Data integrity is a prerequisite for ensuring data availability of IoT data and has received extensive attention in the field of IoT big data security. Stream computing systems are widely used in the field of IoT for real-time data acquisition and computing. The real-time, volatility, suddenness, and disorder of stream data make data integrity verification difficult. The data integrity tracking and verification system is constructed based on a data integrity verification algorithm scheme of the stream computing system (S-DIV) to track and analyze the message data stream in real time. By verifying the data integrity of message during the whole life cycle, the problem of data corruption or data loss can be found in time, and error alarm and message recovery can be actively implemented.
- data integrity verification
- stream computing
- internet of things
1. Introduction
-
Accuracy: Accuracy is a key consideration for stream real-time computing systems used in IoT. Only with a high level of accuracy and precision can the system be trusted by end users and be widely applied.
-
Real-time: Data sharing in IoT requires high timeliness; so, data integrity verification needs real-time. Since the tracking and verification system is built outside the stream computing system, integrity verification does not affect the efficiency of the original system. Meanwhile, the verification time is synchronized with stream computing, making it possible to trace and recover error messages as soon as possible.
-
Transparency: Different stream computing systems for IoT may have different topological frameworks, corresponding to different business and application interfaces; thus, the design of external tracking and verification systems should be transparent in order to achieve system versatility.
2. Data Integrity Tracking and Verification System
The detailed design of the external data integrity tracking and verification system of stream computing system is shown in Figure 1.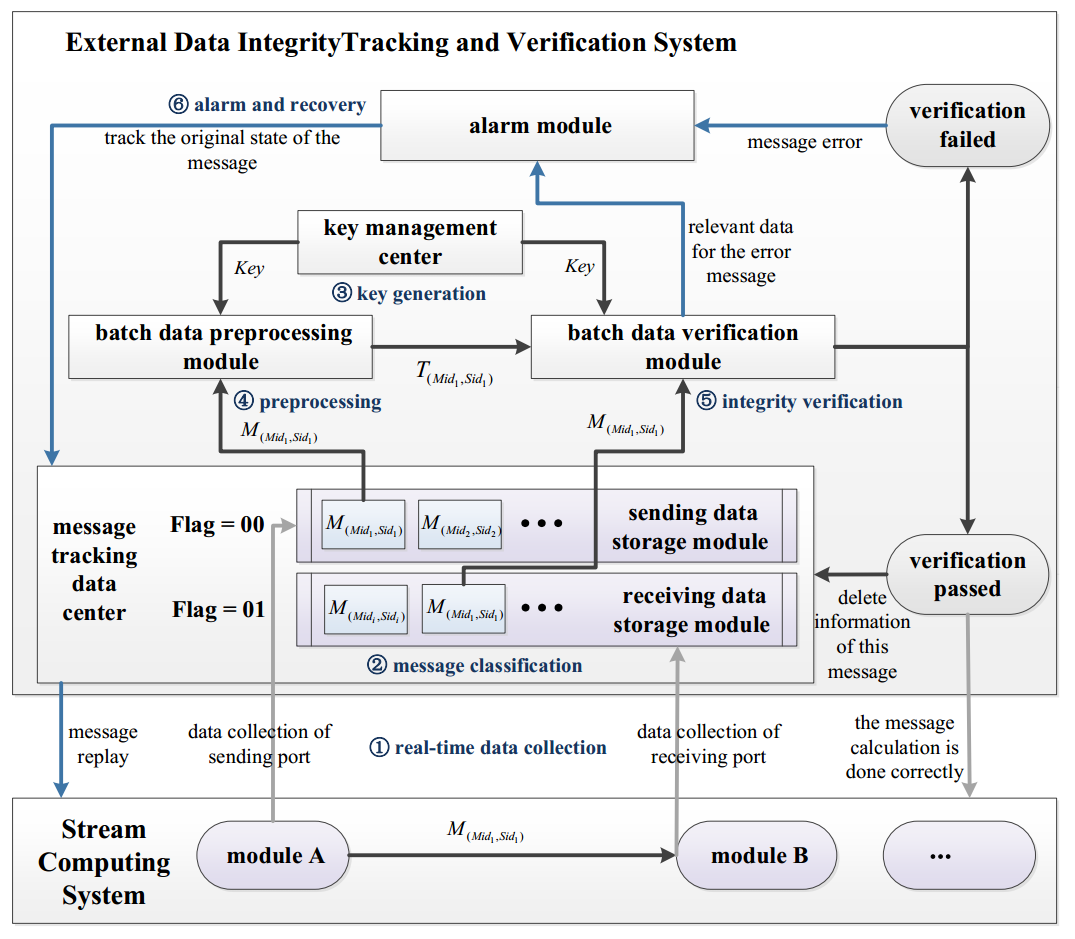 1. The phase of real-time data collection: When a message is sent from module A to module B, data collection is performed at the data sending port (module A) and the data receiving port (module B), and the collected message data are sent to the message tracking data center.
