Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Ayman El-Baz and Version 2 by Catherine Yang.
Hepatocellular carcinoma (HCC) is the most common primary hepatic neoplasm. Thanks to recent advances in computed tomography (CT) and magnetic resonance imaging (MRI), there is potential to improve detection, segmentation, discrimination from HCC mimics, and monitoring of therapeutic response. Radiomics, artificial intelligence (AI), and derived tools have already been applied in other areas of diagnostic imaging with promising results.
- deep learning
- machine learning
- AI
- computed tomography
1. Artificial Intelligence (AI)
The term “artificial intelligence (AI)” refers to the computational capacity to carry out tasks that are comparable to those carried out by humans, with varying degrees of autonomy, to process unique raw data (inputs) and produce useful information (outputs) [1][5]. While the foundations of AI were laid decades ago, it was not until the advent of modern powerful computational technology, coupled with the ability to capture and store massive data quantities, that it became possible to realize AI capabilities in the tasks most important to radiology, such as pattern recognition/identification, preparation, object/sound recognition, problem-solving, disease prognostication, assessing the necessity of therapy, and providing patients and clinicians with prognostic data on treatment outcomes. Despite the fact that healthcare is a daunting area in which to apply AI, medical image analysis is becoming a very important application of this technology [2][6]. From the outset, it has been obvious that radiologists could benefit from the powerful capabilities of computers to augment the standard procedures used for disease detection and diagnosis. The use of computer-aided diagnosis (CAD) systems, which were forerunners to modern AI, has been encouraged to help radiologists detect and analyze potential lesions in order to distinguish between diseases, reduce errors, and increase efficiency [3][7]. As the nature of CAD systems is that they are tailored to a specific task, their variable reliability and the possibility of false positive results require that a qualified radiologist confirm CAD findings [3][7]. Consequently, continuous efforts are being made to improve the efficiency and accuracy of CAD and to promote the assistance that it can offer in routine clinical practice. The development of artificial neural networks (ANN) in the middle of the 20th century [4][8] and their subsequent progression, which has brought forth the concepts of machine learning (ML), deep learning (DL), and computational learning models, are the primary reasons for the rise of AI.
Machine learning (ML) is one of the most important applications of AI. The training process, in which computer systems adapt to input data during a training cycle [5][9], is the cornerstone of ML. Such models require large amounts of high-quality input data for training. The creation and use of large datasets structured in such a way that they can be fed into an ML model are sometimes referred to as “big data”. Through repeated training cycles, ML models can adapt and improve their accuracy in predicting correct data labels. When an appropriate level of accuracy is achieved, the model can be applied to new cases which were not a part of the training stages [6][7][10,11]. ML algorithms can be either supervised or unsupervised, depending on whether the input data are labeled by human experts or unlabeled and directly categorized by various computational methods [6][8][10,12]. An optimal ML model should include both the most important features needed to generate desired outputs and the most generic features that can be generalized to the general population, even though these features may not be defined in advance. Pattern recognition and image segmentation, in which different meaningful regions of a digital image (i.e., pixels or segments) are identified, are two common ML tasks in radiology. Both have been successfully used for a variety of clinical settings, diseases, and modalities [9][10][11][13,14,15].
Deep learning (DL) is a subtype of ML which uses multilayered artificial neural networks (ANNs) to derive high-level features from input data (similar to neuronal networks) and to perform complex tasks in medical imaging. Specifically, DL is useful in classification tasks and in automatic feature extraction, where it is able to solve the issues of partial detectability and feature accessibility when trying to extract information from these valuable data sources. The use of multilayered convolutional neural networks (CNNs) improves DL robustness by mimicking human neuronal networks in the training phase. If applied to unlabelled data, the automatic process of learning relies on image features being automatically clustered based on their natural variability. Due to the challenge of achieving completely unsupervised instruction, complex learning models are most commonly implemented with a degree of human supervision. The performance of CAD can be increased using ML and CNNs. CAD systems utilizing ML can be trained on a dataset from a representative population and then identify the features of a single lesion in order to classify it as normal or abnormal [12][16]. Algorithms based on statistics are the major focal point of both supervised and unsupervised learning [13][17]; however, there are important variations. Classification (i.e., categorizing an image as normal or abnormal based on labels provided in the training data) and regression (observing or finding new categories using inference on training sets) are the two main applications of supervised learning. Unlike supervised learning, unsupervised models use unlabelled/unclassified data. As a result, latent pattern recognition is accomplished through dimensionality reduction and feature clustering [13][17]. To determine the usefulness of this classification process, it must first be validated. The capacity to link basic diagnostic patterns and features of medical image modalities to a specific pathological and histological subtyping has led to the area of radiomics by merging DL-based image processing with clinical, and when suitable, pathological/histological data [14][15][16][18,19,20].
