Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Antonio Cerasa and Version 4 by Beatrix Zheng.
One of the main challenges in traumatic brain injury (TBI) patients is to achieve an early and definite prognosis. Despite the recent development of algorithms based on artificial intelligence for the identification of these prognostic factors relevant for clinical practice, the literature lacks a rigorous comparison among classical regression and machine learning (ML) models. The utility of comparing traditional regression modeling to ML is highlighted here, particularly when using a small number of reliable predictor variables after TBI. The dataset of clinical data used to train ML algorithms will be publicly available to other researchers for future comparisons.
- traumatic brain injury
- outcome predictors
- linear regression
- machine learning
- ensemble of classifiers
1. Introduction
Traumatic brain injury (TBI) has a tremendous impact on patients and family members. They must learn to live with a diminished potential for physical, emotional, cognitive, and social functioning. A recent meta-analysis [1] found an overall incidence rate of 262 per 100,000 per year, and in the USA 43.3% of hospitalized TBI survivors will have a long-term disability [2]. One of the main challenges in TBI-related research is to achieve an early and definite prognosis considering the best predictors of outcome, to administer effective treatments able to improve the clinical progression. Some factors have been proposed and predictive models have been constructed. Most studies used traditional regression techniques to identify these factors [3] defining age, diagnosis, and severity level (measured with Coma Recovery Scale-Revised (CRS-r)) as the most important clinical indicators to predict TBI outcome, although with a poor implementation in clinical practice [4]. In such a scenario, in the last few years, considerable efforts have been put into implementing and developing artificial intelligence tools. Machine learning (ML) methods landed in this neurological domain only recently a few years ago with promising and enthusiastic perspectives [5]. The first studies tested the performance of support vector machine (SVM) [6], Naïve Bayes (NB) [7], and random forest [8] algorithms in predicting the mortality of TBI patients. Despite good performance having been reported (ranging from 67% to 97%), these preliminary ML studies are characterized by high variability in predictive models and clinical predictors used for the training phase, thus reducing a rigorous comparison among methods. For this reason, in this research, the researchers ctudy, we compare the performance of a Classical Linear Regression Model (LM) with the most common ML algorithms for the prediction of clinical outcomes of TI patients (measured with the Glasgow Outcome Scale-Extension) after 6–9 months from the hospitalization. Finally, the researchers awe also tested the ensemble ML algorithm and applied different feature selection methods to optimize the model.
2. Current Insights
In this research, the researchers ctudy, we compare ML approaches to more traditional LM in contemporary TBI patients’ data to predict their clinical evolution, respectively, using 2 and 4 classes of outcome approaches. The researchers We demonstrated that classic LM could perform as well as more advanced ML and ensemble ML classifiers in terms of accuracy (sensitivity and specificity) trained by the same predictors.
The LM had the advantage of identifying some prognostic factors, associating each of them with an odds ratio, while the use of ML is limited by the difficulty of interpreting the model, often referred to as ‘black box’. This finding is perfectly in agreement with results recently obtained by Iosa et al. [9][29], who compared the performance of classical regression, neural network, and cluster analysis in predicting the outcome of patients with stroke. Similarly, Gravesteijn et al. [10][30] reached the same conclusions on TBI patients evaluating the different performance of logistic regression with respect to SVM, random forests, gradient boosting machines, and artificial neural networks. In terms of model performance, theour SVM and DT values are similar to those reported by Abujaber et al. [6], whereas k-NN has never been employed in this clinical domain and this outperformed other ML approaches in all the evaluation metrics. The only algorithm that relatively underperformed was the NB. The accuracy (and sensitivity) was somewhat lower, passing from the analyzed to the test sample. The Ouresearchers' data conflict with those reported by Amorim et al. [7] who described the excellent performance of this algorithm as a screening tool in predicting the functional outcome of TBI patients. This discrepancy could be mainly due to the use of different clinical predictors. Indeed, there is large heterogeneity in factors (i.e., age, gender, clinical severity, clinical comorbidities, systolic blood pressure, respiratory rate, lab values, and presence of mass lesion) identified as having a prognostic value in TBI patients, thus making a direct comparison between ML approaches difficult to perform [6]. Another limit is due to the fact the dataset is unbalanced (62.8% negative vs. 37.2% positive outcome) and could negatively affect performances of machine learning. To overcome this issue and increase classification robustness, Thwe researchers also applied the technique of LOOCV that is less affected by this problem and allows themus to compare four machine learning techniques since each type of algorithm performs predictions differently. For instance, the DT algorithm performs well with unbalanced datasets thanks to the splitting rules that look at class variables.
