Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Sirius Huang and Version 1 by Raed Alsaqour.
Artificial intelligence (AI) techniques have been used to describe the characteristics of information, as they help in the process of data mining (DM) to analyze data and reveal rules and patterns. In DM, anomaly detection is an important area that helps discover hidden behavior within the data that is most vulnerable to attack. It also helps detect network intrusion. Algorithms such as hybrid K-mean array and sequential minimal optimization (SMO) rating can be used to improve the accuracy of the anomaly detection rate.
- anomaly detection
- data mining
- k-mean clustering
- network security
1. Introduction
Computer networks have become more vulnerable to penetration and to exploits exposing information, due to the Internet being completely open to users. Recently, network attacks are becoming more sophisticated and harder the detect. The statistical studies according to the Symantec Global Internet Security Threat report indicate that intrusions are at record levels and are increasing drastically. Given the exponential growth of the dependence on data, algorithms for data protection from threats and attacks are greatly needed to preserve the privacy, confidentiality, availability, and integrity of information systems. Hence, intrusion detection systems (IDSs) are a vital tool for protecting data. Figure 1 shows IDS categories. While detection algorithms only recognize well-known attacks, anomaly detection algorithms can recognize unidentified attacks according to users’ behavior. Two of the main issues with anomaly detection are speed and efficiency [1]. If the network has high traffic, it is almost intolerable to utilize a fast sophisticated algorithm for intrusion detection (ID) in advance. Many new procedures achieve a good rate of IDS, but they need high resource allocation and are time-consuming (i.e., communication, memory energy, or another system requirement). These deficiencies may become even more complicated if the traffic is manipulated in real-time.
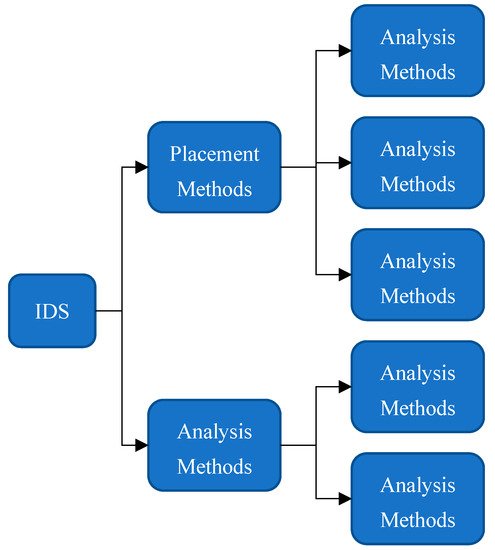
Figure 1. IDS categories.
One of the secure design principles is defense-in-depth, which implies adding multiple security mechanisms to prevent, detect, contain, and recover from attacks. Security mechanisms such as access control, multi-factor authentication, and data encoding are being utilized to act as a frontline defense to prevent potential attacks [2]. Protection procedures and tools, such as intrusion preventions, anti-viruses, firewalls, and IDSs, can monitor the activity of network systems to detect, prevent, and counter suspicious actions [3]. IDSs enable the continuous monitoring of the network traffic to detect anomalous activity in the systems, which is considered a vital method to perform network security [4]. The use of machine learning (ML) and statistical methods enable the building of an effective IDS to protect the networks [5].
Due to advances in computer network technologies, people have relied heavily on network services to obtain information over the Internet. According to the statistics provided in information security, there are a large number of threats that affect computer systems and information. Therefore, defense mechanisms are continuously being developed to preserve the integrity of computer systems and networks to ensure the confidentiality of information. An intrusion detection system (IDS) provides a major role in protecting. An effective IDS enables the protection of computer and information systems from potential intrusions as well as helps detect intrusion and misuse. The process of detected system anomalies protects against potential new attacks or a zero-day attack, where anomalies are detected based on user behavior.
