The oil and gas reservoirs in China are mainly terrestrial oil reservoirs with very complex subsurface conditions; consequently, establishing a 3D property model for reservoir characterization is difficult. At present, most oilfields have entered the middle and late stages of development and are in a state of high water content. The balance between injection and production poses an increasingly prominent problem, so it is especially important to determine the amount and distribution of the remaining oil in the reservoir. In addition, today’s petroleum exploration and development focus on unconventional oil and gas reservoirs, such as shale gas and tight sandstone gas. Although such oil and gas reservoirs are abundant in China, they are characterized by low porosity, low permeability, and high water saturation. Therefore, compared with that of conventional oil and gas reservoirs, the development of unconventional oil and gas reservoirs is bound to pose new requirements for reservoir modeling. To solve these problems, there is an urgent need to establish a more refined reservoir model. Therefore, it is necessary to study grid framework models and geostatistical theories and methods in depth so that they can accurately characterize the reservoir at various levels and describe the heterogeneity of the reservoir while quantitatively evaluating the uncertainty of the model and reducing the risk of exploration and development. Therefore, studying 3D property modeling methods can provide a powerful tool for improving the recovery of oil reservoirs in China and offer theoretical guidance for effectively recovering the remaining oil and developing unconventional oil and gas reservoirs.
2. Research on Reservoir Grid Generation Method
Building a 3D reservoir grid model is a key intermediate process and importantly affects the subsequent reservoir property modeling and numerical simulation based on geostatistics. In modeling a reservoir by using geostatistical tools, the gridding process essentially determines how to characterize the macroscopic homogeneity of the reservoir. Since geostatistics are implemented on logical grids, a grid with excessive and excessively large distortion can easily cause the variogram to become distorted, thus affecting the accuracy and reliability of the modeling of properties, such as sedimentary facies and pore permeability
[13][14][13,14]. Additionally, the shape and resolution of the grid affect the accuracy and speed of the numerical simulation of the reservoir
[14][15][14,15].
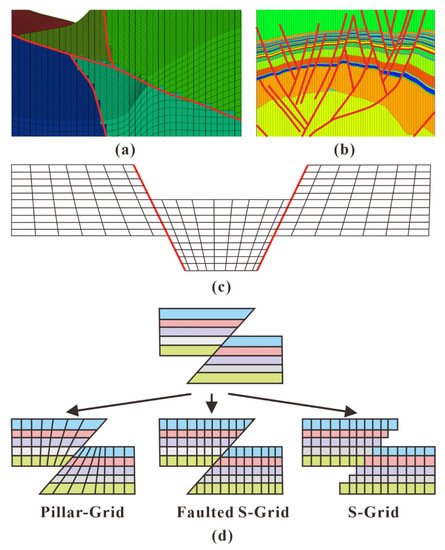
Research on reservoir grid models has been carried out for many years, resulting in many grid types. Zakrevsky
[16] conducted comprehensive gridding and outlined the general procedure of grid generation. Reservoir grids are categorized mainly into structured grids and unstructured grids. Structured grids are typically generated using hexahedra and are organized in an orderly manner with i, j, and k, such as Cartesian grids and corner point grids, while unstructured grids include tetrahedral grids and perpendicular bisector (PEBI) grids. In stratified deposits such as oil sand, often, the Cartesian grid is transformed to a stratigraphic grid using a non-linear coordinate transformation, which is referred to as unfolding. Thom
[17] compared the characteristics of the s-grid, faulted s-grid, and pillar grid as well as these grids’ performance differences in property distribution, grid coarsening, and numerical simulation. As show in
Figure 1, For the s-grid, faulted s-grid, and pillar grid, the main difference is that they contain different fault treatment approaches. Three different examples are extracted in
Figure 1a–c, and the conceptual models are drawn, as show in
Figure 1d, to show the different fault treatment approaches. S-grid is also known as stair-step grid; the sides of this kind of grid cell remain vertical and are controlled by an orthogonal footprint
[17], as show in
Figure 1a. Faulted s-grid is known as Jewel Grid; the grid cells are split exactly at the local position of the fault plane, as show in
Figure 1b
[17]. Pillar grid is widely used in petroleum engineering, and the most common grid is the corner point grid. For the position of faults, the pillar that controls the grid cells is parallel with the fault lines. Thus, the fault should be simplified when the fault is too complicated, as shown in
Figure 1c.
