Successful whole genome amplification (WGA) is a cornerstone of contemporary preimplantation genetic testing (PGT). Choosing the most suitable WGA technique for PGT can be particularly challenging. The aim of this review is to provide insight into the performance and drawbacks of the most popular WGA techniques used in PGT.
- whole genome amplification
- preimplantation genetic testing
- embryo
- next generation sequencing
- massively parallel sequencing
- haplotype
- multiple displacement amplification
- degenerate oligonucleotide primer
1. Introduction
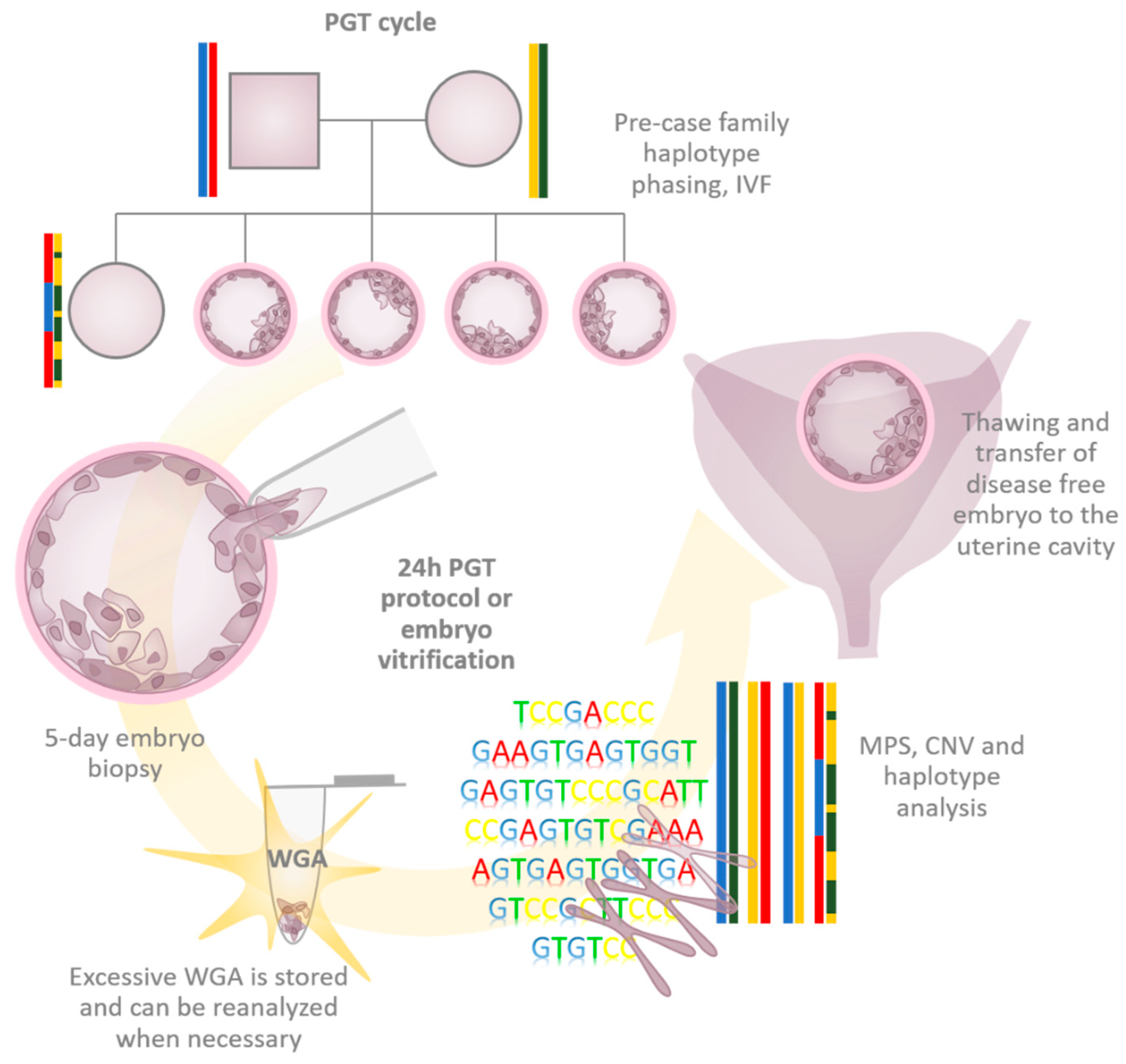
2. Requirements of WGA in PGT
3. WGA Types
3.1. PEP-PCR
Zhang et al. first described the application of WGA from a single cell in 1992. They termed this method primer extension preamplification PCR. Their new technique exploited random 15-base oligonucleotides non-specifically binding to a target genome. Theoretically, the primer was composed of a mixture of 1 × 109 different sequences and was estimated to capture and amplify at least 78% of the haploid genome of a single sperm cell as assessed through targeted loci analysis [2]. Initially, the PEP-PCR protocol was claimed to be too lengthy and no better than direct single-cell PCR by other groups [12]. However, following modifications which resulted in a better genome recovery, this protocol has been successfully applied to various cells (amniocytes, chorionic villi, blastomeres) and has enabled several genetic loci of interest in human genetic diseases to be examined with a good amplification efficiency [13,14,15][13][14][15]. The development of this WGA technique was a breakthrough in the field of human PGT, as it allowed for the first time simultaneous multiple locus analysis with the further opportunity to validate the findings. Although contemporary applications do not (or very rarely) employ the original PEP-PCR approach, its principle has been integrated into all successive WGA developments.