2. Data Mining Techniques
DM plays an important role in IDS and is used in different data applications. Mining techniques such as classification, association rules, and clustering enable users to make sense of information about intrusions by monitoring network data. IDS categories are based on their scope from standalone PCs to network systems. The most common categorizations are hosts-based IDSs (HIDSs) and network IDSs (NIDSs). The system that monitors significant files in OS is an instance of an HIDS, while the systems that examine traffic of the received network is an instance of an NIDS. The following paragraphs classify ID techniques used in DM applications [8][6]. Classification is defined as the process of analyzing data by taking an instance of the dataset to be assigned to a specific class and extracting models known as classifiers that define important data categories [9][7]. An IDS is a server or software program that screens and monitors network traffic for malicious activities or violations of security policies. The system, which relies on the classification concept, sorts network traffic into normal or malicious. The process of data classification is divided into two parts. The first part is known as the learning period, during which a classifier is created, and from it, the data categories are predicted in the second part, which is the classification step. In classification analysis, the end-user/analyst needs to know how to define the categories in advance. In the classification process, the main goal of the classifier is to explore the data to discover the different categories, in addition to arranging the new records into the category [10][8]. Many classification techniques are used, such as decision tree induction, genetic algorithm, fuzzy logic, and Bayesian networks-nearest neighbor classifier. In general, data classification techniques have a lower impact on ID methods compared to data clustering techniques, which have a great impact on the performance of IDSs. This is because of the high amount of data required to classify the dataset into normal and abnormal categories. The clustering approach provides an easier and faster classification process than human labeling for a large amount of data. It enables the labeling of data and grouping it into similar objects. Each group is known as a cluster and consists of several members with similar traits, and the members differ from one group to another. Clustering methods can be useful for classifying network data to detect intrusions. There are several clustering algorithms, and they are divided into five groups as follows [11][9]: Hierarchical clustering techniques: This method creates tree-based structure classification from unclassified data assets. It can be developed with the assistance of statistical methodologies. Density-based techniques: This technique strains the arguments of each cluster from a precise distribution probability. It can only be utilized for spherical-based clusters. The value of a density-based cluster considers the point’s density, where density arguments should be prepared before dataset scanning. Grid-based techniques: The key benefit of this algorithm is its vast calculation time, regardless of the number of data cells. The object band is quantized into a predetermined number of cells. Model-based techniques: This method calculates the greatest data fit based on the hypothesis model. The number of clusters based on statistical standards can be determined repeatedly. The algorithm may construct clusters based on a modeling density probability that imitates the distribution of 3D data objects. Partition techniques: In this technique, for n points datasets with hypothesis k data dividers, each point should fit precisely one cluster, and each cluster should comprise at least one point. The dividing method enhances the reiterative re-partitioning method by removing points from one cluster to another. The method of data division relies on a specific partitioning function. Table 1 discusses the differences and comparisons between these techniques. The importance of the table lies in defining the differences among the most-studied clustering techniques and their use in improving anomaly detection in recent years so that each of them is clarified by presenting the strengths and weaknesses against the used mechanism (K-means).Table 1.
Differences between the various clustering techniques.
| Clustering Techniques | Advantages | Disadvantages | Example |
|---|---|---|---|
| Hierarchical | Flexible for all shapes | Slow | DAINA |
| Density-based | Simple and fast | The number of clusters should be specified prior | K-mean |
| Grid-based | All data types | Difficult quality of clusters | DBSCAN |
| Model-based | Scalable and vast | Poor for 3D data cluster | STENG |
| Partition-based | Powerful and flexible | Only for abnormal | CBOWEB |
3. Intrusion Detection Models and Techniques
Previous studies presented several DM techniques that are based on classifying user behavior, but they have some limitations. Some of the main limitations and challenges related to the detection techniques are described below. One of the most important limitations of ID algorithms is real-time traffic analysis. The information system is potentially exposed to an intrusion risk if real-time traffic detection is inaccurate. Efficiency and speed are the main issues in anomaly detection systems. One of the problems is related to the traffic volume on the network, given that complex detection algorithms are used at an adequate speed if the traffic is high. The effect of missing data on the results obtained during classification. Accurate and reliable conclusions cannot be drawn if there are missing data that are important for feature selection when carrying out classification. According to the abovementioned limitations and challenges, this section provides a survey of various ID models and techniques. It also presents the methodologies used to develop the IDS and the latest updated models. A study by C. Taylor et al. [13][11] proposed an approach known as the network analysis of anomalous traffic events (NATE), which is based on clustering and multivariate analysis. NATE can enhance the ability of IDS to deal with detection constraints and big data traffic [14][12]. Moreover, NATE enables performance features of limited attack scope and anomaly