Figure 1. Comparison of s-grid, faulted s-grid, and pillar grid
[17]: (
a) example of s-grid; (
b) example of faulted s-grid; (
c) example of pillar grid; (
d) theoretical model of s-grid, faulted s-grid, and pillar grid for the processing of faults.
Gringarten et al. and Mallet et al.
[18][19][18,19] divided the grids into “geological grids” for geostatistical property modeling and “fluid simulation grids” for numerical simulation based on the different needs of reservoir modelers and digital modeling engineers for grid use. In the many grid studies, the corner point grid represented by the pillar grid has been the hotspot of research, with the most mature application. Pillar grid generation involves three main steps
[20][21][20,21]: (1) a fault model is formed by simulating the fault using pillars; (2) gridding is carried out by combining fault pillars into a 3D grid framework; and (3) vertical stratification is conducted by generating initial layer surfaces on the grid framework for geological stratification. The pillar grid is characterized by its grid orientation along fault lines, boundary lines, or pinch-out lines, indicating that the grid can be distorted, thus overcoming the inflexibility of the orthogonal Cartesian grids and allowing for easy simulations of faults, boundaries, and pinch-outs
[22][23][22,23]. With the development of technology and the continuous improvement in reservoir simulation accuracy, the defects of the pillar grid are gradually exposed as follows. First, due to the limitation of the geometric location of pillars, it is necessary to simplify the fault when using pillars to construct a complex fault network. Second, on the one hand, the nonorthogonality of the pillar grid makes calculating conductivity during numerical simulation difficult; on the other hand, the nonorthogonality of the pillar grid affects the accuracy of the results. Ruiu
[24] proposed a grid generation method that adopts the form of a Cartesian grid at the global level and simulates the fault by truncating the hexahedron, thereby finally constructing an XY-orthogonal and locally truncated grid model. This grid can express the shape of the fault while avoiding the loss of orthogonality due to distortion, but the grid generates many polyhedral grids in models with many faults, thereby also affecting the fluid simulation operations. After analyzing the limitations of the pillar grid, Gringarten
[25] proposed a vertical stair-step grid that is more suitable for fluid simulation and experimentally demonstrated that this type of grid outperforms the pillar grid in terms of grid coarsening and fluid simulation; the author did not give the method for generating this grid.
In addition, many studies have been devoted to unstructured grids. The PEBI grid is flexible and locally orthogonal, thus reducing the influence of grid orientation on the results. In 1988, Heinemann et al.
[26] proposed the implementation of the PEBI grid based on the Voronoi diagram for the numerical simulation of the reservoir grid and then improved the grid with dynamic refinement as needed
[27][28][29][27,28,29]. Palagi of Stanford University
[30][31][32][30,31,32] studied the use of the Voronoi grid, which is essentially the PEBI grid, to simulate vertical and horizontal wells and performed numerical simulation of reservoirs. Since then, scholars have successively carried out research on 3D PEBI grids along with investigation and improvement in different application environments
[33][34][35][36][33,34,35,36]. Additionally, many studies on PEBI grids have been published in recent years by Chinese researchers. Xie
[37] and Lin et al.
[38][39][40][38,39,40] systematically elaborated the application of PEBI grids in the numerical simulation of reservoirs. Liu
[41] addressed the problem of fine numerical simulation of reservoirs by adopting an idea of a hybrid grid consisting of a radial grid in the oil well area and a PEBI grid in the reservoir area. Ref.
[42] proposed a similar idea on hybrid grids.
Xiang
[43] and Zha
[44][45][46][44,45,46] studied the generation algorithm of two-dimensional (2D) PEBI grids, but did not fully address the generation algorithm of 3D PEBI grids. In general, the numerical simulation solutions of PEBI grids are not mature enough and not widely used. In addition, the research on PEBI grids is mainly for the numerical simulation of reservoirs; there are few studies on how PEBI grids are generated and maintain geological significance in geological modeling. In other words, other grids generally need to be transformed before PEBI grids can be used for the numerical simulation of reservoirs.