3.2. DOP-PCR
Primer extension preamplification was quickly followed by the development of the more widely adopted DOP-PCR protocol, first described by Telenius et al. [16], to complement the cytogenetic analysis of flow-sorted chromosomes. Degenerate oligonucleotide primer PCR uses partially degenerate primers binding to many sites of the targeted genome. Variations of DOP-PCR primers include oligos with six degenerated bases in the middle, flanked by defined sequences at both ends (traditional DOP-PCR primer 5′-CCGACTCGAGNNNNNNATGTGG-3′) or oligos with a random 3′ end and partially fixed 5′ sequence–oligos with increased degeneracy, also termed tagged random primers. In all cases, due to the primers’ properties, DOP-PCR synthesis occurs in two stages.3.3. MDA
The next important technical advancement in the application of WGA methods was the development of multiple displacement amplification (MDA). Originally termed multiply-primed rolling circle amplification [23][17], MDA was initially developed to amplify circular templates, but was subsequently modified for the amplification of linear ones. MDA exploits the unique properties of bacteriophage φ29 DNA polymerase (phi29) [24][18]. This enzyme possesses proofreading activity and has the capacity to perform strand displacement DNA synthesis for more than 70,000 nucleotides under isothermal conditions without dissociating from the template.3.4. MALBAC
Significantly later, in 2012, Zong et al. reported the development of a new WGA technology termed multiple annealing and looping-based amplification cycles (MALBAC). MALBAC introduces quasi-linear preamplification to reduce the bias associated with non-linear amplification (first stage PCR). The preamplification is initiated with a pool of random primers, each having a common 5′ 27-nucleotide sequence and 3′ eight random nucleotides, hybridizing to the template DNA at low temperatures (15–20 °C, capable of hybridizing at 0 °C) [29][19]. Thus, this stage resembles the MDA principle, with the difference that the MALBAC preamplification stage consists of multiple (5 to 12) annealing-extension-denaturation-looping steps, rather than isothermal synthesis [11].3.5. Hybrid WGA Methods
As the various WGA technologies were being established, hybrid WGA techniques combining features of PCR-based and MDA-based WGA were also becoming commercially available. The most well-known hybrid WGA methodology is PicoPLEX, originally introduced by Rubicon Genomics and now marketed as SurePlex by Illumina and a few other companies. While information on the exact principle of these commercially available kits is not easily available due to patents and continuous upgrades, they all utilize two-stage PCR. During the first preamplification stage, template DNA is amplified utilizing either: (i) non-self-complementary/self-inert primers which preclude primer dimer formation [11]; or (ii) primers allowing for the looping of full amplicons, similar to the ones used in MALBAC [33,34,35][20][21][22].4. WGA Drawbacks
4.1. ADO and Incomplete Genomic Coverage
It is thought that, once the template DNA concentration falls below a certain input level, the probability of obtaining a complete template genome, especially with the expectation of uniform amplification, decreases dramatically. At very low initial DNA concentrations, random and difficult to predict (stochastic) effects dictate whether a particular genomic region will be amplified or not [42][23]. The so-called ‘Monte Carlo effect’ states that “the lower the abundance of any template, the less likely its true abundance will be reflected in the amplified product” [43][24]. Incomplete genomic coverage is apparent from such events as allelic or locus dropout—one of the major drawbacks of WGA in human PGT. The phenomenon of ADO is widely recognized—perceived from the first PGT trials performed using direct PCR—and is the main reason for adopting haplotyping—the simultaneous amplification of causative genes together with linked polymorphic markers—as the gold standard in PGT [5]. It is important to note that ADO can arise not only from incomplete genomic coverage, but also from preferential amplification of one of the alleles. Therefore, ADO is a complex phenomenon not only influenced by the molecular technique, but also inherent to single-cell applications in general.4.2. Amplification Bias
Amplification bias, also termed PCR drift, results when certain regions/amplicons within a multitemplate reaction are preferentially amplified relative to the entire pool of potential templates [29][19]. As expected, the lower the concentration of the initial template, the more prominent the effects of amplification bias. Amplicon representation bias is very much affected by primer composition, i.e., degree of degeneracy of the primer. Substantial overamplification can result due to complementarity between the 3′ region of the primer and the genomic sequence [29,42][19][23].4.3. Chimera and Non-Template Amplicons