detection, in addition to minimizing network traffic measurement [15][13]. The NATE operation is based on two phases; the first is data collection and analysis for possible attacks, and the second is intrusion detection in the real-time environment [16][14]. The NATE classification is a cluster-based algorithm. The study shows that the clustering approach enables quick updates of the new attack features for real-time traffic in the database [17][15]. A. Bakhtiar and G. Antonio [15][13] provided a production-based expert system toolset (P-BEST) to detect misuse attacks and develop a new signature mechanism. P-BEST can provide efficient IDS performance in a real-time environment [16][14]. The proposed mechanism allows integration with c programming for flexibility and ease of use. However, it has a low detection capability of intrusions and attacks with incomplete and uncertain data or unknown environment information [18][16]. C. Zheng et al. [19][17] presented a framework for DM to build IDS models. The proposed framework enables the automatic use of the IDS model [20][18]. The operations of the DM framework tiers are dependent on the ability of inductively learned computations related to relevant system features, raw audit data processing, and network-dumped data, which are all summarized into connection records and attributes [21][19]. This approach applies two algorithms: association rules and frequent episodes [22][20]. M. Saeed et al. [23][21] presented the use of a decision tree for multiple host-based detector combinations. The proposed idea depends on the ID measures and decision tree. The measures are considered the basis of IDS modeling [24][22]. The modeling measures are performed by the statistical rule-based method [25][23]. Minegishi, T. et al. [26][24]. presented a framework for data mining (DM) to build IDS models. Three tiers are reviewed data mining framework parties, classification, association rules, and frequent episodes programs. The proposed framework enables the use of the IDS model automatically [23][21]. The operations of the data mining framework tiers are dependent on the ability of inductively learned computations related to relevant system features, the raw audit data processing, and the network dumped data, which are all summarized into connection records attributes [23][21]. This approach applies two algorithms, association rules, and frequent episodes. The author Minegishi, T. and his team also presented an anomaly detection system known as audit data analysis and mining (ADAM) in [27][25]. The proposed ADAM uses data mining techniques for detecting intrusions. It combines classification and association rules algorithms for discovering attacks in TCP dump [26][24]. ADAM can classify suspicious activities of known and unknown attack connections. Barbará, D. et al. [28][26] presented the use of a decision tree for multiple host-based detectors’ combination. The proposed idea depends on the intrusion detection measures and decision tree. The measures are considered the base of IDS modeling. The modeling measures are performed by the statistical rule-based method. Another study presented by Zhang et al. [29][27] provides a hybrid misuse and anomaly detection approach for NIDS. The study investigates the combination of two detection methods to reduce the limitations of both when they are considered individually. The proposed hybrid detection approach is evaluated as a technique for data mining intrusion detection for the random dataset. In the study by P. Yuhuai et al. [30][28], a method was proposed to improve the efficiency of the decision tree algorithm. They reviewed the operations of bagging and boosting and randomization techniques to generate various classifier ranges through training data manipulation. Z. Peng et al. [31][29] provided the ability of artificial intelligence (AI) technology to enhance the accuracy of anomaly detection. The proposed study evaluates the use of semi-supervised learning and unsupervised learning techniques to detect anomalies. The authors used the K-means clustering approach and training instances through the Euclidean distance method and then evaluated the C4.5 algorithm [32][30]. Their results showed that the semi-supervised training algorithm gives better performance than supervised or unsupervised algorithms. V. Olena et al. [33][31] designed an effective intrusion identification system based on the fuzzy logic approach. The proposed system enables the detection of intrusion behavior in the network. It uses a mechanical method to create fuzzy rules, which are obtained from specific rules using repeating elements [34][32]. Through the results of the experiments, the authors concluded that the system based on fuzzy logic achieves a higher accuracy to determine whether the records are normal or offensive. G. Azidine et al. [35][33] proposed the use of two algorithms for ID: the backpropagation algorithm and C4.5 algorithm. In addition to dealing with known attacks, these algorithms are mainly used to detect misuse and determine the level of deviations in normal profiles. They can also explore algorithms based on supervised ML [17][15]. The authors used KDD CUP99 databases and tested the datasets by the proposed algorithm containing several attack types, such as denial of service (DoS), investigation, user-to-root (U2R), and remote-to-local (R2L). Through the results obtained, the study showed that the use of neural networks provides high performance in detecting known attacks, but the use of decision trees gives a higher and more exciting performance when detecting new attacks [36][34]. G. Mutanov et al. [37][35] proposed a hybrid ML technique for network ID based on a combination of K-means clustering and support vector machine classification. This research aims to reduce the rate of false-positive alarms and false-negative alarm rates and improve the detection rate. The authors used the network security-knowledge and data discovery (NSL-KDD) dataset, and the classification was performed by using a support vector machine [38][36]. After training and testing the proposed hybrid ML technique, the results showed that the proposed technique achieves a positive detection rate and reduces the false alarm rate.References
- Joseph, M.V. Significance of data warehousing and data mining in business applications. Int. J. Soft Comput. Eng. 2013, 1, 329–333.