3. Interpolation Methods for 3D Property Modeling
3.1. Traditional Geostatistical Methods
There is often much spatial variability when dealing with subsurface space modeling in Earth science. Proposed by Matheron
[47], geostatistics is a tool to quantify this variability to enable geologists to predict behavior and make the most useful decisions under the constraints of limited knowledge and resources. The major techniques for generating a 3D model of the geological variables are the main focus, especially the interpolation methods; thus, the principal component analysis (PCA), maximum autocorrelation factor (MAF), projection pursuit multivariate transform (PPMT), and related methods are not considered. The PCA, MAF, PPMT, and other multivariate transforms methods are commonly used to simulate correlated variables independently without the requirement of fitting a linear model. In addition, these approaches can be applied in the data preparation procedure for the geostatistics approaches dealing with multivariate analysis.
Geological phenomena, especially in the petroleum industry, follow a series of complex physical rules that cannot be expressed by simplified models. Reservoir properties, such as porosity and permeability, are needed in reservoir fluid simulation equations to predict oil production and are required at each spatial location; however, porosity and permeability can be obtained only in sparse wells. In other words, for economic reasons, it is generally impossible to accurately and definitively obtain all the information required for a subsurface model. Therefore, spatial uncertainty is a fundamental concept in Earth science. In the early days of the oil industry, practitioners tended to think deterministically and thus expected to obtain a single estimate of oil production. Today, uncertainty is widely accepted.
Geostatistics captures this spatial uncertainty by generating multiple reasonable property models (also known as stochastic realization). By integrating information from different sources, such as logging, coring, geological interpretation, or seismic data, the study area and the true expression of this uncertainty can be obtained. Matheron
[48] introduced the regionalized variable
Z(h) as the value of characteristic
Z of a geological phenomenon at location u. Regionalization means that variables expand in space and exhibit a specific spatial structure. If this concept is ignored, the variables are randomly distributed in the reference region and thus do not exhibit any spatial continuity. However, physical processes in geology are not random in space and have spatial continuity in their properties. For example, the continuity of the river channel formed by a river flowing down the hillside is controlled by the complex physical phenomena along the path of the river, and the mineral deposits tend to be concentrated in certain specific spaces. Thus, the regionalization of variables is the main principle by which geostatistics differs from statistics. It would be impossible to make predictions if spatial continuity does not exist. However, the physical laws that determine spatial continuity cannot be accurately modeled due to the lack of information. To quantify spatial uncertainty, a mathematical model is needed to describe the spatial structure of the variables in the study area. For example, the spatial trends in the data and the isotropy or anisotropy of the variables can be obtained by defining a spatial variable model in geostatistics.
Geostatistical methods have evolved over the decades into two-point geostatistical methods (including the kriging method, deterministic simulation method, and stochastic simulation methods), object-based methods, and multiple-point geostatistics. The methods differ in how their spatial continuity and uncertainty models are expressed and how direct data (such as core data) or indirect data (such as seismic data) are integrated for stochastic realization of subsurface conditions.
3.2. Multiple-Point Geostatistics Methods
The two-point geostatistical method uses the spatial correlation between any two points in the space or uses this correlation as a simple variogram of the spatial continuity model for interpolation. This method relies only on the relationship between two points, but in practice, the correlation of multiple points at once is desired. The formation process of geological heterogeneity is very complex and cannot be expressed by a two-point variogram model. Some complex geological phenomena, such as meandering river systems, cannot be described by traditional random function models. There are three different spatial structures. For the variogram East–West, situation 1 and situation 2 are almost the same, while the spatial structures are totally different. Meanwhile, for the variogram North–South, the 3 spatial structures are alike. The variation function cannot fully reflect the spatial structure. Therefore, multiple-point geostatistics are introduced to simulate this highly complex geological feature
[49][72]. The two-point geostatistical method differs from the object-based method and is more likely to be faithful to valid data.
The idea of multiple-point geostatistics is to use more than two points to infer unknown random variables. Traditional methods consider a stochastic model between two points; that is, the spatial continuity is assumed to be linear. Multiple-point geostatistics uses a structure of more than two points for statistical inference; consequently, this method can reproduce nonlinear spatial correlations. However, in practical applications, it is difficult to find enough points, especially in the case of sparse data, thus not allowing direct inference of subsurface information or the establishment of a random function model that can describe the spatial structure. Therefore, it is necessary to use the conceptual image of geometric properties and geological features (which may be built using the interpreted geological data) for multiple-point geostatistical inference. Such a conceptual image is called a training image.