Apart from representation bias, WGA can produce a certain degree of chimera amplicons—a kind of artificial amplicon mapping to different parts of the genome that are not physically linked. The dominant type of chimeras are intra-chromosomal translocations, suggesting that chimeras are produced by neighbouring amplicons randomly connecting on the same chromosome [46][25]. While the formation of chimeric PCR fragments has been attributed to MDA [47][26] and further demonstrated for other WGA methods [25,47][26][27], no issues arising from this phenomenon have been reported in PGT. Of note, no significant preference has been recorded in the distributions of chimeras and hotspots among chromosomes; however, preferences in overlap length and GC content have been shown to be pertinent to the sequence denaturation temperature, highlighting a direction of action for reducing chimeras [48][28]. Non-template amplicons are associated with contamination and are common to any amplification employing random or degenerate oligos [42][23]. They can be addressed by implementing good laboratory practices.4.4. WGA-Independent Improvements
There are a few measures that can be undertaken to increase the efficiency of any WGA technique. The foremost one is to perform a trophectoderm biopsy. Irrespective of the widely demonstrated clinical benefits [49,50][29][30], performing a blastocyst stage biopsy (which implies biopsy of several trophectoderm cells) also affords a number of technical advantages compared to a single-cell biopsy with subsequent WGA. First, in comparison to a single cell, several cells increase the number of template genomes, thus smoothing the abrogating WGA effects described directly above. For example, Handyside and colleagues investigated the relationship between ADO and input cell number. They demonstrated that ADOs occurred randomly at a frequency of approximately 16% in single-cell amplifications, but were undetectable when the number of input cells was increased to 10–20 [26][31].5. Performance Comparison of Different WGA Types
5.1. Mappability of Reads
As mentioned earlier, WGA produces a certain fraction of non-specific amplicons. Similarly, using MPS, there will always be a percentage of reads not mapping to the reference genome. The source of these unmappable reads is junk reads arising from the formation of primer dimers, short DNA fragments, and non-target genomes [25,54][27][32]. For example, when comparing the WGA types MDA, MALBAC, and PicoPLEX using 5× sequencing depth, it was demonstrated that the fraction of unmapped reads for all the amplifiers was low (0.035% mean fraction of unmapped reads) [54][32]. In contrast, a much higher unmappable read percentage was demonstrated using deeper sequencing (30×). Specifically, the percentage of unmappable reads for GenomePlex (Sigma Aldrich, St. Louis, MO, USA) and PicoPLEX (Rubicon Genomics, Ann Arbor, MI, USA) (which are considered the same chemistry WGA kits) reached 64 and 66%, respectively. REPLI-g MDA kit (Qiagen) and MALBAC (Yikon Genomics, Shanghai, China) showed 18% and 22% of unmapped reads, respectively [25][27]. Another group detailed 35–40% of unmappable reads from SurePlex- and MALBAC-amplified single white blood cells (sequencing depth unknown) [30][33]. Such large percentages of unmappable reads were proposed to be due to the presence of universal adapter reads, which are WGA-independent, as well as primer sequences and substantial contributions from small amplicons [25][27].5.2. Uniformity of Coverage and CNV Analysis
As discussed earlier, deficient uniformity of coverage is intrinsic to single-cell applications and is further affected by WGA. In PGT-A, it is essential to have uniform coverage or to have bioinformatic algorithms to manage PCR bias. In 2002, it was reported that DOP-PCR leads to a strong amplification bias, with individual loci differing in copy number by four to six orders of magnitude [57][34]. As MDA-based amplification is isothermal, as opposed to PCR-based WGA methods, one common assumption has been that the MDA technique is immune to GC bias. However, DNA regions with a high localized GC content also prove to be problematic for isothermal amplification, leading to reports of under-representation caused by reduced DNA polymerase processivity and poor DNA priming in high GC areas [42][23]. Furthermore, it has been shown that the amplification bias in MDA progressively worsens with greater fold amplification, whereas MALBAC and PicoPLEX appear relatively insensitive to reaction gain [54][32]. It has subsequently been demonstrated that DOP-PCR and other PCR-based WGA methods exhibit reasonable uniform amplification with reduced regional amplification bias and outperform MDA in terms of CNV detection using arrays or NGS [30,54][32][33].5.3. Genomic Coverage and SNV Calling
