Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Faitouri A Aboaoja and Version 2 by Catherine Yang.
The evolution of recent malicious software with the rising use of digital services has increased the probability of corrupting data, stealing information, or other cybercrimes by malware attacks. Therefore, malicious software must be detected before it impacts a large number of computers. While malware analysis is taxonomy and linked to the data types that are used with each analysis approach, malware detection is introduced with a deep taxonomy where each known detection approach is presented in subcategories and the relationship between each introduced detection subcategory and the data types that are utilized is determined.
- malware detection and classification models
- malware analysis approaches
- malware detection approaches
1. Malware Analysis Approaches and Data Types
Malware analysis and the type of data have a considerable and growing impact on the detection process that determines the classification of the investigated file and therefore influences the overall accuracy of the detection models. Several types of data have been extracted using static, dynamic, and hybrid analysis, such as Byte code, Opcode, API calls, file data, registry data, and so on, to understand and acknowledge the major purpose and function of the files examined and therefore classify them as malware or benign files. Table 12 contains the characteristics of each reviewed paper in terms of the analysis approach and the extracted data.
Table 12.
The relation between analysis approaches and data types.
| Ref. | Date | String | PE-Header | Opcode | API Calls | DLL | Machine Activities | Process Data | File Data | Registry Data | Network Data | Derived Data | Accuracy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Entropy | Compression | |||||||||||||
| Static Analysis | ||||||||||||||
| [1][38] | 2015 | ✓ | 98.60% | |||||||||||
| [2][31] | 2015 | ✓ | 99.97% | |||||||||||
| [3][64] | 2016 | ✓ | 99.00% | |||||||||||
| [4][35] | 2018 | ✓ | ✓ | NA | ||||||||||
| [5][39] | 2017 | ✓ | 96.09% | |||||||||||
| [6][65] | 2017 | ✓ | 98.90% | |||||||||||
| [7][61] | 2017 | ✓ | 81.07% | |||||||||||
| [8][41] | 2018 | ✓ | NA | |||||||||||
| [9][32] | 2019 | ✓ | 99.80% | |||||||||||
| [10][33] | 2019 | ✓ | 87.50% | |||||||||||
| [11][42] | 2019 | ✓ | 97.87% | |||||||||||
| [12][66] | 2020 | ✓ | NA | |||||||||||
| [13][67] | 2019 | ✓ | 91.43% | |||||||||||
| [14][34] | 2016 | ✓ | ✓ | 89.44% | ||||||||||
| [15][36] | 2019 | ✓ | NA | |||||||||||
| [16][37] | 2019 | ✓ | ✓ | NA | ||||||||||
| [17][40] | 2020 | ✓ | ✓ | ✓ | NA | |||||||||
| [18][68] | 2016 | ✓ | ✓ | 98.17% | ||||||||||
| Dynamic analysis | ||||||||||||||
| [19][43] | 2015 | ✓ | 97.8% | |||||||||||
| [20][44] | 2016 | ✓ | 97.19% | |||||||||||
| [21][15] | 2016 | ✓ | 98.92% | |||||||||||
| [22][45] | 2016 | ✓ | ✓ | ✓ | 96.00% | |||||||||
| [23][52] | 2016 | ✓ | ✓ | NA | ||||||||||
| [24][69] | 2017 | ✓ | 98.54% | |||||||||||
| [25][47] | 2018 | ✓ | ✓ | NA | ||||||||||
| [26][49] | 2019 | ✓ | 92.00% | |||||||||||
| [27][54] | 2019 | ✓ | ✓ | 97.22% | ||||||||||
| [28][48] | 2019 | ✓ | 94.89% | |||||||||||
| [29][46] | 2020 | ✓ | 97.28% | |||||||||||
| [30][53] | 2019 | ✓ | ✓ | 75.01% | ||||||||||
| [31][70] | 2020 | ✓ | 98.43% | |||||||||||
| [32][51] | 2020 | ✓ | ✓ | ✓ | ✓ | ✓ | 99.54% | |||||||
| [33][71] | 2017 | ✓ | NA | |||||||||||
| Hybrid analysis | ||||||||||||||
| [34][72] | 2014 | ✓ | ✓ | 98.71% | ||||||||||
| [35][55] | 2016 | ✓ | ✓ | 99.99% | ||||||||||
| [36][73] | 2019 | ✓ | ✓ | 99.70% | ||||||||||
| [37][58] | 2021 | ✓ | ✓ | 94.70% | ||||||||||
| [38][74] | 2020 | ✓ | ✓ | ✓ | 93.92% | |||||||||
| [39][75] | 2020 | ✓ | ✓ | ✓ | ✓ | 96.30% | ||||||||
1.1. Static Analysis
The static analysis approach has been widely utilized by exploring the source code without running the executable files to extract a unique signature which is used to represent the file under investigation. Several types of static data can be collected via static analysis, including PE-header data [2][9][10][40][30,31,32,33], derived data such as string-based entropy and compression ratio [4][14][15][16][34,35,36,37]. Additionally, static analysis tools, such as IDA pro disassembler and Python-developed modules, are also used to collect static opcode and API calls [1][5][8][11][17][38,39,40,41,42]. Even though static analysis can track all the possible execution paths, it is influenced by packing and encryption techniques.
