi-modal information is available [34][13]. On the other hand, the exclusive use of RGB information in current datasets overlooks the potential benefits of other input sensors [36][24], such as depth or infrared sensors, which may provide more detailed and complementary representations of human actions in specific application scenarios.3. The Evolution of Video-Based Human Action Recognition Approaches
3.1. Handcrafted Approaches
As described in Figure 2, handcrafted approaches established the foundation for video-based human action recognition, which entails a manual feature engineering process, where human experts manually design features that support a computer to understand.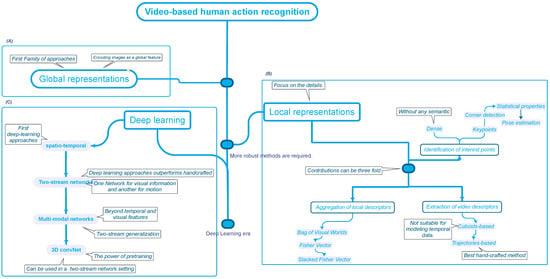
Figure 2. The Evolution of Action Recognition Approaches. The initial attempt at vision-based human action recognition relied on global representations (A), which were inferior to local representations (B). Lastly, deep learning approaches (C) became the most popular, with 3D convolutional neural networks becoming the most advanced because they can learn multiple levels of representations.