Liquid biopsy is a broad term that refers to the testing of body fluids for biomarkers that correlate with a pathological condition. While a variety of body-fluid components (e.g., circulating tumor cells, extracellular vesicles, RNA, proteins, and metabolites) are studied as potential liquid biopsy biomarkers, cell-free DNA (cfDNA) has attracted the most attention in recent years. The total cfDNA population in a typical biospecimen represents an immensely rich source of biological and pathological information and has demonstrated significant potential as a versatile biomarker in oncology, non-invasive prenatal testing, and transplant monitoring. As a significant portion of cfDNA is composed of repeat DNA sequences and some families (e.g., pericentric satellites) were recently shown to be overrepresented in cfDNA populations vs their genomic abundance, it holds great potential for developing liquid biopsy-based biomarkers for the early detection and management of patients with cancer.
1. Introduction
The term circulating nucleic acids (cirNAs) refers to segments of genomic DNA, mRNA, and noncoding RNAs in the cell-free fraction of blood (i.e., serum or plasma), and has been receiving increasing attention as a source of biomarkers, especially in oncology
[1][2][3][1,2,3]. Although cirNAs also encompass various species of RNAs, it usually refers to double-stranded DNA, called cell-free DNA (cfDNA). Although the history of cfDNA dates back to the 1940s, much progress in the understanding of its origin and composition and the extensive potential as a minimally invasive source of diverse pathologic conditions has been made in the last two decades
[4]. In 1989, the Stroun group demonstrated that a fraction of the plasma cfDNA in patients with cancer was derived from cancer cells, which is based on the presence of cancer cell DNA with decreased strand stability in plasma samples of patients with cancer
[5]. Shortly thereafter, TP53 mutations were detected in urine from patients with invasive bladder cancer
[6]. The subsequent surge of studies confirmed that cancer cells released detectable concentrations of cfDNA into circulation, and more importantly, that a proportion of cfDNA fragments harbored unique genetic and epigenetic alterations of the tumor cells from which they derived
[4]. This unequivocal proof that a fraction of cfDNA was derived from cancer cells prompted the research efforts around cfDNA, which is now widely recognized as a promising biomarker in cancer screening and monitoring of the efficacy of anticancer therapeutic strategies
[7]. Currently, established clinical use of cfDNA liquid biopsy tests include: (i) FoundationOne Liquid CDx, (ii) COBAS EGFR mutation test V2, (iii) Therascreen PIK3CA RGQ PCR, (iv) Guardant360 CDx, and (v) Epi proColon, for SEPT9 methylation detection in plasma
[8][9][8,9]. Here, it is noteworthy that the fundamental importance of understanding, studying, and analyzing germline DNA before performing liquid biopsy assays is increasingly recognized, as this will enable enhanced differentiation between constitutional genetic alterations and somatic alterations (e.g., due to cancer).
In contrast to the substantial clinical interest in cfDNA, its characterization has initially received little attention. Thus, a lack of understanding of its composition impaired the elucidation of cfDNA biology and its potential clinical use
[10]. In the 2000s, conventional cloning and DNA-sequencing techniques were employed to characterize cfDNA and its composition
[11][12][11,12]. However, such labor-intensive methods can generate limited sequence information due to their inability to cover all sequences of cfDNA
[13].
The introduction of molecular barcodes has enhanced the sensitivity of sequencing methods. This and further advancements in sequencing technologies along with the progression of bioinformatics facilitated the accurate characterization of cfDNA composition
[14][15][14,15]. As a consequence, sequencing efforts of cfDNA have increased considerably in recent years and several studies have not only described clinically relevant genetic mutations in cancer patients at various stages of the disease
[16][17][18][16,17,18], but have demonstrated correlations between the pathology and progression of cancer and various epigenetic features of cfDNA molecules, including various fragmentation features (i.e., size signatures, preferential cleavage sites, jagged ends, unique fragment end-point motifs, orientation-aware fragmentation patterns, nucleosome spacing and density, and topological features) (reviewed in
[19]), methylation patterns, and post translational histone modifications (reviewed in
[20][21][20,21]).