1.2. Dynamic Analysis
Several researchers performed a dynamic analysis approach to collect various data types to differentiate between malware and benign files by running the executable files in isolated environments, virtual machines (VM) or emulators to monitor the executable file behavior during the run-time and then collect the desired dynamic data [19][43]. Various kinds of data have been collected utilizing a dynamic analysis approach. Malicious activities can be dynamically represented using both executable file behavior and by retaining memory images during run-time. The executable files’ behaviors are identified through collecting the invoked API calls [20][22][25][28][29][44,45,46,47,48], machine activities [25][26][41][47,49,50], file-related data [23][30][32][51,52,53], and registry and network data [22][27][45,54]. Opcode-based memory image can be taken to represent the malicious activities dynamically [21][15]. Even though obfuscated malware cannot hide how it behaves when dynamically analyzed, dynamic analysis is unable to satisfy all malicious conditions in order to explore all execution paths.
1.3. Hybrid Analysis
Some previous studies combined data extracted through static and dynamic analysis together to reduce the drawbacks of both analysis approaches and achieve a higher detection rate. Different tools, including Cuckoo sandbox, IDA pro disassembler, and OlleyDbg, are employed to collect dynamic and static data, and then hybrid feature sets are created based on several types of data, such as string, opcode, API calls, and others [35][37][42][43][44][55,56,57,58,59]. Even though the hybrid analysis approach benefits from the advantages of both static and dynamic analysis, it also suffers from their disadvantages.
1.4. Malware Analysis and Data Types Discussion
The most used data types with each analysis approach have been shown in Figure 14. On the x-axis, the data types are depicted as string (St), PE-header (P-h), Opcode (Op), API calls (API), Dynamic link library (DLL), machine activities (MA), process data (PD), file data (FD), registry data (RD), network data (ND), and derived data (DD). Similarly, static, dynamic, and hybrid are mapped on the y-axis as analysis approaches. The horizontal and vertical dotted lines illustrate the relationship between each data type and each analysis approach by showing how frequently each single data type has been used with each particular analysis approach in the literature review.
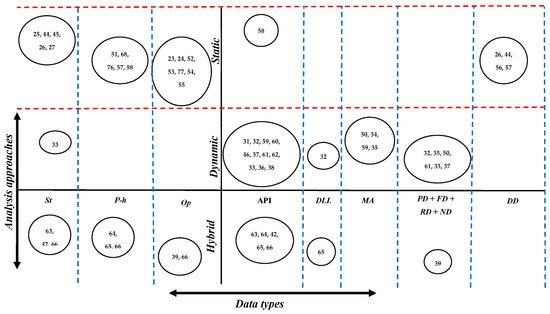
Figure 14.
Analysis approaches vs. data types.
