Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 3 by Camila Xu and Version 2 by Camila Xu.
Recently, machine Learning (ML) has been highly used in many areas, such as speech recognition and image processing. The revolution in industrial technology using ML proves the great success of ML and its applications in analyzing complex patterns, which are presented in a variety of applications in a wide range of sectors, including healthcare.
- interpretability
- machine learning
- healthcare
1. Introduction
Recently, machine Learning (ML) has been highly used in many areas, such as speech recognition [1] and image processing [2]. The revolution in industrial technology using ML proves the great success of ML and its applications in analyzing complex patterns, which are presented in a variety of applications in a wide range of sectors, including healthcare [3]. However, the best performance models belong to very complex or ensemble models that are very difficult to explain (black-box) [4]. Figure 1 shows the trade-off between accuracy and interpretability of machine learning algorithms.
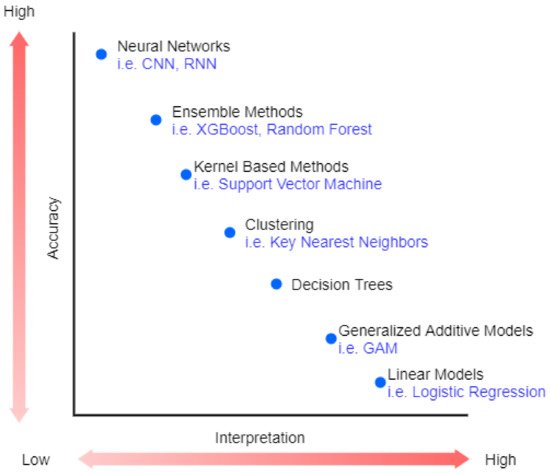
Figure 1. The trade-off between accuracy and interpretability.
In healthcare, medical practitioners embrace evidence-based practice as the guiding principle, which combines the most up-to-date research with clinical knowledge and patient conditions [5]. Moreover, implementing a non-interpretable machine learning model in medicine raises legal and ethical issues [6]. In real-world practice, explanations to why decisions have been made are required, such as by General Data Protection Regulation (GDPR) in the European Union. Thus, relying on diagnosis or treatment decision-making to black-box ML models violates the evidence-based medicine principle [4] because there is no explanation in terms of reasoning or justification for particular decisions in individual situations. Therefore, machine learning interpretability is an important feature needed for adopting such methods in critical scenarios that arise in fields such as medical health or finance [7]. Priority should be given in providing machine learning solutions that are interpretable over complex non-interpretable machine learning models with high accuracy [8].
In recent years, interpretable machine learning (IML) has emerged as an active research area. The efforts aim at creating transparent and explainable ML models by developing methods that transform the ML black-box into a white box [9] in order to minimize the trade-off gap between model accuracy and interpretability. Figure 2 shows that the research efforts started sometime in 2012 and received growing attention since then, as evidenced by the number of articles published in Web of Science (WoS) [10].
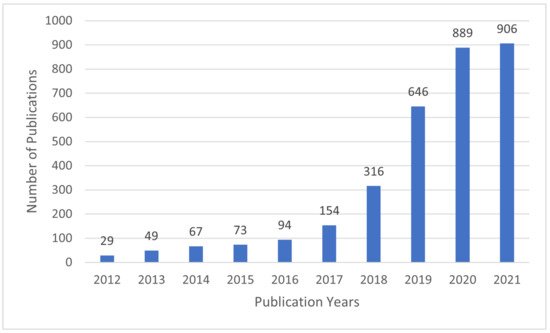
Figure 2. The number of articles related to IML per year in Web of Science.
2. Taxonomy of IML
A Taxonomy of IML will provide overview and main concepts that are useful for researchers and professionals. We propose a taxonomy for IML based on a survey conducted from several related papers [3,7,10,11,12,17,18,19][3][7][10][11][12][13][14][15]. Several methods and strategies have been proposed for developing machine learning interpretable models as shown by the taxonomy in Figure 3. First, the ML model chosen is classified into a type of complexity-related. Based on the type of complexity-related, the ML model is further classified into a type of model-related. Finally, the outcome is classified into a type of scope-related. The following sections provide some details about complexity-related, model-related, and scope-related.
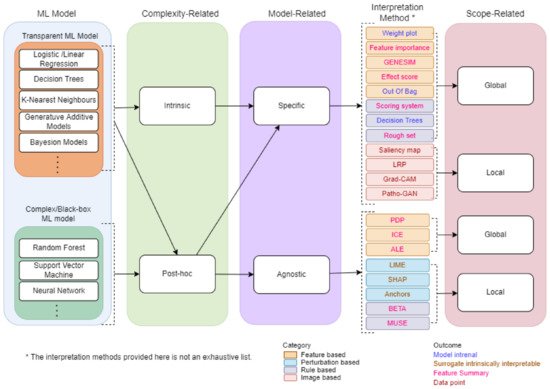
Figure 3. The taxonomy of machine learning interpretability.