2. Repeat DNA Content of the Human Genome and Cell-Free DNA
Repeat DNA is usually defined as DNA present in multiple copies in the genome and a common feature of eukaryote genomes. More than 50% of the human genome is composed of repeat DNA
[22], with some estimates as high as two-thirds of the genome
[23]. With respect to their genomic distribution, repeat DNA elements can be divided into two groups: tandem repeats and interspersed repeats. Tandem repeats, which account for up to 6% of the human genome, are repetitions of the same sequence motifs aligned in a head-to-tail fashion and cover a significant fraction of heterochromatin and centromeric regions. Microsatellites, minisatellites, centromeric/pericentric satellites, and telomeric/subtelomeric repeats are members of the tandem repeat group. Microsatellites are tandem repetitions of short (1–9 bp) units and are of clinical relevance because their instability (i.e., hypermutability) as a consequence of the loss of mismatch DNA repair is a feature of some human cancers such as colorectal cancer
[24]. Minisatellites are a class of highly polymorphic GC-rich tandem repeats consisting of 10–100-bp units and include some of the most variable loci in the human genome, with mutation rates ranging from 0.5% to >20%
[25]. Centromeric/pericentric satellite sequences, which account for approximately 3% of the human genome, are constituents of centromeric and pericentromeric heterochromatin and telomeres and have been implicated in chromosome organization and segregation, kinetochore formation, as well as heterochromatin regulation
[26]. α-satellites, representing repetitions of 171 bp units assembled into higher-order structures, are highly abundant centromeric elements. Human satellite 2 (HSATII) is an approximately 26-bp tandem repeat and is found in small blocks on the pericentromeres of several human chromosomes
[27]. α-satellites and HSATII have been documented to be highly expressed in tumor cells, which leads to their reverse transcription and stable reintegration into the human genome, expanding their genomic copy numbers
[28]. Interspersed repeats are considered to be remnants of transposable elements (TEs) and constitute approximately 45% of the human genome
[29]. Retrotransposable elements (RTEs) are primary components of TEs and can proliferate and insert themselves into new genomic regions. RTEs are classified into long terminal repeat (LTR) elements and non-LTR elements, which differentiate in the mechanism of retrotransposition and the possession of long terminal repeats
[24]. The non-LTR elements are categorized as either long interspersed nuclear elements (LINEs) or short interspersed nuclear elements (SINEs)
[30], which are predominantly represented by the LINE-1 and ALU families, respectively. The relative proportion of the major classes of repetitive elements in the human genome, as determined by masking of the human genome using RepeatMasker, is shown in
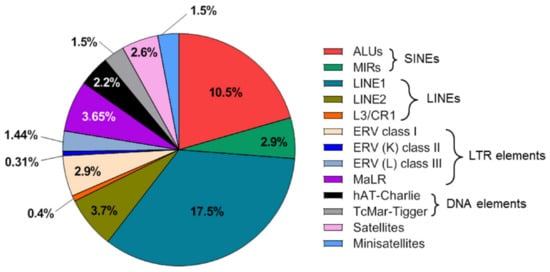
Figure 1.
Figure 1. Distribution of the major repetitive element families in the human genome. The repetitive element landscape is vulnerable to numerous cancer-specific modifications. The abundance of repetitive DNA in the human genome and its widespread occurrence across all chromosomes, is mirrored in the cfDNA content of clinical biospecimens, which makes the characterization of repetitive cfDNA an attractive liquid biopsy tool for interrogating various cancer indications.
As repeat DNA makes up more than 50% of the human genome, it would be expected to also constitute the major part of cfDNA fragments. The first report describing the repeat content of cfDNA dates back to 2009 in which Beck et al. sequenced serum cfDNA of healthy individuals
[31]. They found that most classes of sequences (e.g., genes and RNA and DNA coding sequences) did not differ between serum DNA and genomic DNA. Of the repeat elements, ALU sequences constituted a higher proportion of cfDNA with statistical significance, whereas LINE-1 and LINE-2 element sequences were found to be present in lower proportions
[31]. In a similar article in which cfDNA from healthy individuals and patients with cancer was sequenced using parallel tagged sequencing on the 454 platform, the majority of repeat sequences in patients, as well as controls, were either LINE-1 or ALU repeats because they represent almost half of the total repeat count, where the repeat content of cfDNA was slightly higher in controls than in patients with cancer (46% vs. 42%). A substantial number of satellite sequences were also detected in both groups. All the repeat classes had a slightly higher representation in the control group than in the cancer group
[32].
In an in-vitro study, Bronkhorst et al.
[33][34][33,34] investigated the composition of cfDNA released into the growth medium by cultured osteosarcoma cells. The sequencing of cfDNA revealed that cfDNA consisted mainly of TEs, α-satellites, and minisatellites. Interestingly, a major portion of these repeat element sequences were found to derive from chromosomes 1 and 9, where the authors postulated that increased instability as a result of increased hypomethylation in centromeric and pericentromeric regions of chromosomes 1 and 9 could be the mechanism of selective release of such repeat families from cells into culture medium
[34]. In a more recent study employing high-throughput sequencing of cfDNA, it was demonstrated that there were significant differences between the composition of cfDNA in serum/plasma and the corresponding DNA sequence composition of the human genome
[35]. Compared with their genomic abundance, retrotransposable elements and pericentric satellite DNA were found to be particularly overrepresented in the cfDNA population, and telomeric satellites were underrepresented. The authors explained this overrepresentation of repeat families as a consequence of reverse transcription of retrotransposable elements and reintegration and secondary-structure formation during the replication of satellite DNA contributing to the composition of the cfDNA molecules in the mammalian bloodstream
[35]. The differences that emerged between different studies with respect to repeat content of cfDNA may be attributed to many variables such as the use of different pre-analytical steps, experimental procedures, or sequencing platforms.