In the era of arrays, genome representation assessment directly depended on array resolution, which, when compared to MPS, could never cover the full genome or exome. Thus, array genome representation percentages cannot be compared to the ones derived from NGS data. Using 10 K SNP arrays, MDA was estimated to amplify 99.82% of the genome [58][35]. Using MPS with ~25× mean sequencing depth, MDA covered 72% of the genome and MALBAC achieved up to 93% genomic coverage of single cancer cells [29][19]. MDA using either phi29 or Bst DNA polymerase has been widely reported to achieve a high physical coverage (>90%) from a single-cell genome or exome at a high sequencing depth (typically >30× or at least 15× average sequencing depth) [46,59,60][25][36][37]. In contrast, GenomePlex and PicoPLEX (kits with the same chemistry) covered only 39% and 52% of the reference genome, respectively (30× sequencing depth) [25][27]. Reduced genomic coverage has also been acknowledged for DOP-PCR [46,59][25][36]. Conversely, shallow sequencing depth runs retrieve only very limited fractions of the genome. For example, MDA attained 8.84% genomic coverage at a mean sequencing depth of ~0.5×, which was slightly higher than that of MALBAC (8.06%) [46][25]. Taking account of the percentages of genomes retrieved at deep and shallow sequencing depths, it is evident that the WGA methods themselves are capable of amplifying significant proportions of the target genome, and it is in fact the selected parameters of the downstream applications (e.g., MPS) that limit the detection of the amplified genome.5.4. False Positive Rate
No less important than undetectable alleles are false alleles that occur due to errors made by the DNA polymerase of the WGA or downstream application assay. Usage of high-affinity (not easily dissociated from the DNA strand), robust (working through tough reaction conditions, e.g., without a purification step) and high-fidelity (i.e., maintaining Watson-Crick base pairing) DNA polymerases, in addition to possessing 3′ > 5′ proofreading activity, is the key to reducing the number of false positives during any PCR/DNA synthesis.6. Comprehensive PGT Solutions Utilizing Different WGA Protocols
6.1. The Beginning of the Massively Parallel Sequencing Era in Human PGT
In the early days of MPS, it became clear that it provides a better signal-to-noise ratio and resolution than aCGH, simply due to advances in technology. NGS specificity for aneuploidy calling was demonstrated to be 99.98% with a sensitivity of 100% [65][38]. Exceptional multiplexing opportunities and falling NGS costs facilitated the smooth transition of PGT-A towards monumental MPS exploitation. At the beginning of the MPS era in PGT, the majority of applications used SurePlex WGA, as MPS data were often validated by the formerly-used established aCGH protocols that widely employed SurePlex WGA (e.g., [65,66][38][39]).
6.2. Karyomapping and Haplarithmisis
Karyomapping was one of the first applications to exploit SNP arrays in PGT. At the time, it was a rapid alternative to the targeted STR typing approach used as standard in PGT-M. Genome-wide SNV haplotyping allows Karyomapping to detect CNVs, meiotic trisomy, monosomy, triploidy, parthenogenetic activation, uniparental heterodisomy, as well as patterns of genomic duplication seen in, for example, hydatidiform moles—all in a single workflow. The assay requires single- or multi-cell embryo biopsy amplified by an isothermal MDA as the starting material [28,67][40][41]. Haplarithmisis—an extension of Karyomapping—is similarly a genome-wide generic PGT tool that originally exploited SNP arrays and MDA for single-/few-cell WGA. A computational pipeline evaluates the observed versus expected SNP probe’s intensity values for each allele in the sample, thus allowing detection of CNVs, the mitotic or meiotic nature of chromosomal anomalies (with the exception of monosomies), low-grade mosaicism, as well as proper ploidy (e.g., enables the distinction of aberrant tetraploid from aberrant diploid) [62][42].6.3. OnePGT
A commercial NGS-based solution that integrates PGT-A, PGT-SR, and PGT-M in a single workflow—OnePGT by Agilent Technologies—has recently been released to the market. The protocol exploits MDA for the embryo WGA and reduced representation WGS and has been verified on a few Illumina-sequencing platforms. To deduce haplotype inheritance, the embedded PGT-M pipeline utilizes principles of Haplarithmisis and was developed by the same group. Both the PGT-A and PGT-SR pipelines are based upon read-count analysis in order to assess CNVs. Inherent to haplotyping methodologies, the processing of additional family members such as the proband or a grandparent is required for haplotype establishment [68][43].6.4. MARSALA
The MPS application termed Mutated Allele Revealed by Sequencing with Aneuploidy and Linkage Analyses (MARSALA) combines low-coverage genome sequencing for PGT-A and the targeted enrichment of mutation loci and linked SNVs for PGT-M. A prerequisite for MARSALA is the genome sequences of the parents. In the absence of an affected relative of the parents, an affected embryo identified by direct calling of the causative SNV or embryo haplotyping can be used as an equivalent of the proband for linkage analyses [69,70][44][45]. The application uses MALBAC for embryo WGA, an aliquot of which is reamplified with a pair of target-specific primers, and then the targeted PCR products are mixed with the native WGA for NGS. In this way, the existence of the point mutation and aneuploidy can be detected in one NGS run. The region of interest can be sequenced to ultra-high coverage (>1000×), still maintaining an accurate CNV measurement throughout the whole genome. It has been demonstrated that, in contrast to MDA, using MALBAC for single-cell WGA linkage analyses can be achieved with only 2× sequencing depth [69,70][44][45].6.5. MaReCs