2.1. Complexity-Related
Model interpretability is mainly related to the complexity of ML that is used to build the model. Generally speaking, models with more complex ML algorithms are more challenging to interpret and explain. In contrast, models with more straightforward ML algorithms are easiest to interpret and explain [20][16]. Therefore, ML models can be categorized into two criteria: intrinsic or post hoc.
Intrinsic interpretability model uses transparent ML model, such as sparse linear models or short decision trees. Interpretability is achieved by limiting the ML model complexity [21][17] in such a way that the output is understandable by humans. Unfortunately, in most cases, the best performance of ML models belongs to very complex ML algorithms. In other words, model accuracy requires more complex ML algorithms, and simple ML algorithms might not make the most accurate prediction. Therefore, intrinsic models are suitable when interpretability is more important than accuracy.
2.2. Model-Related
Model-related interpretability model uses any ML algorithms (model-agnostic) or only a specific type or class of algorithm (model-specific). Model-specific is limited to a particular model or class in such a way that the output explanations are derived by examining the internal model parameters, such as interpreting the regression weights in a linear model [9].
Model-agnostic interpretability models are not restricted to a specific ML model. In these models, explanations are generated from comparing input and output features at the same time. This approach does not necessarily access the internal model structure such as the model weights or structural information [7]. Usually, a surrogate or a basic proxy model is used to achieve model-agnostic interpretability. The surrogate model is a transparent ML model that can learn to approximate or mimic a complex black-box model using the black-box’s outputs [21][17]. Surrogate models are commonly used in engineering. The idea is to create a simulation model that is cheap, fast, and simple to mimic the behaviours of the expensive, time-consuming, or complex model that is difficult to measure [23][19]. Model-agnostic methods separate the ML model from the interpretation method, giving the developer the flexibility to switch between models with low cost.
For a better understanding of the model-related taxonomy, Table 1 provides a summary of the pros and cons of each category.
Table 1. The pros and cons of model-related taxonomy.
| Model Type | Pros | Cons |
|---|---|---|
| Model-specific | Most method explanations are intuitive. Very fast. Highly translucent. Interpretations are more accurate. |
Limited to a specific model. High switching cost. Feature selection is required to reduce dimensionality and enhance the explanation. |
| Model-agnostic | Easy to switch to another model. Low switching cost. No restrictions on the ML model. Not limited to a specific model. |
Cannot access model internals. Interpretations are less accurate. |
2.3. Scope-Related
The scope of the IML explanations depends on whether the IML model applies to a specific sample to understand the prediction of the applied ML in this sample or applies to the entire model samples in attempts to explain the whole model behaviours. Therefore, methods that describe a single prediction are considered as local interpretation, and methods that describe the whole action of the model are considered as global interpretation [7].
Local interpretation refers to an individual explanation that justifies why the model generated a specific prediction for a specific sample. This interpretability aims to explain the relationship between a particular input data and the generated prediction. It is possible to obtain a local understanding of the models by constructing justified model structures. This can also be done by presenting identical examples of instances to the target instance [9]. For example, by highlighting a patient’s unique features identical to those of a smaller group of patients, they are distinct from other patients.
Global interpretation, however, provides transparency about how the model works at an abstract level. This kind of interpretability aims to figure out how the model generates decisions based on a comprehensive view of its features and learned individual components such as weights, structures, and other parameters. A trained model, algorithm, and data information are required to understand the model’s global performance of the model [22][18].
2.4. Summary on Interpretable Machine Learning Taxonomy
Based on complexity, complexity-related ML models could be intrinsic or post hoc. Intrinsic models interpret ML models by restricting the ML complexity, i.e., the maximum depth of the Decision Trees algorithm must be at least 5 to be understandable. Applying such roles to interpret a specific model makes intrinsic models by default considered model-specific. Model-specific techniques, in general, are techniques that only apply to the interpretation of a particular ML model. The model-specific explanation output can be generated to explain a specific prediction for a specific sample (local interpretation) or to comprehend the model’s decisions from a holistic perspective (global interpretation).
Post hoc models, on the other hand, are related to interpretation methods used after the ML model has been trained. Post hoc interpretation methods can be either model-specific or model-agnostic according to the domain of the applied interpretable method, whether it is for a specific ML model (model-specific) or applied to all ML models (model-agnostic).
In the next section, we will give an overview of interpretation in IML, its properties, and outcomes.
3. Interpretability in Machine Learning
3.1. Overview
The term interpret explains the meaning of something in an understandable way. Instead of general interpretability, we concentrate on using interpretations as part of the broader data science life cycle in ML. The terms interpretability and explainability are being used interchangeably in literature [24[20][21],25], but there are some papers that make distinctions [26,27][22][23]. Rudin and Ertekin [27][23] argue that the term explainable ML is used to explain black-box models whereas interpretable ML is used for models that are not black-box. Gaur et al. [26][22] argue that explainability answers the question of why a certain prediction has been made whereas interpretability answers the question of how the model predicts a certain prediction. Our paper follows the first approach, where the terms interpretability and explainability are used interchangeably. However, the formal definition of interpretability remains elusive in machine learning as there is no mathematical definition [28][24].