The training image can be established from geological phenomena, such as the simulation of river sedimentation. The corresponding inference does not come from real data but from the simulated data depicted by the training image. In geological work, by simulating geological processes and even making outcrop photographs, one can depict waterways or lobes and can make multiple-point geostatistical inference with photographs. Since the training image covers multiple points, its spatial continuity pattern is more complex and comprehensive than that of the variogram. Therefore, the training image is closely related to the sedimentary conditions. However, it is not faithful to any specific data but is simply a conceptual image that characterizes the subsurface space. Therefore, it is appropriate to use the object-based method to generate a training image that meets the requirement.
In 1993, Guardiano
[49][72] studied the algorithmic implementation of multiple-point geostatistics. This implementation first assumes an n-dimensional template
(h1,h2,…,hn) and then scans the training image by using the template for all
n random variables
Z1=z(u+h1),…,Zn=z(u+hn) to derive the experimental conditional distribution of
Z(u) at point
u. Finally, a sample value
Z(u) is taken from this distribution and assigned to the current grid to be estimated. A sequential-like method is used here to simulate all grid points randomly.
However, this algorithm has not been very practical due to its excessive computational complexity. With the increasing demand for modeling complex reservoirs with heterogeneous sedimentary characteristics, a variety of multiple-point geostatistical methods have been subsequently developed. These methods all perform multiple-point geostatistical inference through conceptual training images and can be classified into three categories according to their different simulation methods: (1) probability-based methods, (2) iterative methods, and (3) pattern-based methods.
3.3. Deep-Learning Based Modeling Methods
In the rising stage of the second climax of deep learning, some scholars at home and abroad began to try to use the neural network method to carry out reservoir modeling research
[50][102]. For example, Yin et al. (1998) used seismic data to provide attribute distribution trends and converted seismic attribute parameters into reservoir parameters
[51][103]. Zheng et al. (2007) used a high-order neural network to model porosity and sand body top depth
[52][104]. Caers et al. introduced a neural network into multipoint geo-statistics to develop a multipoint geological model. However, it has not been widely popularized due to problems such as difficult training and unstable effect
[53][54][85,86].
At present, the reservoir modeling method based on the third climax of deep learning is in the ascendant, and some scholars and institutions have paid attention to this field. The research results mainly focus on the reservoir modeling method based on genetic adversarial networks. The basic idea is
[55][105] (1) the generator network uses low-dimensional input to generate high-dimensional geological model output; (2) the generated geological model and the original geological model used for training are input into the discriminator network to judge whether the model is generated by the generator; (3) through mutual confrontation and optimization, the generator network generates a model as close to the real geological model as possible to “confuse” the discriminator network, so that it is difficult to distinguish whether the model is generated by the generator network, and the discriminator network identifies whether the model is generated by the generator network as far as possible until the discriminator network finally cannot distinguish whether the model is generated by the generator network. That is, the model generated by the generator network can conform to the actual geological model.
Chan et al. used WassersteinGAN, an improved form of generating a countermeasure network, to realize the channel background two-phase two-dimensional simulation of channels with different curvature
[56][106]. Laloy et al. proposed SGAN to introduce the Markov Monte Carlo method into the generation countermeasure network to generate low-dimensional input and realized three-dimensional and multiphase simulation
[57][107]. DuPont et al.
[58][108] and Zhang et al.
[59][109] further improved the training process of generating a countermeasure network, proposed a conditional simulation modeling method that meets both the geological model and well point hard data constraints, and reproduced the non-stationary state, which is difficult to deal with in traditional multipoint geostatistics. In addition, Mosser et al. used a convolution generation countermeasure network to carry out three-dimensional modeling of the core pore structure
[60][110]. Exterkoetter et al. used convolution to generate a countermeasure network to realize phase modeling based on seismic inversion data
[61][111]. At present, the relevant algorithms and application verification are still in the stage of rapid development, and new research results continue to appear
[62][63][64][112,113,114]. In addition, the PCA, MAF, PPMT, and other multivariate transform methods can be applied in the data preparation procedure for the deep-learning approaches dealing with the multivariate analysis
[65][115].