2. Radiomics
Radiomics is a recent translational field in which a variety of properties, including geometry, signal strength, and texture, are extracted from radiological images in order to record imaging patterns and categorize tumor subtypes or grades. Radiomics is typically utilized in systems with various variants for prognosis, monitoring, and determining how well a treatment is working [15][17][19,21]. “Images are more than pictures; they’re data.” The basic concept of radiomics is beautifully illustrated by Robert Gillies and colleagues’ intuitive and precise description [18][4]. Radiomics is classified into two types, namely, feature-based and DL-based radiomics, and is commonly used to analyze medical images at a low computational cost. While clinical evaluations are subject to inter-observer variability, results using radiomics are more accurate, stable, and reproducible, as automated radiomic characteristics are either generated statistically from ML-based complicated computational models during the training phases (DL-based) or computed using mathematical methods (feature-based). However, in order to achieve a correct diagnosis, the input data must be of high quality, with accurate labels (in the case of supervised learning) or a population-representative sample (in the case of unsupervised learning) [19][22].
2.1. Feature-Based Radiomics
In order to perform feature-based radiomics, a segmented volume of interest (VOI) for 3D data or region of interest (ROI) for 2D data is used. In order to avoid overfitting (an erroneous reliance on clinically irrelevant features), feature selection algorithms examine a subset of certain features after feature extraction and create robust prediction models. Overfitting usually occurs in datasets that are too homogeneous and lack enough representations of the target diseases. As a result, the chosen features may not be valid when applied to different data sets. Selecting features from heterogeneous and representative datasets decreases the likelihood of selecting narrowly applicable features and reduces the risk of overfitting. Feature-based radiomics does not necessitate large datasets, as the features are typically defined after only a short computation time. Notably, the majority of extracted features are very complex, and often do not correlate to recognizable pysiological or pathological features, limiting model interpretability. The feature-based radiomics process contains the key processing stages listed below.
Image pre-processing is a basic step in radiomics in which useful features are extracted. The primary goal of radiomics is the generation of quantitative features from radiology images [18][19][20][21][22][23][4,22,23,24,25,26]. The generated features and models should be both repeatable and general, particularly when using multi-variate multi-model data (i.e., with different scanners, modalities, and acquisition protocols), which is the case for most medical imaging centers. Several pre-processing steps are necessary to achieve these objectives. Correcting inhomogeneities in MRI images, reducing noise, spatial resampling, spatial smoothing, and intensity normalization are all common pre-processing steps for radiomic analyses [15][24][25][19,27,28].
Tumor segmentation is another extraction step in feature-based radiomics. Segmentation of MR or CT images for different types of tumors is typically performed manually, either in preparation for ML model development or in clinical practice for planning of radiotherapy or volumetric evaluation of treatment response [23][26]. It takes a great deal of effort to carry out 3D manual segmenting of lesions that have necrosis, contrast enhancement, and surrounding tissue. The contours have a direct effect on the radiomics analysis results, as the segmented ROIs define the input for the feature-based radiomics process. To handle this challenge, ML approaches are being developed for automatic tumor localization and segmentation [26][27][29,30].
