Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Shahriar Shakir Sumit and Version 4 by Amina Yu.
Human detection is a special application of object recognition and is considered one of the greatest challenges in computer vision. It is the starting point of a number of applications, including public safety and security surveillance around the world. Human detection technologies have advanced significantly due to the rapid development of deep learning techniques. Convolutional neural networks (CNNs) have become quite popular for tackling various problems, among which includes object detection.
- computer vision
- object detection
- human detection
1. Introduction
Human beings possess an inherent ability to perceive surrounding objects in static images or image sequences almost flawlessly. They can also sense emotions and interactions among persons and notice the total persons present in images by making mere observations. The computer vision field is expected to provide the required technological assistance for this human aptitude in order to improve the quality of life of humans. Hence, the aim of this field is to explore methods for effectively teaching machines or computers to observe and understand characteristics in images or videos using digital cameras [1].
A precise detection of objects in an image is essential in computer vision in order to suit the demands of various applications involving vision-based approaches. For instance, object detection includes the identification of specific details in an image, and localizing its coordinates is considered to be a problem in vision technology. Identifying objects is not the only task that requires performance but categorizing them accordingly across various classes in an appropriate manner is also required [2]. A classic example of this includes visual object detection [2]. Figure 1 illustrates the basic operation of a machine learning (ML) model for detecting objects. For example, consider the goal of classifying three dissimilar objects: a bird, a human being, and a lion. Initially, training images are collected with labeled data in preparation for training an ML framework. Secondly, the desired features are extracted and then added to the classifier’s architecture.
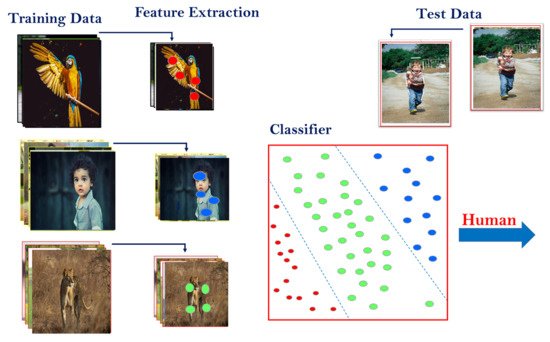
Figure 1.
Example of machine learning work flow for object classification across three different classes (bird, human, and lion).
Certain features can be best expressed by utilizing various object characteristics that include colors, corners, edges, ridges, and regions or blobs [3]. The success achieved from training is directly proportional to several factors that include feature extraction, classifier selection, and the training procedure. The first task is important as it not only enhances the accuracy of trained networks but also eliminates redundant features in the image. It involves reducing the dimensionality of data by extracting redundant information, which in turn improves the quality of inference while simultaneously improving the training rate. An ideological view is to expect features to be invariable in the control of dynamic and illuminated conditions while possessing the capability to cope with any randomized variations during either scaling or rotational motions. Features are appended to the training framework after all feasible features from the image samples have been extracted. They are then supplied to an appropriate sort of classifier based on accuracy and speed. Some normally used classifiers exist, which include the Support Vector Machines (SVM), Nearest Neighbor (NN), Random Forest (RF), and Decision Tree (DT). Once the training framework is ready, removing alike features from the test image samples and, as a consequence, predicting the proper class from features using the trained framework for each provided test image are feasible.
Several techniques were proposed in light of the efficient extraction of features as well as classification to detect arbitrary objects in images [4]. Over the past two decades, the focus had been on the design of efficient hand-crafted features to improve detection robustness and accuracy. A diverse set of extraction techniques was provided by the vision research community such as Scale Invariant Feature Transform (SIFT), Viola Jones (VJ), Histogram of Oriented Gradients (HoG), Speeded Up Robust Features (SURF), and Deformable Part-Based Models (DPM) [5][6][5,6].
Deep learning techniques have effectively combined the task of extracting the features and classification in an end-to-end way [4]. Convolutional neural networks (CNNs) have become quite popular for tackling various problems, among which includes object detection. Subsequently, the performance of such architectures has led to a proliferation in both achievable speed and accuracy. The object detection methods using deep CNN such as Spatial Pyramid Pooling Networks (SPPNets), Region-based CNN (R-CNN), Feature Pyramid Networks (FPNs), fast RCNN, You Only Look Once (YOLO), faster R-CNN, Single-Shot Multibox Detector (SSD), and Region-based Fully Convolutional Networks (R-FCNs) have shown excellent benefits relative to state-of-the-art ML methods [7][8][7,8]. HereThin, it iss article focuses on a specific sub-domain of detection, which is the human detection.