Technologically similar to MARSALA and developed by the same group, Mapping Allele with Resolved Carrier Status (MaReCs) is a PGT-SR methodology. Whilst MaReCs does not require pre-clinical work-up to phase haplotypes, it is performed in two stages. First, embryo CNVs are analysed by a high-coverage, high-resolution WGS. Secondly, targeted NGS analysis is performed for 60 adjacent SNVs flanking the translocation breakpoint in a manner similar to MARSALA to perform haplotyping [72][46]. The availability of at least one chromosomally imbalanced embryo (so-called reference embryo) is essential for the pipeline to locate a translocation breakpoint. This approach is able to establish whether or not a chromosomally balanced embryo carries the translocation [72][46], which is not possible by standard PGT-SR and PGT-A.6.6. Haploseek
Haploseek is a low-coverage, sequencing-based cPGT application exploiting PicoPLEX for embryo WGA. Although custom target design is not required, a prerequisite for the PGT cycle is pre-case SNP array assessment of the parents and affected child to generate whole genome haplotypes. Further SNP array data, together with sequencing data from the embryos, are integrated using a hidden Markov model, which predicts whether or not the parental-affected haplotypes have been inherited by each of the sequenced embryos across all chromosomes [74][47].6.7. Universal cPGT
Recently, Chen et al. have developed a comprehensive WGS-based PGT tool capable of assessing monogenic disorders, aneuploidies, and chromosomal rearrangements without the requirement of additional family members and without the need of any pre-clinical work-up [76][48]. However, PGT-SR can only be performed if unbalanced translocation embryos are available as a reference to distinguish between balanced translocation carriers and normal embryos. Haplotyping for PGT-M is achieved by analysing already-retrieved embryos as a reference, rendering it impossible to analyse cases where direct mutation loci testing in embryos cannot be achieved by NGS (e.g., trinucleotide expansion disorders, intergenic deletions).7. Conclusion
To enable the genetic diagnosing of preimplantation embryos, all of the current cPGT solutions require clonal amplification of the template DNA. Consequently, WGA is more essential than ever before and has become one of the most important tools in the ever-developing field of human PGT [42][23]. The availability of substantial volumes of initially minute amounts of embryonic DNA generated by a single WGA round has made it possible to: (i) avoid embryo rebiopsy and repeat the analysis on account of assay failure or (long term) misdiagnosis or genotype mismatch of the birthed baby; (ii) shorten the turnaround time between referral and clinical cycle because the adaptation/validation of PCR reactions at the single-cell level can be omitted from the pre-clinical work-up [6]; and, most importantly, (iii) develop multifactor and comprehensive PGT. MPS-based approaches are much more standardized and allow for high-throughput automation, reduced hands-on time, and minimization of the possibility of human errors—all at a reduced cost [6]. Hence, MPS-based approaches are regarded as the most powerful platforms for future PGT [89][49]. Several groups have already demonstrated the ability to perform mutation loci assessment with a shallow sequencing depth (2–4×) without the need for target enrichment [69,70,76][44][45][48]. Furthermore, the technical resolution of CNV detection has been demonstrated to be down to several kilobases [66][39]. While researchers compete to reduce the testing time and simplify the use of PGT methods, clinically, these objectives are not always justified and can result in painful and hard-to-correct errors. PGT has never been a simple method and, by its very nature, cannot be. Despite all the tempting emerging technical PGT opportunities, clinical PGT should continue to strictly adhere to the existing guidelines [6,56][6][50] and always bear in mind that patient safety is the number one priority. Orthogonal SNV validation should never be omitted unless there is convincing evidence to the contrary. The resolution of CNV detection should not be set unreasonably high to minimize the detection of artifacts resulting from WGA-introduced bias appearing as extensive biological heterogeneity, as this can potentially lead to normal embryos being discarded [59,66][36][39].References
- Coutelle, C.; Williams, C.; Handyside, A.; Hardy, K.; Winston, R.; Williamson, R. Genetic analysis of DNA from single human oocytes: A model for preimplantation diagnosis of cystic fibrosis. Br. Med. J. 1989, 299, 22–24.
- Zhang, L.; Cui, X.; Schmitt, K.; Hubert, R.; Navidi, W.; Arnheim, N. Whole genome amplification from a single cell: Implications for genetic analysis. Proc. Natl. Acad. Sci. USA 1992, 89, 5847–5851.
- Telenius, H.; Carter, N.P.; Bebb, C.E.; Nordenskjöld, M.; Ponder, B.A.J.; Tunnacliffe, A. Degenerate oligonucleotide-primed PCR: General amplification of target DNA by a single degenerate primer. Genomics 1992, 13, 718–725.
