The stock index is an important indicator to measure stock market fluctuation, with a guiding role for investors’ decision-making, thus being the object of much research. However, the stock market is affected by uncertainty and volatility, making accurate prediction a challenging task.
- stock index forecasting
- CEEMDAN
- ADF
- ARMA
- LSTM
- hybrid model
1. Introduction
2. Stock Index Forecasting Model
2.1. Related Models
2.1.1. CEEMDAN
2.1.2. LSTM
2.1.3. ARMA
2.2. Proposed Model
3. Experimental Results
3.1. Datasets
One-step-ahead prediction is used to verify the prediction accuracy of the proposed CAL model on four major global stock indices: Deutscher Aktien (DAX), Hang Seng (HSI), Standard and Poor’s 500 (S&P500), and Shanghai Stock Exchange Composite (SSE). These have strong representation in the global financial market and can reflect stock market changes, which has much research value. Stock market indices are affected by national policies, market environments, and other factors presenting different characteristics. Research on stock market indices in different financial markets can examine the prediction accuracy of the model.
The statistical analysis of each stock index is shown in Table 1, where we determine the amount of data contained in each stock market index, as well as the average, maximum, minimum, standard deviation, and ADF test results of the closing index. As can be seen from Table 1, there is a large gap between the maximum and minimum values, and a large standard deviation, indicating that these closing indices have great volatility within the research range. Moreover, the ADF test results of the DAX and S&P500 are greater than the threshold 0.05, indicating that the dataset is highly volatile and non-stationary. SSE is somewhat more stable than the other three datasets. Figure 1 shows the sequential change of the closing index within the study range, from which it can be seen that the four indices all have great volatility and instability in the short term.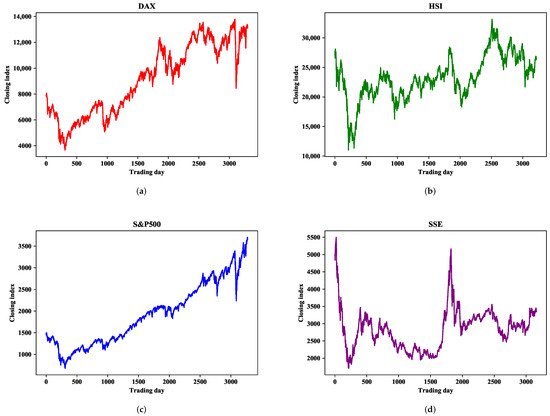
| Index | Count | Mean | Max | Min | Standard Deviation | ADF Test |
|---|---|---|---|---|---|---|
| DAX | 3300 | 9118.21 | 13,789.00 | 3666.41 | 2722.52 | 0.79 |
| HSI | 3219 | 3660.60 | 0.11 | |||
| S&P500 | 3273 | 1915.40 | 3702.25 | 676.53 | 713.03 | 0.99 |
| SSE | 3163 | 2846.43 | 5497.90 | 1706.70 | 586.51 | 0.01 |
3.2. Decomposition Results of EMD and CEEMDAN
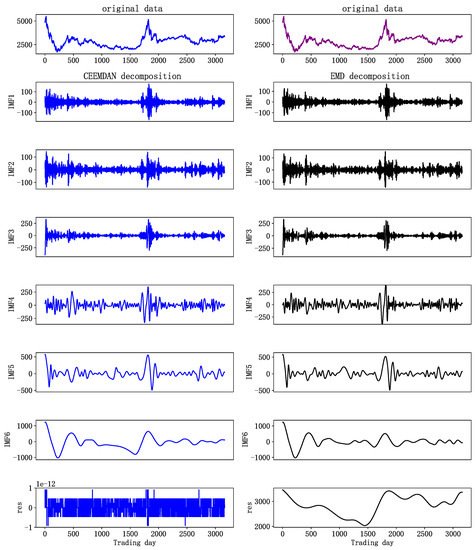
3.3. Summary
-
The proposed CAL model, with CEEMDAN-based methods, outperforms seven benchmark models in predictive accuracy on four stock indices from different developed stock markets, which indicates that methods with multi-scale decomposition can reduce the complexity of sequences, extract hidden features, and improve prediction accuracy.