In a year, over a billion people lost their lives and around 20–50 million people experienced fatal complications as a result of traffic accidents [9]. In 2015, more than 5000 pedestrians died in traffic accidents, while about 130,000 pedestrians required medical care for non-fatal problems in the United States. However, the ratio of traffic fatality can be reduced or even eliminated by utilizing various detection techniques in autonomous vehicles that use sensors to interact with other neighboring vehicles in the vicinity [10].
With increases in crime and public fear of terrorism, public security has become an unavoidable concern, and human detection techniques can be employed to monitor and control public spaces remotely. Approximately 21,000 people lose their lives because of terrorist activities every year and 0.05% of the total deaths in 2017 occurred due to terrorism [11]. The necessity to install a sufficient number of human-detecting devices has spiked in public locations following tragedies in London, New York, and other cities across the globe. Such incidents are critical enough and demand a robust design and global deployment of such systems. Hence, human-detection systems are observed as a viable answer for ensuring public safety and have become one of the most significant study fields today.
The detection of human beings is one of the key responsibilities in the field of computer vision. It is indeed difficult to identify human in pictures because of several background effects such as occlusions [12], illuminated conditions and background clutters [13]. Previous techniques have been unsuccessful in real-world scenarios for detecting humans, as they took a longer period of time for detection and yielded outcomes that were not sufficiently accurate due to distance as well as changes in appearance [6]. Therefore, a universal representation of objects still continues to remain an open challenge in midst of such factors. Human detection is currently being utilized for many applications. Human detection is in the early stages in a number of use cases including pedestrian detection, e-health systems, abnormal behavior, person re-identification, driving assistance systems, crowd analysis, gender categorization, smart-video surveillance, human-pose estimation, human tracking, intelligent digital content management, and, finally, human-activity recognition [6][14][15][16][17][6,14,15,16,17].
The deep CNN is a dense computing framework in and of itself. With a large number of parameters and higher processing loads, followed by high memory access, energy consumption increases rapidly, thereby making it impossible to adopt the method for compact devices with minimal hardware resources. A feasible approach is a compressive, deep CNN technique for real-time applications and compact low-memory devices, which reduces the number of parameters, the cost of calculation, and power usage by compressing deep CNNs [18].
Over the past few years, the construction of tiny and effective network techniques to detect objects has become a point of discussion in the field of computer vision research. Acceleration and compression techniques are related primarily to the compact configuration of network architecture [19], knowledge distillation [20], network sparsity and pruning [21], and network quantization [22]. Various studies on network compression have advanced network models: for instance, SqueezeNet [23], which is a fire module based architecture; MobileNets [24], a depthwise separable filters based architecture; and, finally, the ShuffleNet [25], a residual structure based network in which channel shuffle strategy and group pointwise convolution were incorporated.
Motivated by lightweight architectures, a novel compact model was proposed to detect humans for the portable devices that were absent in the current literature. Tiny-YOLO, which is the tiny version of the YOLO model, is used as the base architecture of this proposed model. YOLO is a faster and more accurate technique compared to other object detection models, and it has been enhanced since its first implementation, which includes v1-YOLO, v2-YOLO, and v3-YOLO. However, these architectures are not suitable for portable devices because of their large sizes and inability to maintain real-time performance in constrained environments. As mentioned, Tiny-YOLO is smaller than these models. However, it failed to achieve high accuracy, and speed remained unsatisfactory for low-memory devices.
2. State-of-the-Art Methods
Human detection is the process of identifying each object in a static image or image sequences that are regarded to be human. Human detection is widely acknowledged to have advanced through two different historical periods in recent decades: “conventional human detection period (before 2012)” and “deep learning-based detection period (after 2012)”, as illustrated in Figure 2.
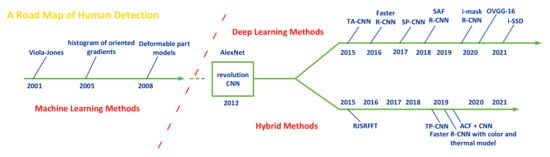
Figure 2.
Human-detection milestones.
Human detection is typically accomplished by extracting regions of interest (ROI) from an arbitrary image sample, illustrating the regions using descriptors, and then categorizing the regions as non-human or human, accompanied by post-processing processes [26][27].