Feature extraction from medical images may lead to several quantitative traits, the majority of which are tumor heterogeneity. Although many features can be extracted, features are typically divided into four subgroups:
-
Filter methods (univariate methods) examine how features and labels are related without taking into account their redundancy, or correlation. Minimum redundancy maximum significance, Student’s t-test, Chi-squared score, Fisher score, and the Wilcoxon rank sum test are among the most commonly used filter methods. While these feature selection methods are widely used, they do not take the associations and interactions between features into account [30][31][33,34].
-
Wrapper methods (multivariate methods), known as greedy algorithms, avoid the filter method constraint by looking at the entire space of features and considering the relationships between each feature and other features in the dataset. A predictive model is used to evaluate the output of a group of features. The consistency of a given technique’s output is used to test each new subset of features. Wrapper approaches are computationally intensive, as they strive to find the best-performing functional group of features. Forward feature selection, backward feature exclusion, exhaustive feature selection, and bidirectional search are all examples of wrapper methods [30][31][33,34].Second-order statistical features or textural features are statistical relationships between the signal intensity of adjacent pixels/voxels or groups of pixels or voxels. These features serve to quantify intratumoral heterogeneity. Textural features are created by numerically characterizing matrices that encode the exact spatial connections between the pixels/voxels in the source image. The gray-level co-occurrence matrix (GLCM) [28][31] is the most widely used texture analysis matrix. The GLCM shows how many times two intensity levels appear in adjacent pixels or voxels within a given distance and in a defined direction. Multiple textural characteristics, including energy, contrast, correlation, variance, homogeneity, cluster prominence, dissimilarity, cluster inclination, and maximum likelihood, can be measured using the GLCM. The difference in intensity levels between one pixel/voxel and its 26-pixel 3D neighborhood is represented by the neighborhood gray-level different matrix (NGLDM). For each image intensity, the gray-level run length matrix (GLRLM) encodes the size of homogeneous runs [29][32]. Long-run emphasis (LRE), short-run emphasis (SRE), low gray-level run emphasis (LGRE), run percentage (RP), and high gray-level run emphasis (HGRE) can all be derived from the GLRLM. There are other matrices that capture pixel-wise spatial relationships and can be used to compute additional texture-based features [28][31].
-
Higher-order statistical features are quantified using statistical methods after applying complex mathematical transformations (filters), such as for pattern recognition, noise reduction, local binary patterns (LBP), histogram-oriented gradients, or edge enhancement. Minkowski functionals, fractal analysis, wavelet or Fourier transforms, and Laplacian transforms of Gaussian-filtered images (Laplacian-of-Gaussian) are examples of these mathematical transformations or filters [25][28].
Feature selection is a helpful step used to refine the set of extracted features. For implementation of image-based models for prediction and prognosis, the extracted quantitative features might not have equal significance. Redundancy, overly strong correlation, and feature ambiguity can cause data overfitting and increase image noise sensitivity in the dependent predictive models. Overfitting is a methodological error in which the developed model is overly reliant on features specific to the radiological data used in the training process (i.e., noise or image artifacts) rather than features of the disease in question. Overfitting results in a model with deceptively high classification scores on the training dataset and weak performance on previously unseen data. One way to reduce the risk of overfitting is to employ feature selection prior to the learning phase [5][9]. Supervised and unsupervised feature selection techniques are widely used in radiomics. Unsupervised feature selection algorithms disregard class labels in favor of eliminating redundant spatial features. Principal component analysis (PCA) and cluster analysis are widely used techniques for this type of feature selection [15][19]. Despite the fact that these approaches minimize the risk of overfitting, they seldom yield the best feature subset. Supervised feature selection strategies, on the other hand, consider the relations between features and class labels, which results in the selection of features based on how much they contribute to the classification task. In particular, supervised feature selection procedures select features that increase the discrimination degree between classes [23][26]