-
Single data source analysis has certain limitations. Combined analysis with different data sources, such as text information [11], can improve prediction to a certain extent.
-
CAL can obtain predictions closer to real values than CEEMDAN-LSTM, which indicates that components after decomposition may have both linear and non-linear characteristics. Therefore, models combining ARMA and LSTM can obtain more accurate predictions than individual LSTM models.
-
Stock market data contain noise that affects forecast results. Methods, such as wavelet denoising [12] and principal component analysis [13], can eliminate the influence of irrelevant factors and improve the prediction effect to a certain extent.CAL can yield the closest prediction results in comparison to ARIMA-ANN. This indicates that the CAL model has advantages over some traditional hybrid models.The prediction results show that CAL has a smaller prediction error than EMD-ARMA-LSTM does, and this indicates that the CEEMDAN method is superior to EMD in data decomposition.
-
Time series analysis has been applied in fields, such as natural science [In some volatile financial markets, a single prediction model, even improved deep learning model, has limited prediction ability because they cannot excavate internal movement rules of time series and reflect the multi-scale characteristics of financial time series.
-
The linear regression analysis shows the strong correlation between the predicted values and the real values, and the proposed prediction model is effective.
References
- Yan, B.; Aasma, M. A novel deep learning framework: Prediction and analysis of financial time series using CEEMD and LSTM. Expert Syst. Appl. 2020, 159, 113609.
- Zhou, F.; Zhou, H.M.; Yang, Z.; Yang, L. EMD2FNN: A strategy combining empirical mode decomposition and factorization machine based neural network for stock market trend prediction. Expert Syst. Appl. 2019, 115, 136–151.
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147.
- Büyükşahin, Ü.Ç.; Ertekin, Ş. Improving forecasting accuracy of time series data using a new ARIMA-ANN hybrid method and empirical mode decomposition. Neurocomputing 2019, 361, 151–163.
- Wang, Z.; Lou, Y. Hydrological time series forecast model based on wavelet de-noising and ARIMA-LSTM. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 1697–1701.
- Babu, C.N.; Reddy, B.E. A moving-average filter based hybrid ARIMA–ANN model for forecasting time series data. Appl. Soft Comput. 2014, 23, 27–38.
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. London. Ser. Math. Phys. Eng. Sci. 1998, 454, 903–995.
- Cao, J.; Li, Z.; Li, J. Financial time series forecasting model based on CEEMDAN and LSTM. Phys. Stat. Mech. Its Appl. 2019, 519, 127–139.
- Song, H.; Dai, J.; Luo, L.; Sheng, G.; Jiang, X. Power transformer operating state prediction method based on an LSTM network. Energies 2018, 11, 914.
- Ren, B. The use of machine translation algorithm based on residual and LSTM neural network in translation teaching. PLoS ONE 2020, 15, e0240663.
- Hao, P.Y.; Kung, C.F.; Chang, C.Y.; Ou, J.B. Predicting stock price trends based on financial news articles and using a novel twin support vector machine with fuzzy hyperplane. Appl. Soft Comput. 2021, 98, 106806.
- Wu, D.; Wang, X.; Wu, S. A Hybrid Method Based on Extreme Learning Machine and Wavelet Transform Denoising for Stock Prediction. Entropy 2021, 23, 440.
- Yang, K.; Liu, Y.L.; Yao, Y.N.; Fan, S.D.; Mosleh, A. Operational time-series data modeling via LSTM network integrating principal component analysis based on human experience. J. Manuf. Syst. 2020, 61, 746–756.
- Coyle, D.; Prasad, G.; McGinnity, T.M. Extracting features for a brain-computer interface by self-organising fuzzy neural network-based time series prediction. In Proceedings of the 26th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Francisco, CA, USA, 1–5 September 2004; Volume 2, pp. 4371–4374.
- Wang, J.; Zhang, W.; Li, Y.; Wang, J.; Dang, Z. Forecasting wind speed using empirical mode decomposition and Elman neural network. Appl. Soft Comput. 2014, 23, 452–459.