In conventional techniques, human descriptors are generally designed by locally removing the features. A few examples include “edge-based shape features (e.g., [27][28])”, “appearance features (e.g., color [28][29], texture [29][30])”, “motion features (e.g., temporal differences [30][31])”, “optical flows [31][32]”, and their combinations [32][33]. Most of their functions are manually designed, which benefit from the ease of description and intuitively comprehending them. In addition, they were shown to perform well with limited collections of training datasets.
The Deformable Part-based Model (DPM) is the earlier state-of-the-art approach for detection process [33][34]. DPM is considered an extension of the histograms of the oriented gradients (HOG) model. The projected object is scored using the entire image’s coarse global template as well as the six higher-resolution portions of the object. HOG is used to characterize every single input. Following this approach, HOG’s multi-model can address the varying viewpoint problem. In the training phase, a latent support vector machine (latent SVM) was employed to decrease the detection drawback relative to the classification area. The coordinates of the component are considered as the latent element. This approach resulted in a massive impact due to its robustness.
Manually described features on the other hand, are unable to present more detailed information about the objects. In particular, they were challenged by the background, occlusion, motion blur, and illumination conditions. Hence, deep learning algorithms are regarded as relatively more efficient in human detection because they can learn more sophisticated features from images [34][35][36][35,36,37]. Although these initial deep algorithms have demonstrated some improvements over the classical models, these functions are still constructed manually, and the key concept is to expand the earlier models. Deep CNNs are also applied for the feature extraction in a few studies, for example [37][38]. A complexity perception cascade training for human detection was performed followed by the extraction of features.
Deep learning approaches are currently being used to address many identification problems in several ways. One of the most promising architectures is the Convolutional Neural Network (CNN). Deep CNNs can learn object features on their own; thus, they depend less on the object’s classes. Training a class-independent method, contrastingly, means that more data will be used for learning as deep learning requires a significant volume of data relative to training a domain-specific method. Only a few articles have been published in the field of human detection using the CNNs method. Tian et al. [38][39] employed a CNN to learn human segmentation characteristics (e.g., hats and backpacks), but the network component leads to boosting the prediction accuracy by re-classifying the prediction item as negative or positive, rather than making predictions directly. Li et al. [39][40] included a sub-network relative to a novel network built on Fast R-CNN to deal with small-scale objects. Zhang et al. [40][41] straightforwardly examined a cross-class detection method (CNN), which involved faster R-CNNs performances on independent pedestrian detection, and came up with good findings. Among the three techniques, besides [38][39], which does not directly deal with detection, refs. [39][40][40,41] performed various experiments based on cross-class detection techniques. In [41][42], it wahe authors suggested that a a system based on the combination of “Faster R-CNN” and “skip pooling” to deal with human detection issues. The architecture of “Faster R-CNN’s region proposal network” is generalized to a multi-layer structure and finally combined with skip pooling. The skip pooling structure removes several interest regions from the lower layer and is fed to the higher layer, without considering the middle layer. In [42][43], the iaut had been hors had suggested that an enhanced mask R-CNN approach for real-time human detection that achieved 88% accuracy.
In [43][44], a deep convolutional neural network-based human detection technique was proposed using images that were used as input data to classify pedestrians and humans. The authors used the VGG-16 network was used as a as a backbone and the model had provided better accuracy on the “INRIA dataset”. In [44][45], the a duthors combined a deep learning model was combined wiith machine learning technique to achieve high accuracies with less computational time for human detection and tracking in real time. However, the model had a lower speed. In [45][46], it wahe authors suggested thst a sparse network-based approach for removing irregular features and the developed approach was applied to a kernel-based architecture to reduce nonlinear resemblance across different features. This model, on the other hand, cannot be used for real-time detection and tracking.
H. Jeon et al. [46][47] resolved the human detection problem in extreme conditions by applying a deep learning-based triangle pattern integration approach. Triangular patterns are employed to derive more precise and reliable attributes from the local region. The extracted attributes are fed into a deep neural architecture, which uses them to detect humans in dense and occluded situation. In [47][48], K.N.Renu et al. proposed a deep learning-based brightness aware method to detect human in various illuminated conditions for both day and night scenarios. In [48][49], it ihe authors cascaded aggregate channel features (ACF) with the deep convolutional neural network for quicker pedestrian and human detection. Then, a hybrid Gaussian asymmetric function was proposed to define the constraints of human perception. In [49][50], it ihe authors proposed that a a single-shot multibox detector (SSD) could be used to detect pedestrians. The SSD convolutional neural architecture extracts low features and then combines them with deep semantic information in the convolutional layer. Finally, humans are identified in still images. In the suggested technique, pre-selection boxes with different ratios are used, which increased the detection capability of the entire model.