The study of cfDNA fragmentation patterns, also referred to as ‘fragmentomics’, is a rapidly evolving area of research
[19]. Fragmentation analysis of sequenced cfDNA is useful for shedding light on emerging markers, such as fragment sizes, preferred ends, end-motifs, single-stranded jagged ends, and nucleosomal footprints. Given the central role of chromatin structure (and by extension the repeat element content of genomic regions) in dictating DNA digestion/degradation activities, incorporating the analysis of repetitive cfDNA, which is predominant in heterochromatin that makes up the majority of the human genome, into the fragmentomics toolbox could provide further insights into the role of repetitive DNA in different physiological states and cancer. Such integrated fragmentomics analyses will also enable a better understanding of the differential abundance and profiles of repetitive cfDNA in various cancer types.
3. Application of Cell-Free Repetitive DNA in Liquid Biopsies of Cancer
Table 1
summarizes applications of repetitive DNA elements in liquid biopsy.
Table 1.
An overview on applications of repetitive DNA elements in liquid biopsy.
|
Repeat Name
|
Repeat Type
|
Liquid Biopsy Application in Patients with Cancer
|
References
|
|
LINE1
|
Interspersed
|
Quantification of total cfDNA
|
[36]][41[37],42[38][39,43,44]
|
|
Assessment of cfDNA integrity
|
[40][45]
|
|
Detection of aneuploidy by amplicon sequencing
|
[41][42][43][46,47,48]
|
|
Assessment of cfDNA global methylation status
|
[44][45][46][47][48][49][50][51][52][,5353,54],55,56[,5754][49,50,51,52,58,59]
|
|
ALU
|
Interspersed
|
Quantification of total cfDNA
|
[44][55][56]63][49,60[,6157],62[58],63[59],64[60],65[61],66[62],67[,68]
|
|
Assessment of cfDNA integrity
|
[39][57][58][61][62][64][65[44],62[,6366][67][68][69][,6670,67],69[71,70][72,71],72,73,74,75,76[73,77][74,78],79]
|
|
Detection of aneuploidy by amplicon sequencing
|
[43][48]
|
|
Human satellite 2
|
Tandem
|
Quantification of total cfDNA
|
[75][80]
|
|
Microsatellites
|
Tandem
|
Assessment of microsatellite instability via cfDNA
|
[76][77][78][79][80][81][82][81,82,83,84,85,86,87]
|
|
Telomeric repeats
|
Tandem
|
Quantification of telomeric cfDNA
|
[83][84][88,89]
|
|
Assessment of telomere length in cf DNA
|
[85][86][90,91]
|
Table 2 summarizes studies that utilized cell-free repetitive DNA in clinical use of cancer patients.
Table 2. Studies that utilized cell-free repetitive DNA in clinical use of cancer patients.
|
Clinical Use
|
Repeat Type
|
References
|
|
Evaluation of diagnostic potential of cedant
|
LINE1
|
[41,42,43,44,46,47,48,49,51,52,54,55]
|
|
ALU
|
[44,49,61,62,63,64,65,66,67,68,69,70,71,72,74,75,76,77,79,98,99]
|
|
Human satellite 2
|
[80]
|
|
Microsatellites
|
[81,82,85,86]
|
|
Prognostic significance of cfDNA
|
LINE1
|
[42,44,45,50,53,54,56,57,59]
|
|
ALU
|
[62,66,67,71,72,73]
|
|
Microsatellites
|
[83]
|
|
Predicting the response to neoadjuvant chemotherapy
|
ALU
|
[100,101,102]
|
|
Monitoring of cancer patients
|
LINE1
|
[42,50,53,55,56,57]
|
|
ALU
|
[60,64,68,79]
|
|
Microsatellites
|
[85,87]
|
|
Clinical Use
|
Repeat Type
|
References
|
|
Evaluation of diagnostic potential of cedant
|
LINE1
|
[36][37][38][39][41][42][43][44][46][47][49][50]
|
|
ALU
|
[39][44][56][57][58][59][60][61][62][63][64][65][66][67][69][70][71][72][74][87][88]
|
|
Human satellite 2
|
[75]
|
|
Microsatellites
|
[76][77][80][81]
|
|
Prognostic significance of cfDNA
|
LINE1
|
[37][39][40][45][48][49][51][52][54]
|
|
ALU
|
[57][61][62][66][67][68]
|
|
Microsatellites
|
[78]
|
|
Predicting the response to neoadjuvant chemotherapy
|
ALU
|
[89][90][91]
|
|
Monitoring of cancer patients
|
LINE1
|
[37][45][48][50][51][52]
|
|
ALU
|
[55][59][63][74]
|
|
Microsatellites
|
[80][82]
|