Moreover, the type of predictors, such as continuous and categorized (operator-dependent) variables and the lack of objective biological high-dimensional data (i.e., neuroimaging, genetics), might also limit the performance of ML techniques applied in this domain [11][31]. The Ouresearchers' data would seem to confirm this hypothesis because of the change in identified predictors for classification. Indeed, as shown in Figure 14 and Figure 25, moving from 2 to 4 classes of outcome approaches impacts the most significant features extracted by predictive models. Apart from age, for reaching the excellent performance with the 2 classes approach, LM and ML algorithms need CRS-r values and ERBI values at T1, whereas, for the 4 classes approach, diagnosis at admission and sex are the most important features.
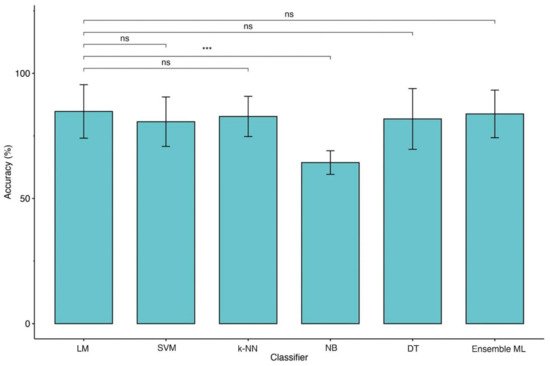
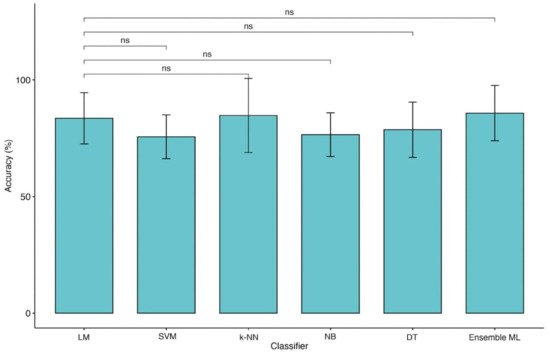
Figure 14. Comparison of accuracies between LM and ML models (2 classes of outcome). Legend: Linear Regression Model (LM), Support Vector Machine (SVM), k-Nearest Neighbors (k-NN), Naïve Bayes (NB), Decision Tree (DT) and Ensemble of Machine Learning models (Ensemble ML). Symbols ***, p-values <0.001.
Figure 25. Comparison of accuracies between LM and ML models (4 classes of outcome). Legend: Linear Regression Model (LM), Support Vector Machine (SVM), k-Nearest Neighbors (k-NN), Naïve Bayes (NB), Decision Tree (DT) and Ensemble of Machine Learning models (Ensemble ML).
Finally, this is the first researchtudy employing an ensemble ML approach to improve the outcome prediction in TBI patients. This approach has been demonstrated to be useful for integrating multiple ML models in a single predictive model characterized by higher robustness, reducing the dispersion of predictions [12][32]. However, this method would not seem to boost performance except when the four classes approach was employed (Figure 25). Indeed, in theour KW analysis, the researchers we observe that the ensemble ML for two classes reach a high accuracy similar to other ML techniques of about 84% for LOOCV and 82% for 10-fold CV as shown in Table 17 while using four classes approach (Table 28) a (not significant) trend of performance metrics was observed (71.5% for LOOCV and 70.5% for 10-fold CV), which is five to ten percentage points higher than the other models.
