Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Pummy Dhiman and Version 2 by Sirius Huang.
The unregulated proliferation of counterfeit news creation and dissemination poses a constant threat to democracy. Fake news articles have the power to persuade individuals, leaving them perplexed. State of the art in deep learning techniques for fake news detection are described herein.
- fake news detection
- deep learning
1. Fake News Detection Using Artificial Intelligence
A bibliometric study on 479 academic articles on fake news that were indexed in the Web of Science database was carried out using VOSviewer software [1][34]. There are three topologies provided: misinformation, mal-information, and disinformation [2][38]. Despite having similar sounds, these terms differ in some ways. Misinformation [2][3][4][21,36,38] is the unintentional dissemination of false information. It is not intended to deceive others. As an example, during COVID-19 times, the internet was inundated with information regarding precautions and home remedies. In contrast, disinformation [5][6][39,40] involves spreading bogus information with the intention of deceiving others. Contrarily, “misinformation” [7][41] is information that is grounded in reality but is utilized to hurt a victim, group, organization, or nation, e.g., revenge porn. It is recommended that further research be conducted on misinformation.
In order to focus on the use of an interdisciplinary approach contributing to scholarship and to comprehend the role of mobile and social media, as well as how the outcome of the 2016 US Presidential Election pushed the research community toward fake news detection, the authors in [4][36] used Google Scholar to examine 142 academically published articles. Google Scholar automatically keeps track of new articles as they are posted online. It has been found that prospective examiners should pay more attention to how people create, consume, and spread false information. To ascertain how the term “fake news” came to be a search subject, another bibliometric study explored 640 scientific articles that were taken from the WoS database [8][37]. These chosen articles were analyzed using Excel, SciMAT, and VOSviewer for scientific mapping. The authors came to the conclusion that educational practices must be promoted to stop the spread of false information.
Fake news goes by many names. The authors in [9][42] evaluated 387 fake news-related papers published on WOS between 2000 and 2019 to determine the overlap of and differences among phrases. They also recorded the distribution of publication years, author nations, and publications associated with these studies. This fake news study had nothing to do with people’s views, fact-checking, or research on disinformation. Some studies on misinformation [10][19] simply discussed misinformation in their research fields.
Because traditional and online media were inundated with information about COVID-19, the WHO dubbed it an “infodemic”. In 2020, one in six COVID-19 information pieces produced in India were false, making India the country from which the majority of COVID-19 false information originated [5][11][7,39]. Consequently, in January 2021, a concept map was created using 414 entries in the Web of Science (WoS) database, utilizing issues relevant to infodemics, misinformation, and disinformation to map the related literature [12][20]. Future research is also proposed with regard to useful research questions.
The rise of online media has hastened the spread of rumors and propaganda. Because these are forms of fake news, researchers have been motivated to work in this field. Some studies conducted bibliometric reviews to get a more in-depth look at this topic. The authors in [7][41] conducted an empirical study of peer-reviewed articles published in the WoS database from 1965 to 2019 and concluded that, despite an increase in publications and citations, propaganda cannot be considered an autonomous research field. Similarly, the authors in [11][7] used CiteSpace software to conduct a bibliometric review of 970 articles from the WoS database from 1989 to 2019 and concluded that rumors are spreading more quickly as a result of the development of various social networking platforms.
2. Deep Learning in Fake News Detection
Recent years have seen an explosion of research on fake news detection, which has resulted in numerous studies in the field. In the past, research on fake information detection focused on two main approaches: (a) categorizing false news in the context of unimodality (textual or visual); (b) exploiting multimodality (textual and visual) [13][43]. An overview of the use of DL in fake news detection is shown in Figure 12.
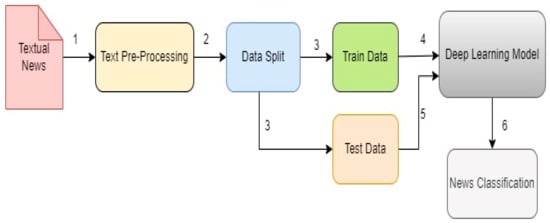
Figure 12.
DL in news classification.
As it is known, computers cannot understand human language, and users express themselves in human language; thus, a subfield of AI known as NLP has emerged to fill this void. It enables machines to understand human communication languages. As a result, before using ML or DL, data should be preprocessed with NLP. The dataset is split into training and testing after this preprocessing step (2). A deep learning model is modeled using the training set (step 4), while it is tested using the test set (step 5). Finally, in step 6, news is classified as either true or false.