By focusing on static analysis, opcode and PE-header represent the first and second most repetitively utilized static data types, respectively. This survey found that using the static data type that is employed in the minimum number of studies, the API calls that are collected statically were not preferable in the literature compared to the usage of byte-code data and the derived data. In contrast to static analysis, the API calls data demonstrates the most significant data type that has been extended using dynamic analysis. While machine activities data is the second trend data type, using data related to registry value, file, and network delivers the average ratio among studies that extracted their required data dynamically. Furthermore, bytecode, PE-header, and Opcode data are rarely extracted using dynamic analysis. In the studies that have utilized both static and dynamic analysis as hybrid analysis, it is clear to note that the same ranges are repeated for the data that are associated with static and dynamic analysis, such as Opcode, bytecode, and PE-header as static data and the API calls as dynamic data.
On the other hand, the usage ratio of some of the dynamic data, such as data related to files, registry, and machine activities, is decreased in the studies that choose hybrid analysis to extract their features.
Even though the static analysis is safe due to there being no need to run the files, malicious software frequently employs encryptors like UPX and ASP Pack Shell to prevent analysis. As a result, unpacking and decompression processes are required before analysis, which is accomplished with disassemblers such as IDA Pro and OlleyDby. Contrary to the static analysis approach, the dynamic analysis approach is more effective because there is no need to unpack the investigated file before the analysis process. Dynamic analysis can support the detection models to be able to detect novel malware behaviors in addition to known malware. Further, the general behavior of the malware is not affected by obfuscation techniques, so it is difficult for obfuscated malware to evade the dynamic analysis approach because the obfuscation techniques change the malware structure but could not change the malware behavior. However, dynamic malware analysis is more sensitive to evasive malware and can detect whether it is being executed in a real or controlled environment.
2. Malware Detection Approaches
The malware detection process is the mechanization that must be implemented to discover and identify the malicious activities of the files under investigation. As a result, several approaches to detecting malware have been improved year after year, with no single approach providing 100% success with all malware types and families in every situation. Therefore, malicious software has been detected based on two main characteristics, which are signatures and behaviors using three malware detection approaches that are signature-based, behavioral-based, and heuristic-based. Therefore, the following sections discuss the malware detection approaches. Table 3 contains the characteristics of each reviewed paper in terms of detection approach with the extraction and representation methods.
2.1. Signature-Based
Several studies have been undertaken to improve malware detection and classification models by relying on a unique signature that has been previously extracted statically or dynamically and stored to compare it with the collected investigated file signature. Those signatures include but are not limited to a set of API calls, opcodes or byte-code series, and entropy quantity. Static string-based signatures have been generated by [4][45][35,60] to detect VBasic malicious software by representing the obtained strings using frequency vectors, while [7][61] generated static signatures based on n-grams and binary vectors. Additionally, [1][38] formed malicious static signatures using the statistical values of opcodes. On the other hand, behavioral signatures have been constructed based on the dynamically collected data. The authors of [28][46][47][48,62,63] created behavioral signatures using API calls invoked by malware during their running time. Specific sets of API calls are identified as reflecting malicious activities, and thus the behavioral malicious signatures are constructed utilizing those API calls. Static and behavioral signature-based malware detection models suffer from low detection rates when classifying unknown signatures that may be linked to unknown malware or different variants of known malware.
Table 2. The relation between analysis approaches and data types.
2.2. Behavioral-Based
After monitoring the executable files in an isolated environment and collecting the exhibited behaviors, features extraction techniques have been developed to extract the sensitive features by which the developed model can classify the known malicious behaviors as well as any behavior that seems to be similar to them with respect to false positive behaviors. The ability to identify novel malware behaviors in addition to the known ones based on collecting behaviors during run-time has made this approach more valuable than the signature-based approach. As a result, the majority of the studies in the literature review focused on using behavioral-based approaches in the form of continuous, sequential, and common behaviors to increase malware detection ratios.