Table 17. Classification Results with MRMR feature selection using, respectively, LOOCV and 10-fold Cross Validation (2 classes).
| Classification Model |
|---|
8. Classification Results with MRMR feature selection using, respectively, LOOCV and 10-fold Cross Validation (4 classes).
| Classification Model | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cross Validation | |||||||||||||
| Cross Validation | Performance Metric | Linear Model | Support Vector Machine (SVM) | k-Nearest Neighbors (k-NN) |
Naïve Bayes (NB) | Decision Tree (DT) | Ensemble | ||||||
| Performance Metric | Linear Model | Support Vector Machine (SVM) | k-Nearest Neighbors | (k-NN) |
Naïve Bayes (NB) | Decision Tree (DT) | Ensemble | ||||||
| LOOCV | Accuracy | 84.69% | |||||||||||
| LOOCV | Accuracy | 80.61% | 82.65% | 65.31% | 43.88% | 66.33%64.29% | 79.59% | 83.67% | |||||
| 68.37% | 59.18% | 71.43% | Precision µ | ||||||||||
| Precision µ | 84.69% | 80.61% | 82.65% | 64.29% | 65.31%79.59% | 83.67% | |||||||
| Precision M | 83.46% | 79.51% | 81.20% | 64.29% | 78.14% | 82.47% | |||||||
| Recall µ | 64.84% | 58.09% | 61.36% | 37.50% | 56.52% | ||||||||
| 71.93% | |||||||||||||
| 43.88% | 63.08% | ||||||||||||
| F1 Score M | 55.44% | 52.02% | 53.95% | 36.00% | 51.36% | 54.59% | |||||||
| 10-fold CV | Accuracy | 85.89% | 81.78% | 82.78% | 64.33% | 76.78% | 81.78% | ||||||
| Precision µ | 85.71% | 81.63% | 82.65% | 64.29% | 76.53% | 81.63% | |||||||
| Precision M | 84.44% | 80.50% | 81.20% | 64.29% | 74.53% | 80.00% | |||||||
| Recall µ | 66.67% | 59.70% | 61.36% | 37.50% | 52.08% | 59.70% | |||||||
| Recall M | 42.22% | 39.37% | 40.40% | 25.00% | 36.75% | 40.00% | |||||||
| 66.33% | 68.37% | 59.18% | 71.43% | ||||||||||
| Precision M | 66.49% | 36.49% | 66.50% | 52.94% | 46.16% | 71.73% | |||||||
| Recall µ | 38.55% | 20.67% | 39.63% | 41.88% | 32.58% | 45.45% | Recall M | 41.51% | 38.65% | 40.40% | 25.00% | 38.25% | 40.79% |
| Recall M | 36.51% | 23.14% | 37.28% | 38.74% | 30.86% | 41.58% | F1 Score µ | 73.45% | 67.52% | 70.43% | 47.37% | 66.10% | |
| F1 Score µ | 48.48% | 28.10% | 49.62% | 51.94% | 42.03% | 55.56% | |||||||
| F1 Score M | 47.13% | 28.32% | 47.77% | 44.74% | 36.99% | 52.64% | |||||||
| 10-fold CV | Accuracy | 64.22% | 45.00% | 65.33% | 67.44% | 57.44% | 70.44% | ||||||
| Precision µ | 64.28% | 44.89% | 65.31% | 67.34% | 57.14% | 70.41% | |||||||
| Precision M | 65.72% | 36.83% | 65.44% | 52.16% | 45.83% | 70.78% | |||||||
| Recall µ | 37.50% | 21.36% | 38.55% | 40.74% | 30.77% | 44.23% | |||||||
| Recall M | 35.73% | 23.42% | 36.38% | 37.78% | 28.68% | 40.66% | F1 Score µ | 75.00% | 68.97% | 70.43% | 47.37% | 61.98% | 68.97% |
| F1 Score µ | 47.37% | 28.95% | 48.48% | F1 Score M | 56.30% | 52.87% | 53.95% | 36.00% | 49.22% | 53.33% | |||
Table 2
| 50.77% | |||
| 40.00% | |||
| 54.33% | |||
| F1 Score M | |||
| 46.29% | |||
| 28.63% | |||
| 46.77% | 43.82% | 35.28% | 51.65% |
3. Conclusions
In summary, thwe researchers found that ML algorithms do not perform better than more traditional regression models in predicting the outcome after TBI. As future work, the researchers we plan to perform further external validations of all these models on other datasets that could capture dynamic changes in prognosis during intensive care courses extending the current models with new objective predictors, such as neuroimaging data (EEG, PET, fMRI) [13][33].