- Tellis, V.M.; Souza, D.J.D. Detecting anomalies in data stream using efficient techniques: A review. In Proceedings of the 2018 International Conference on Control, Power, Communication and Computing Technologies (ICCPCCT), Kannur, India, 23–24 March 2018; pp. 296–298.
- Zhang, L.; Chen, Y.; Liao, S. Algorithm optimization of anomaly detection based on data mining. In Proceedings of the 10th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Changsha, China, 10–11 February 2018; pp. 402–404.
- Xie, J.; Wu, D.; Liao, T. Method of anomaly detection of temperature data in vacuum thermal test based on data mining. In Proceedings of the Eighth International Conference on Instrumentation & Measurement, Computer, Communication and Control (IMCCC), Harbin, China, 19–21 July 2018; pp. 1040–1045.
- Cai, S.; Sun, R.; Hao, S.; Li, S.; Yuan, G. An efficient outlier detection approach on weighted data stream based on minimal rare pattern mining. China Commun. 2019, 16, 83–99.
- Rehman, A.; Hassan, M.F.; Hooi, Y.K.; Qureshi, M.A.; Chung, T.D.; Akbar, R.; Safdar, S. Context and machine learning based trust management framework for internet of vehicles. Comput. Mater. Contin. 2021, 68, 4125–4142.
- Zhang, L.; Liu, C.; Chen, Y.; Lao, S. Abnormal detection research based on outlier mining. In Proceedings of the 11th International Conference on Intelligent Computation Technology and Automation (ICICTA), Changsha, China, 22–23 September 2018; pp. 5–7.
- Anandharaj, A.; Sivakumar, P.B. Anomaly detection in time series data using hierarchical temporal memory model. In Proceedings of the 3rd International conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 12–14 June 2019; pp. 1287–1292.
- Elmubark, M.A.; Saeed, R.A.; Elshaikh, M.A.; Mokhtar, R.A. Fast and secure generating and exchanging a symmetric keys with different key size in TVWS. In Proceedings of the International Conference on Computing, Control, Networking, Electronics and Embedded Systems Engineering (ICCNEEE), Khartoum, Sudan, 7–9 September 2015; pp. 114–117.
- Qin, Y.; Lou, Y. Hydrological time series anomaly pattern detection based on isolation forest. In Proceedings of the IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 1706–1710.
- Sun, W.; Zhang, G.; Zhang, X.; Zhang, X.; Ge, N. Fine-grained vehicle type classification using lightweight convolutional neural network with feature optimization and joint learning strategy. Multimed. Tools Appl. 2021, 80, 30803–30816.
- Nurelmadina, N.; Hasan, M.K.; Memon, I.; Saeed, R.A.; Zainol Ariffin, K.A.; Ali, E.S.; Mokhtar, R.A.; Islam, S.; Hossain, E.; Hassan, M.A. A Systematic Review on Cognitive Radio in Low Power Wide Area Network for Industrial IoT Applications. Sustainability 2021, 13, 338.
- Amen, B.; Grigoris, A. A Theoretical study of anomaly detection in big data distributed static and stream analytics. In Proceedings of the IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Exeter, UK, 28–30 June 2018; pp. 1177–1182.
- Cao, N.; Lin, C.; Zhu, Q.; Lin, Y.R.; Teng, X.; Wen, X. Voila: Visual Anomaly Detection and Monitoring with Streaming Spatiotemporal Data. IEEE Trans. Vis. Comput. Graph. 2018, 24, 23–33.
- Guezzaz, A.; Asimi, Y.; Azrour, M.; Asimi, A. Mathematical validation of proposed machine learning classifier for heterogeneous traffic and anomaly detection. Big Data Min. Anal. 2021, 4, 18–24.
- Zhao, Z.; Zhang, Y.; Zhu, X.; Zuo, J. Research on time series anomaly detection algorithm and application. In Proceedings of the IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chengdu, China, 20–22 December 2019; pp. 16–20.
- Chen, Z.; Yu, X.; Ling, Y.; Song, B.; Quan, W.; Hu, X.; Yan, E. Correlated anomaly detection from large streaming data. In Proceedings of the IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 982–992.
- Ergen, T.; Kerpiççi, M. A novel anomaly detection approach based on neural networks. In Proceedings of the 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4.