2. The phase of message classification: After the data center receives the collected message, it judges whether it is a sending message or a receiving message according to the Flag, the sending message (Flag = 00) will be put into the sending data storage module (i.e., sending module), and the receiving message (Flag = 01) will be put into the receiving data storage module (i.e., receiving module).
3. The phase of key generation: The key management center sends the pregenerated key to the batch data preprocessing module and the batch data verification module, respectively.
4. The phase of batch data preprocessing: The preprocessing module preprocesses the message data of sending module, calculates each message M(Mid1,Sid1), and generates a verification tag T(Mid1,Sid1); then, it sends the tag to the batch data verification module.
5. The phase of batch data integrity verification: The messages of receiving module are sent to batch data verification module. The batch data verification module verifies data integrity of the message one by one according to T(Mid1,Sidi) and M(Mid1,Sidi). Specifically, aggregate T(Mid1,Sidi) and M(Mid1,Sidi) according to Mid: aggregate and verify a set of messages fMgMid1= fM(Mid1,Sid1), M(Mid1,Sid2), M(Mid1,Sid3), . . .o with the same Mid and the corresponding series of tags fTgMid1= fT(Mid1,Sid1), T(Mid1,Sid2), T(Mid1,Sid3), . . .o. If the verification passes, the information will be sent to the message tracking data center
1. The phase of real-time data collection: When a message is sent from module A to module B, data collection is performed at the data sending port (module A) and the data receiving port (module B), and the collected message data are sent to the message tracking data center.
2. The phase of message classification: After the data center receives the collected message, it judges whether it is a sending message or a receiving message according to the Flag, the sending message (Flag = 00) will be put into the sending data storage module (i.e., sending module), and the receiving message (Flag = 01) will be put into the receiving data storage module (i.e., receiving module).
3. The phase of key generation: The key management center sends the pregenerated key to the batch data preprocessing module and the batch data verification module, respectively.
4. The phase of batch data preprocessing: The preprocessing module preprocesses the message data of sending module, calculates each message M(Mid1,Sid1), and generates a verification tag T(Mid1,Sid1); then, it sends the tag to the batch data verification module.
5. The phase of batch data integrity verification: The messages of receiving module are sent to batch data verification module. The batch data verification module verifies data integrity of the message one by one according to T(Mid1,Sidi) and M(Mid1,Sidi). Specifically, aggregate T(Mid1,Sidi) and M(Mid1,Sidi) according to Mid: aggregate and verify a set of messages fMgMid1= fM(Mid1,Sid1), M(Mid1,Sid2), M(Mid1,Sid3), . . .o with the same Mid and the corresponding series of tags fTgMid1= fT(Mid1,Sid1), T(Mid1,Sid2), T(Mid1,Sid3), . . .o. If the verification passes, the information will be sent to the message tracking data centerand the stream computing system, and the intermediate data in the two caches will be deleted; if the verification fails, the message alarm and recovery will be carried out. 6. The phase of alarm and recovery: When the alarm module receives the error information, it calls out the error message from the batch data verification module and resends the error message to the message tracking data center according to the Mid and Sid. The data center finds out the original message and sends it to the stream computing system. Finally, the stream computing system replays and recalculates the message according to the original route.
References
- Tan, S.; Jia, Y.; Han, W.H. Research and Development of Provable Data Integrity in Cloud Storage. J. Comput. 2015, 38, 164–177. (In Chinese)
- Sun, D.W.; Zhang, G.Y.; Zheng, W.M. Big Data Stream Computing: Technologies and Instances. Ruan Jian Xue Bao J. Softw. 2014, 25, 839–862. (In Chinese)
- Storm Acker. Available online: https://www.cnblogs.com/DreamDrive/p/6671194.html (accessed on 28 August 2022).