Some studies have been conducted based on the extracted continuous behaviors which, are represented by machine activities. The authors of [8][41] was interested in the Windows platform and used the Cuckoo sandbox to extract machine activity data (CPU, memory, received, and sent packets). After that, the observations were transformed into vectors, which were used to train and assess classification algorithms. Most of the previous studies were concerned with extracting API calls, system calls, opcodes, and others to form them sequentially (sequential behaviors) or into ordered patterns to understand the malicious functionalities. The sequential or ordered patterns can be API calls, registry data, and network data [17][22][48][13,40,45] or opcode sequences [49][76]. Moreover, the common behaviors that are performed by malware and benign samples can be used as an indicator to classify the investigated file between malware or benign classes in the binary classification models. In addition, those common behaviors can be observed in each malware family in the case of multi-classification models. The time of the matching process has been reduced from where the developed models classify the test files based on only the common behaviors. Common behaviors graph-based malware detection and classification models have been proposed by [50][51][10,77] in their work through observing the most frequent behavior graphs in each malware family. Additionally, ref. [52][78] presented binary and multi-classification models using (LSTM) long-short term models based on the common API call sequences offered by each malware family.
2.3. Heuristic-Based
A heuristic-based approach has been used in various research by generating generic rules that investigate the extracted data, which are given through dynamic or static analysis to support the proposed model of detecting malicious intent. The generated rules can be developed automatically using machine learning techniques, the YARA tool, and other tools or manually based on the experience and knowledge of expert analysts.
Several studies have been done to develop malware detection models by which decisions have been taken based on the automated behavioral rules that are created using machine learning techniques and the YARA tool [22][25][27][45,47,54]. On the other hand, based on statically extracted string data, ref. [14][34] was concerned with generating manually general rules to recognize the existence of malicious activities that might be achieved by malware using HTML elements and JavaScript functions. Moreover, (DNS) domain name system-based rules were developed by [49][76] to build a botnet attack detection model. The proposed model took the final decision based on the manually developed general rules which can detect abnormalities in DNS queries and responses.
2.4. Malware Detection Discussion
According to the literature, the researchers applied string, opcode, and derived features to construct static signatures, while only API calls and opcodes were used to create dynamic signatures. In general, the ability to detect malware utilizing previously derived signatures using both static and dynamic signatures is insufficient to combat malicious software enhancement due to obfuscation techniques popularly used by malware writers to create different malware variants as well as new malware, because each malware variant and new malware seems to have a different fingerprint, which must be obtained before the detection process can begin.
Furthermore, malware detection models based on static signature patterns have been defeated during the tackling of encrypted or compromised malware. Regarding the behavioral-based approach and the preferable data types, machine activities data is the most used feature in the literature to depict malware functionality using continuous behaviors, whereas API calls data is the most frequently utilized feature to build malware detection models using sequential behaviors. Furthermore, the most used data types when authors try to get the common behaviors among malware groups are API calls and opcodes. The behavioral-based approach is a promising solution to overcome the weaknesses of the signature-based approach but relying on behaviors leads the suggested models to misclassify malware that performs functions that are similar to benign functions or mimic legitimate behaviors, and then those models suffer from a high false-positive rate.
Moreover, malware is capable of recognizing the nature of its execution surroundings using evasion techniques and then changing its behaviors to be like benign behaviors or terminating its execution, resulting in representing them through unrepresentative behaviors. In addition, extracting a sufficient feature set is a tough process that has a massive effect on the malware detection and classification models. Furthermore, representing malware behaviors based on the names, sequence, or frequency of extracted characteristics results in malware detection and classification models that are more vulnerable to obfuscation techniques, which are employed to update the names, sequences, and frequencies of the extracted characteristics. Furthermore, several researchers trained their models by employing malicious behaviors that were extracted from the most recent malware to provide the classifiers the capacity to recognize trends in malicious activity. On the other hand, developed malware detection models have become vulnerable to older malicious behaviors.
By focusing on the heuristic-based approach, there is no single type of data that is commonly used with this approach in the literature, but the researchers have used practically almost all the types of data at the same rate, including API calls, network data, registry data, import DLL, and others. However, the creation of general rules that play a significant role in the final decision is required when building a malware detection and classification model based on the heuristic approach. Therefore, generating the investigation rules manually consumes time and effort and needs malware behavior experts with enough experience. Even though the required rules can be generated automatically, the suggested rule-based model is limited to detecting only the malicious activities that are represented in the critical general rules.