Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Kaile Du and Version 2 by Rita Xu.
Given a query language, a Detection-based Vision-Language Understanding (DVLU) system needs to respond based on the detected regions (i.e.,bounding boxes). With the significant advancement in object detection, DVLU has witnessed great improvements in recent years, such as Visual Question Answering (VQA) and Visual Grounding (VG).
- detection-based vision-language understanding
- region collaborative network
- non-local network
1. Introduction
Visual object detection has been studied for years and has been applied to many applications such as smart city, robot vision, consumer electronics, security, autonomous driving, human–computer interaction, content-based image retrieval, intelligent video surveillance, and augmented reality [1][2][3][1,2,3]. Recently, many researchers found that vision-language understanding tasks based on detected regions or called Detection-based Vision-Language Understanding (DVLU) can achieve better performance than many traditional vision-language understanding methods that directly use the pixel-based image information [4][5][6][7][4,5,6,7]. For instance, the key to the success of the winning entries to the Visual Question Answering (VQA) challenge [8][9][10][11][12][8,9,10,11,12] is the use of detected regions. Moreover, the success of visual object detection leads to many new DVLU tasks, such as Visual Grounding [13][14][15][16][17][13,14,15,16,17], Visual Relationship Detection [18][19][18,19] and Scene Graph Generation [20][21][22][23][24][20,21,22,23,24]. With significant advancements made in the area of object detection, DVLU and its related tasks have attracted much attention in recent years. As shown in Figure 1, in a smart city, a monitor may shoot a picture from a crowded street, and a DVLU system can answer the human question and give the following response. For example, when given a query question “How many people are in the picture?”, a DVLU system can provide the correct answer via the detected regions.
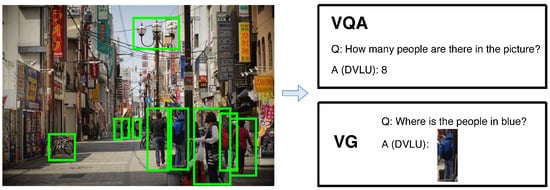
Figure 1. A DVLU system in a smart city. Specifically, VQA needs to answer with natural language while VG needs to answer with a grounded region.
A DVLU task is defined as that given several detected regions (hereinafter, all regions refer to detected regions or bounding boxes for simplicity) from a nature image, a model automatically recognizes the semantic patterns or concepts inside the image. Specifically, a DVLU model first accepts some region inputs from an off-the-shelf object detection model (detector). By applying any well-designed model (i.e., a deep neural network or DNN), these detected regions can be treated as finer features or bottom-up attentions [6] of the original image. Then, each region is fed to the DVLU model as a kind of meaningful information to help understand images at a high level. Unlike usual image understanding, DVLU is based on multiple detected or labeled regions, which makes DVLU receive more fine-grained information than non-region image understanding.
Nevertheless, when facing numerous independent detected regions in an image, existing DVLU methods always ignore their distributions and relationships, which is inadequate for different regions consisting of a real-world scene. Furthermore, it is insufficient to separately reprocess each region for features after detecting them while ignoring that they were an integral whole and discarding their original cooperation. This motivates theour new design of collaboratively processing all the regions for DVLU, which will help a DVLU task make full use of regions to collaborate and enhance each other.
With RCN, the feature of a region is enhanced by all other regions in the image. As shown in Figure 2, in a DVLU pipeline, the RCN block can be easily inserted by keeping the dimension consistent. First, the RCN block receives the feature of regions as input. For each region feature, reswearchers compute Intra-Region Relation (IntraRR) across positions and channels to achieve self-enhancement. Then, the Inter-Region Relation (InterRR) is applied to all regions across positions and channels. To reduce redundant connections, researcherswe apply a pooling and sharing strategy relative to IntraRR. Finally, a series of the refined feature of regions are obtained by linear embedding. In general, researcherswe can easily add an RCN block to any DVLU model to process all the regions collaboratively. The proposed RCN is put into two DVLU tasks in the experiment: Visual Question Answering and Visual Grounding. The experimental results show that the proposed RCN block can significantly improve the performance against the baseline models.
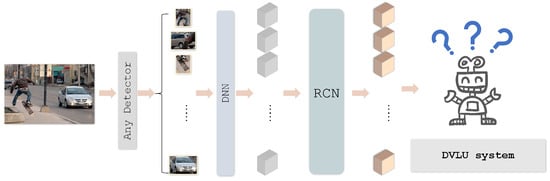
Figure 2. Region Collaborative Network (RCN) can be inserted into a Detection-based Vision-Language Understanding (DVLU) pipeline. Any object detector can be used to generate regions.
2. Detection-Based Vision-Language Understanding
Detection-based Vision-Language Understanding (DVLU) attracted much attention in recent years due to the significant technological advancement of visual object detection [1][25][26][27][28][1,25,26,27,28]. With semantically labeled regions, DVLU methods can mine deeper-level information more effectively than those based only on pixel-based images. DVLU methods have been applied to many high-level vision-language tasks, such as VQA [6][7][13][29][30][6,7,13,29,30] and VG [13][31][32][13,31,32]. In VQA, Anderson et al. [6] build an attention model on detected bounding boxes for image captioning and visual question answering. Hinami et al. [33] incorporate the semantic specification of objects and intuitive specification of spatial relationships for detection-based image retrieval. The up–down [8] model is based on the principle of a joint embedding of the input question and image, followed by a multi-label classifier over a set of candidate answers. In pythia [9], they demonstrate that by making subtle but important changes to the model architecture and the learning rate schedule, fine-tuning image features, and adding data augmentation, pythia can significantly improve the performance of the up–down model. In VG, Deng et al. [13] propose to build the relations among regions, language, and pixels using an accumulated attention mechanism. Lyu et al. [32] propose constructing the graph relationships among all regions and using a graph neural network to enhance the region feature. In [34], the model exploits the reciprocal relation between the referent and context, either of them influences the estimation of the posterior distribution of the other, and thereby the search space of context can be significantly reduced. However, most of these methods do not fully use the relationship among regions, and some only consider the relative spatial relation of regions. In general, these methods ignore the cross-region problem. This may isolate each region from the whole scene and negatively affect performance.
3. Region Relation Network
Relationships among objects or regions have been studied for years. Some work is based on hyperspectral imaging [35][36][37][38][35,36,37,38] and some on deep learning [39][40][41][42][43][39,40,41,42,43]. One way is to study the explicit relationship between objects. It usually starts with detecting every object pair with the relationship in a given image [18][19][18,19]. After that, by combining detected relationship triplets (⟨subject, relationship, object⟩), an image can be transformed into a scene graph, where each node represents the region and each directed edge denotes the relationship between two regions [4][20][21][22][4,20,21,22]. Unfortunately, it is still unclear how to effectively use this structural topology for many end-user tasks, although it is based upon a large number of labeled relationships. Another way is to focus on building a latent relationship between objects. Zagorukyo et al. [44] explore and study several neural network architectures that compare image patches. Tseng et al. [45] was inspired by the non-local network [46] and proposed to build non-local ROI for cross-object perception. This respapearchr is different from [45] in that the proposed RCN: (1) can be inserted into any DVLU model while keeping dimension consistency without modifying the original model; (2) computes intra-region and Inter-Region Relations in terms of both spatial positions and channels; and (3) applies to fully connected region features.