- Toft, C.L.F.; Ingerslev, H.J.; Kesmodel, U.S.; Diemer, T.; Degn, B.; Ernst, A.; Okkels, H.; Kjartansdóttir, K.R.; Pedersen, I.S. A systematic review on concurrent aneuploidy screening and preimplantation genetic testing for hereditary disorders: What is the prevalence of aneuploidy and is there a clinical effect from aneuploidy screening? Acta Obstet. Gynecol. Scand. 2020, 99, 696–706.
- Kuliev, A.; Rechitsky, S. Preimplantation genetic testing: Current challenges and future prospects. Expert Rev. Mol. Diagn. 2017, 17, 1071–1088.
- ESHRE PGT-M Working Group; Carvalho, F.; Moutou, C.; Dimitriadou, E.; Dreesen, J.; Giménez, C.; Goossens, V.; Kakourou, G.; Vermeulen, N.; Zuccarello, D.; et al. ESHRE PGT Consortium good practice recommendations for the detection of monogenic disorders. Hum. Reprod. Open 2020, 2020, hoaa018.
- Harper, J.C.; Wilton, L.; Traeger-Synodinos, J.; Goossens, V.; Moutou, C.; SenGupta, S.B.; Pehlivan Budak, T.; Renwick, P.; De Rycke, M.; Geraedts, J.P.M.; et al. The ESHRE PGD consortium: 10 years of data collection. Hum. Reprod. Update 2012, 18, 234–247.
- Rechitsky, S.; Pakhalchuk, T.; San Ramos, G.; Goodman, A.; Zlatopolsky, Z.; Kuliev, A. First systematic experience of preimplantation genetic diagnosis for single-gene disorders, and/or preimplantation human leukocyte antigen typing, combined with 24-chromosome aneuploidy testing. Fertil. Steril. 2015, 103, 503–512.
- Cimadomo, D.; Capalbo, A.; Ubaldi, F.M.; Scarica, C.; Palagiano, A.; Canipari, R.; Rienzi, L. The Impact of Biopsy on Human Embryo Developmental Potential during Preimplantation Genetic Diagnosis. BioMed Res. Int. 2016, 2016, 7193075.
- Scott, K.L.; Hong, K.H.; Scott, R.T. Selecting the optimal time to perform biopsy for preimplantation genetic testing. Fertil. Steril. 2013, 100, 608–614.
- Czyz, Z.T.; Kirsch, S.; Polzer, B. Principles of whole-genome amplification. In Whole Genome Amplification: Methods and Protocols; Springer: Berlin/Heidelberg, Germany, 2015.
- Kristjansson, K.; Chong, S.S.; Van den Veyver, I.B.; Subramanian, S.; Snabes, M.C.; Hughes, M.R. Preimplantation single cell analyses of dystrophin gene deletions using whole genome amplification. Nat. Genet. 1994, 6, 19–23.
- Sermon, K.; Lissens, W.; Joris, H.; Van Steirteghem, A.; Liebaers, I. Adaptation of the primer extension preamplification (PEP) reaction for preimplantation diagnosis: Single blastomere analysis using short PEP protocols. Mol. Hum. Reprod. 1996, 2, 209–212.
- Snabes, M.C.; Chong, S.S.; Subramanian, S.B.; Kristjansson, K.; DiSepio, D.; Hughes, M.R. Preimplantation single-cell analysis of multiple genetic loci by whole- genome amplification. Proc. Natl. Acad. Sci. USA 1994, 91, 6181–6185.
- Xu, K.; Tang, Y.; Grifo, J.A.; Rosenwaks, Z.; Cohen, J. Preimplantation diagnosis: Primer extension preamplification for detection of multiple genetic loci from single human blastomeres. Hum. Reprod. 1993, 8, 2206–2210.
- Telenius, H.; Ponder, B.A.; Tunnacliffe, A.; Pelmear, A.H.; Carter, N.P.; Ferguson-Smith, M.A.; Behmel, A.; Nordenskjöld, M.; Pfragner, R. Cytogenetic analysis by chromosome painting using dop-pcr amplified flow-sorted chromosomes. Genes Chromosom. Cancer 1992, 4, 257–263.
- Dean, F.B.; Nelson, J.R.; Giesler, T.L.; Lasken, R.S. Rapid amplification of plasmid and phage DNA using Phi29 DNA polymerase and multiply-primed rolling circle amplification. Genome Res. 2001, 11, 1095–1099.
- Esteban, J.A.; Salas, M.; Blanco, L. Fidelity of φ29 DNA polymerase. Comparison between protein-primed initiation and DNA polymerization. J. Biol. Chem. 1993, 268, 2719–2726.
- Zong, C.; Lu, S.; Chapman, A.R.; Xie, X.S. Genome-wide detection of single-nucleotide and copy-number variations of a single human cell. Science 2012, 338, 1622–1626.