- Lee, J.; Park, S. Mobile memory management system based on user’s application usage patterns. Comput. Mater. Contin. 2021, 68, 4031–4050.
- Mei, L.; Zhang, F. A Novel distributed anomaly detection algorithm for low-density data. In Proceedings of the IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020; pp. 197–201.
- Saeed, M.M.; Saeed, R.A.; Saeid, E. Identity division multiplexing based location preserve in 5G. In Proceedings of the International Conference of Technology, Science and Administration (ICTSA), Taiz, Yemen, 22–24 March 2021; pp. 1–6.
- Elfahal, M.O.; Mustafa, M.; Mustafa, M.E.; Saeed, R.A. A framework for Sudanese Arabic—English mixed speech processing. In Proceedings of the International Conference on Computing and Information Technology (ICCIT-1441), Tabuk, Saudi Arabia, 9–10 September 2020; pp. 1–6.
- Provotar, O.I.; Linder, Y.M.; Veres, M.M. Unsupervised Anomaly detection in time series using LSTM-based autoencoders. In Proceedings of the IEEE International Conference on Advanced Trends in Information Theory (ATIT), Kyiv, Ukraine, 18–20 December 2019; pp. 513–517.
- Minegishi, T.; Niimi, A. Detection of fraud use of credit card by extended VFDT. In Proceedings of the World Congress on Internet Security (WorldCIS-2011), London, UK, 21–23 February 2011; pp. 152–159.
- Minegishi, T.; Ise, M.; Niimi, A.; Konishi, O. Extension of decision tree algorithm for stream data mining using real data. In Proceedings of the Fifth International Workshop on Computational Intelligence & Applications, Hiroshima, Japan, 10–12 November 2009; pp. 208–212.
- Barbará, D.; Couto, J.; Jajodia, S.; Wu, N. ADAM: A testbed for exploring the use of data mining in intrusion detection. ACM Sigmod Rec. 2001, 30, 15–24.
- Zhang, J.; Zulkernine, M. A hybrid network intrusion detection technique using random forests. In Proceedings of the First International Conference on Availability, Reliability and Security (ARES’06), Vienna, Austria, 20–22 April 2006.
- Peng, Y.; Tan, A.; Wu, J.; Bi, Y. Hierarchical Edge Computing: A Novel Multi-Source Multi-Dimensional Data Anomaly Detection Scheme for Industrial Internet of Things. IEEE Access 2019, 7, 111257–111270.
- Zhan, P.; Xu, H.; Luo, W.; Li, X. A novel network traffic anomaly detection approach using the optimal φ-DTW. In Proceedings of the IEEE 11th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 16–18 October 2020; pp. 1–4.
- Saeed, R.A.; Saeed, M.M.; Mokhtar, R.A.; Alhumyani, H.; Abdel-Khalek, S. Pseudonym mutable based privacy for 5G user identity. Comput. Syst. Sci. Eng. 2021, 39, 1–14.
- Vynokurova, O.; Peleshko, D.; Bondarenko, O.; Ilyasov, V.; Serzhantov, V.; Peleshko, M. Hybrid machine learning system for solving fraud detection tasks. In Proceedings of the IEEE Third International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2020; pp. 1–5.
- Jwo, D.-J.; Wu, J.-C.; Ho, K.-L. Support Vector Machine Assisted GPS Navigation in Limited Satellite Visibility. CMC-Comput. Mater. Contin. 2021, 69, 555–574.
- Ng, R.T.; Han, J. Efficient and Effective clustering methods for spatial data mining. In Proceedings of the 20th International Conference on Very Large Data Bases (VLDB ’94), San Francisco, CA, USA, 12–15 September 1994; pp. 144–155.
- Ahmed, Z.E.; Hasan, M.K.; Saeed, R.A.; Hassan, R.; Islam, S.; Mokhtar, R.A.; Khan, S.; Akhtaruzzaman, M. Optimizing Energy Consumption for Cloud Internet of Things. Front. Phys. 2020, 8, 358.
- Mutanov, G.; Karyukin, V.; Mamykova, Z. Multi-class sentiment analysis of social media data with machine learning algorithms. Comput. Mater. Contin. 2021, 69, 913–930.
- Dridi, A.; Boucetta, C.; Hammami, S.E.; Afifi, H.; Moungla, H. STAD: Spatio-Temporal Anomaly Detection Mechanism for Mobile Network Management. IEEE Trans. Netw. Serv. Manag. 2021, 18, 894–906.
More