- Embedded approaches carry out the feature selection process as part of the ML model’s development; in other words, the best group of features is chosen in the model’s training phase. In this way, embedded approaches incorporate the benefits of both the filter and wrapper methods. Embedded approaches provide more reliability than filter methods, have a lower execution time than wrapper methods, and are not very susceptibility to data overfitting, as they take into account the interactions between features. The least absolute shrinkage and selection operator (LASSO), tree-based algorithms such as the random forest classifier, and ridge regression are examples of commonly used embedded methods
Model generation and evaluation is the final step in feature-based radiomics. Following feature selection, a predictive model can be trained to predict a predetermined ground truth, such as tumor recurrence versus tissues changes related to treatment. The most commonly used algorithms in radiomics include the Cox proportional hazards model for censored survival data, support vector machines (SVM), neural networks, decision trees (such as random forests), logistic regression, and linear regression. To avoid overfitting of ML models when using supervised methods, datasets are usually split into training and validation subsets to ensure that these subsets maintain a sample distribution similar to the class distribution; this is particularly important for small or unbalanced datasets. After training and validating the model, a previously unseen testing subset of data is introduced to test the model. Optimally, the testing data should be similar to the actual data that the model will work on in real clinical settings, and should be derived from a different source (e.g., a different institution or instrument) than the training data. As a consequence, when testing a model’s performance, robustness, and reliability, the testing dataset is the gold standard. Alternatively, statistical approaches such as cross-validation and bootstrapping can be used for model output estimation without using an external testing dataset, particularly for small datasets.
2.2. DL-Based Radiomics
ANNs that mimic the role of human vision are used in DL-based radiomics to automatically generate higher-dimensional features from input radiological images at various abstraction and scaling levels. DL-based radiomics is particularly useful for pattern recognition and classification of high-dimensional and nonlinear data. The procedure is radically different from the one described above. In DL-based radiomics, medical images are usually analyzed using different network architectures or stacks of linear and nonlinear functions, such as auto-encoders and CNNs, to obtain the most significant characteristics. With no prior description or collection of features available, neural networks automatically identify those features of medical images which are important for classification [32][35]. Across the layers of a CNN, low-level features are combined to create higher-level abstract features. Finally, the derived features are used for analysis or classification tasks. Alternatively, the features derived from a CNN can be used to generate of other models, such as SVM, regression models, or decision trees, as is the case when using feature-based radiomic approaches. Feature selection is seldom used, because the networks produce and learn the critical features from the input data; instead, techniques such as regularization and dropout of learned link weights are used to avoid overfitting. Compared to feature-based radiomics, larger datasets are required in DL-based radiomics due to the high correlation between inputs and extracted features, which limits its applicability in many research fields that suffer from restrictions in data availability (such as neuro-oncological studies). Notably, the transfer learning approach can be used to circumvent this obstacle by employing pre-trained neural networks for a separate but closely related purpose [33][36]. Leveraging the prior learning of the network can achieve reliable performance even with limited data availability. These two types of radiomics and their different steps are illustrated in Figure 12.
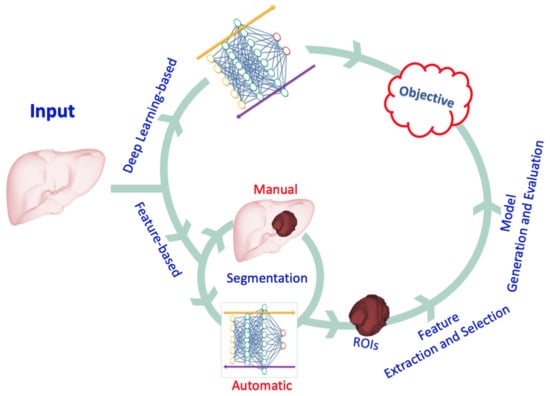
Figure 12.
An illustration of the different types of radiomics and the steps involved.
3. Clinical Application of AI and Radiomic Techniques in Liver Cancer
Hepatocellular carcinoma (HCC), the most prevalent form of liver cancer, develops in the hepatocytes, the primary type of liver cell. Hepatoblastoma and intrahepatic cholangiocarcinoma are two significantly less frequent kinds of liver cancer. Because HCC is the most prevalent form of liver cancer, different AI and radiomics techniques can be used for HCC segmentation, detection, and management.