- Sigma-Aldrich. Whole Genome Amplification Advisor. Available online: https://www.sigmaaldrich.com/deepweb/assets/sigmaaldrich/product/documents/128/636/wga_advisor.pdf (accessed on 1 March 2022).
- Illumina. SurePlex Summary Protocol Reference Guide. 2018, (September 2020). Available online: www.illumina.com/company/legal.html (accessed on 1 March 2022).
- Takara Bio. SMARTer® PicoPLEX® Single Cell WGA Kit User Manual. (0):1–18. Available online: https://www.takarabio.com/assets/documents/UserManual/SMARTerPicoPLEXSingleCellWGAKitUserManual_091818.pdf (accessed on 1 March 2022).
- Sabina, J.; Leamon, J.H. Bias in whole genome amplification: Causes and considerations. In Methods in Molecular Biology; Springer: Berlin/Heidelberg, Germany, 2015.
- Karrer, E.E.; Lincoln, J.E.; Hogenhout, S.; Bennett, A.B.; Bostock, R.M.; Martineau, B.; Lucas, W.J.; Gilchrist, D.G.; Alexander, D. In situ isolation of mRNA from individual plant cells: Creation of cell- specific cDNA libraries. Proc. Natl. Acad. Sci. USA 1995, 92, 3814–3818.
- Hou, Y.; Wu, K.; Shi, X.; Li, F.; Song, L.; Wu, H.; Dean, M.; Li, G.; Tsang, S.; Jiang, R.; et al. Comparison of variations detection between whole-genome amplification methods used in single-cell resequencing. Gigascience 2015, 4, 37.
- Lasken, R.S.; Stockwell, T.B. Mechanism of chimera formation during the Multiple Displacement Amplification reaction. BMC Biotechnol. 2007, 7, 19.
- Huang, L.; Ma, F.; Chapman, A.; Lu, S.; Xie, X.S. Single-Cell Whole-Genome Amplification and Sequencing: Methodology and Applications. Annu. Rev. Genom. Hum. Genet. 2015, 16, 79–102.
- Tu, J.; Lu, N.; Duan, M.; Huang, M.; Chen, L.; Li, J.; Guo, J.; Lu, Z. Hotspot selective preference of the chimeric sequences formed in multiple displacement amplification. Int. J. Mol. Sci. 2017, 18, 492.
- Ribustello, L.; Escudero, T.; Margiatto, E.; Nagy, P.; Acacio, B.M.D.; Munne, S. Differences between blastomere and blastocyst biopsies for preimplantation genetic diagnosis (PGD) using array comparative genomic hybridization (aCGH). Fertil. Steril. 2013, 100, S130.
- Kokkali, G.; Traeger-Synodinos, J.; Vrettou, C.; Stavrou, D.; Jones, G.M.; Cram, D.S.; Makrakis, E.; Trounson, A.O.; Kanavakis, E.; Pantos, K. Blastocyst biopsy versus cleavage stage biopsy and blastocyst transfer for preimplantation genetic diagnosis of β-thalassaemia: A pilot study. Hum. Reprod. 2007, 22, 1443–1449.
- Handyside, A.H.; Robinson, M.D.; Simpson, R.J.; Omar, M.B.; Shaw, M.A.; Grudzinskas, J.G.; Rutherford, A. Isothermal whole genome amplification from single and small numbers of cells: A new era for preimplantation genetic diagnosis of inherited disease. Mol. Hum. Reprod. 2004, 10, 767–772.
- De Bourcy, C.F.A.; De Vlaminck, I.; Kanbar, J.N.; Wang, J.; Gawad, C.; Quake, S.R. A quantitative comparison of single-cell whole genome amplification methods. PLoS ONE 2014, 9, e105585.
- Li, N.; Wang, L.; Wang, H.; Ma, M.; Wang, X.; Li, Y.; Zhang, W.; Zhang, J.; Cram, D.S.; Yao, Y. The Performance of Whole Genome Amplification Methods andNext-Generation Sequencing for Pre-Implantation Genetic Diagnosis of Chromosomal Abnormalities. J. Genet. Genom. 2015, 42, 151–159.
- Dean, F.B.; Hosono, S.; Fang, L.; Wu, X.; Faruqi, A.F.; Bray-Ward, P.; Sun, Z.; Zong, Q.; Du, Y.; Du, J.; et al. Comprehensive human genome amplification using multiple displacement amplification. Proc. Natl. Acad. Sci. USA 2002, 99, 5261–5266.
- Ostrowski, L.E.; Dutcher, S.K.; Lo, C.W. Cilia and Models for Studying Structure and Function. Proc. Am. Thorac. Soc. 2011, 8, 423–429.
- Wang, Y.; Navin, N.E. Advances and Applications of Single-Cell Sequencing Technologies. Mol. Cell 2015, 58, 598–609.