Researchers from all over the world have helped to tackle the problem of fake news. An AI model using NLP and conventional ML was created to categorize classified text as fake news [9][42]. Experiments were carried out using the Kaggle dataset and articles pulled from the internet. When compared to other ML and DL models, the findings showed that random forest and CNN with global max pooling had high accuracy. Machine learning models were found to be roughly 6% less accurate than neural network models.
To indicate that people are more likely to forward news items immediately if the content is novel and emotionally appealing [13][43], the authors in [14][44] used a multilayer perceptron (MLP) neural network and a novelty and emotion-based representation of news to countermeasure the spread of fake news. During COVID-19 times, the internet was flooded with information related to home remedies and precautions; then, due to care, love, and fear of losing their loved ones, people shared this information through social media without checking whether it was true or false. This is how the spread of misinformation happens [15][45]. To implement this approach, four datasets were used, and statistically significant improvements in accuracy were recorded [14][44]. A hybrid DL framework (BerConvoNet) proposed by [16][46], combining BERT and CNN based on the news embedding block (NEB) and multiscale feature block (MSFB), was used to classify whether a given news article is genuine or not. However, it is yet to be explored how multimodal learning works.
A deep triple network (DTN) along with an entity-based attention network (EAN) developed in [17][47] can not only detect if a news article is true or false but also explain why it is. In this direction, the authors in [18][48] also attempted to work on a BERT-based model using two explanation methods, LIME [19][49] and Anchors, with the goal of detecting fake news while also attempting to explain it. The results supported the use of multiple surrogate-type methodologies to derive explanations using the Kaggle dataset, containing 44,848 news items. Because Anchors were not always able to provide an explanation, other explainability methods [7][9][41,42] will be applied in the future.
Another approach to solving the problem of falsified news was investigated in [20][50], i.e., a triple-branch BERT network for both binary and multilabel classification of fake news. Two datasets, LIAR and LIAR PLUS, were deployed; as compared with previously explored models, the accuracy was improved significantly using binary classifiers, but only marginally using multilabel classifiers.
GANs [14][15][44,45] are popular for content synthesis, i.e., for creating deep fakes. They consist of two architectures, a generator and a discriminator, competing against each other in multiple iterations to create more realistic content and to distinguish it from real content. In this context, a comprehensive review [21][51] was performed to analyze and identify existing approaches to deep fake creation and detection. Various deep fake tools such as Faceswap, DFaker, FSGAN, StyleGAN, and Face2Face, in addition to existing solutions based on the ML and DL techniques CNN, LSTM, RCN, and VGG16, as well as ResNet models and existing databases, were discussed.
To differentiate between fake (spoof) and real (bona fide) speech, a solution based on classical supervised learning pipeline was proposed [22][52]. The publicly available ASVspoof 2019 dataset was used to validate the proposed method. The authors of [23][53] used the FakeAVCeleb dataset to demonstrate that the ensemble-based method outperformed multimodal methods for detecting deep fakes of multiple modalities, i.e., video and audio. Along with deep fake movies, this collection also contained fake audio that was created artificially.
Examining the liaison between text and visual information made use of the cosine similarity notion. The processing of picture data was performed using a trained image2sentence model, and the representation of text representations was performed using a text-CNN with an additional fully connected layer [24][54]. F1 scores of 89.6% and 89.5% were recorded for the PolitiFact and GossipCop datasets, respectively. The authors of [25][55] used the latent Dirichlet allocation (LDA) to model online posts for fake news detection in an Indian context. Images were analyzed using VGG16 and Resnet-50, while text was analyzed using several ML and DL models. The implementation showed 74% accuracy.
To detect fake news, the authors created SpotFake [26][56]: a multimodal framework that combines language models with a VGG-19 model pretrained on ImageNet to incorporate contextual information. Using the concatenation technique, text and visual features were combined to form a multimodal fusion module. The investigation’s findings presented 77.77% and 89.23% accuracy on publicly available datasets Twitter and Weibo, respectively. Inspired by [26][56], the authors proposed SpotFake+ [27][57], an advanced version of SpotFake, where transfer learning was used to extract semantic and contextual information from lengthy news articles and images.