- Zhou, X.; Xu, Y.; Zhu, L.; Su, Z.; Han, X.; Zhang, Z.; Huang, Y.; Liu, Q. Comparison of multiple displacement amplification (MDA) and multiple annealing and looping-based amplification cycles (MALBAC) in limited DNA sequencing based on tube and droplet. Micromachines 2020, 11, 645.
- Fiorentino, F.; Bono, S.; Biricik, A.; Nuccitelli, A.; Cotroneo, E.; Cottone, G.; Kokocinski, F.; Michel, C.E.; Minasi, M.G.; Greco, E. Application of next-generation sequencing technology for comprehensive aneuploidy screening of blastocysts in clinical preimplantation genetic screening cycles. Hum. Reprod. 2014, 29, 2802–2813.
- Deleye, L.; Dheedene, A.; De Coninck, D.; Sante, T.; Christodoulou, C.; Heindryckx, B.; Van den Abbeel, E.; De Sutter, P.; Deforce, D.; Menten, B.; et al. Shallow whole genome sequencing is well suited for the detection of chromosomal aberrations in human blastocysts. Fertil. Steril. 2015, 104, 1276–1285.e1.
- Handyside, A.H.; Harton, G.L.; Mariani, B.; Thornhill, A.R.; Affara, N.; Shaw, M.A.; Griffin, D.K. A universal method for genome wide analysis of genetic disease based on mapping crossovers between parental haplotypes. J. Med. Genet. 2010, 47, 651–658.
- Griffin, D.; Gould, R. What is Karyomapping and where does it fit in the world of preimplantation genetic diagnosis (PGD)? Med. Res. Arch. 2017, 5, 1–18.
- Esteki, M.Z.; Dimitriadou, E.; Mateiu, L.; Melotte, C.; Van der Aa, N.; Kumar, P.; Das, R.; Theunis, K.; Cheng, J.; Legius, E.; et al. Concurrent Whole-Genome Haplotyping and Copy-Number Profiling of Single Cells. Am. J. Hum. Genet. 2015, 96, 894–912.
- Masset, H.; Zamani Esteki, M.; Dimitriadou, E.; Dreesen, J.; Debrock, S.; Derhaag, J.; Derks, K.; Destouni, A.; Drüsedau, M.; Meekels, J.; et al. Multi-centre evaluation of a comprehensive preimplantation genetic test through haplotyping-by-sequencing. Hum. Reprod. 2019, 34, 1608–1619.
- Xiong, L.; Huang, L.; Tian, F.; Lu, S.; Xie, X.S. Bayesian model for accurate MARSALA (mutated allele revealed by sequencing with aneuploidy and linkage analyses). J. Assist. Reprod. Genet. 2019, 36, 1263–1271.
- Yan, L.; Huang, L.; Xu, L.; Huang, J.; Ma, F.; Zhu, X.; Tang, Y.; Liu, M.; Lian, Y.; Liu, P.; et al. Live births after simultaneous avoidance of monogenic diseases and chromosome abnormality by nextgeneration sequencing with linkage analyses. Proc. Natl. Acad. Sci. USA 2015, 112, 15964–15969.
- Xu, J.; Zhang, Z.; Niu, W.; Yang, Q.; Yao, G.; Shi, S.; Jin, H.; Song, W.; Chen, L.; Zhang, X.; et al. Mapping allele with resolved carrier status of Robertsonian and reciprocal translocation in human preimplantation embryos. Proc. Natl. Acad. Sci. USA 2017, 114, E8695–E8702.
- Backenroth, D.; Zahdeh, F.; Kling, Y.; Peretz, A.; Rosen, T.; Kort, D.; Zeligson, S.; Dror, T.; Kirshberg, S.; Burak, E.; et al. Haploseek: A 24-hour all-in-one method for preimplantation genetic diagnosis (PGD) of monogenic disease and aneuploidy. Genet. Med. 2019, 21, 1390–1399.
- Chen, S.; Yin, X.; Zhang, S.; Xia, J.; Liu, P.; Xie, P.; Yan, H.; Liang, X.; Zhang, J.; Chen, Y.; et al. Comprehensive preimplantation genetic testing by massively parallel sequencing. Hum Reprod. 2021, 36, 236–247.
- De Rycke, M.; Berckmoes, V. Preimplantation genetic testing for monogenic disorders. Genes 2020, 11, 871.
- ESHRE PGT-SR/PGT-A Working Group; Coonen, E.; Rubio, C.; Christopikou, D.; Dimitriadou, E.; Gontar, J.; Goossens, V.; Maurer, M.; Spinella, F.; Vermeulen, N.; et al. ESHRE PGT Consortium good practice recommendations for the detection of structural and numerical chromosomal aberrations. Hum. Reprod. Open 2020, 2020, hoaa017.