A popular definition of interpretability frequently used by researchers [29,30][25][26] is interpretability in machine learning is a degree to which a human can understand the cause of a decision from an ML model. It can also be defined as the ability to explain the model outcome in understandable ways to a human [31][27]. The authors of [32][28] defined interpretability as the use of machine learning models to extract specific data-contained information of domain relationships. If it gives insight into a selected domain issue for a specific audience; they see information as necessary. [12] describe the primary purpose of interpretability as being to effectively explain the model structure to users. Depending on the context and audience, explanations may be generated in formats such as mathematical equations, visualizations, or natural language [33][29]. The primary goal of interpretability is to explain the model outcomes in a way that is easy for users to understand. IML consists of several main components: (1) the machine learning model, (2) the interpretation methods, and (3) the outcomes. The interpretation methods exhibit some properties as described in the following subsections.
3.2. Properties of Interpretation Methods
This section presents the properties needed to judge how good the interpretation method is. Based on the conducted review, we identified the essential proprieties as explained below.
3.2.1. Fidelity
Yang et al. [34][30] define explanation fidelity in IML as the degree of faithfulness with respect to the target system to measure the connection of explanations in practical situations. Fidelity, without a doubt, is a crucial property that an interpretable method needs to have. The methods cannot provide a trusted explanation if it is not faithful to the original model. The IML explanations must be based on the mapping between ML model inputs and outputs to avoid inaccurate explanations [35][31]. Without sufficient fidelity, explanations will be restricted only to generate limited insights into the system, which reduces the IML’s functionality. Therefore, to evaluate explanations in IML, we need fidelity to ensure the relevance of the explanations.
3.2.2. Comprehensibility
Yang et al. [34][30] define the comprehensibility of explanations in IML as the degree of usefulness to human users, which serves as a measure of the subjective satisfaction or intelligibility of the underlying explanation. It reflects to what extent the extracted representations are humanly understandable and how people understand and respond to the generated explanations [18][14]. Therefore, good explanations are most likely to be easy to understand and allow human users to respond quickly. Although it is difficult to define and measure because it depends on the audience, it is crucial to get it right [7]. Comprehensibility is divided into two sub-properties [35][31]: (1) high clarity: refers to how clear the explanation is as a result of the process, and (2) high parsimony: refers to the intricacy of the resultant explanation.
3.2.3. Generalizability
Yang et al. [34][30] define the generalizability of explanations in IML as an index of generalization performance in terms of the knowledge and guidance provided by the related explanation. It is used to express how generalizable a given explanation is. Users can assess how accurate the generated explanations are for specific tasks by measuring the generalizability of explanations [36][32]. Human users primarily utilize explanations from IML methods in real-world applications to gain insight into the target system, which naturally raises the requirements for explanation generalizability. If a group of explanations is not well-generalized, it cannot be considered high-quality as the information and guidance it provides will be restricted.
3.2.4. Robustness
The robustness of explanations primarily measures the explanations’ similarity between similar instances. For a given model, it compares explanations between similar instances. The term “high robustness” refers to the fact that minor changes in an instance’s features do not considerably affect the explanation (unless the minor changes also significantly affect the prediction) [37][33]. A lack of robustness may be the result of the explanation method’s high variance. In other words, small changes in the feature values of the instance being explained significantly impact the explanation method. Non-deterministic components of the explanation approach might also result from a lack of robustness, e.g., a step of data sampling as used by the local surrogate method [5]. As a result, the two most essential factors to obtaining explanations with high robustness are generally an ML model that provides stable predictions and an interpretation method that generates a reliable explanation [38][34].
3.2.5. Certainty
Certainty assesses the degree to which the IML explanations confidently reflect the target ML. Many machine learning models only provide predictions with no evidence of the model’s certainty that the prediction is correct. In [39[35][36],40], the authors focus on the model explanations certainty and provide insights into how convinced users could be with the generated explanations given to a particular outcome. In essence, the evaluations of certainty and comprehensibility can complement one another. As a result, an explanation that incorporates the model’s certainty is quite beneficial.
To the best of our knowledge, there are no methods available to correctly measure these proprieties. The main reason is that some of them are related to real-world objectives, which are difficult to encode as mathematical functions [41][37]. The properties also affect the quality of the interpretation outcomes. In the following section, the outcomes of IML methods will be discussed.
3.3. Outcomes of IML
The main goal of using an interpretable ML model is to explain the outcome of the ML model to users in an understandable way. Based on the interpretable method used [7,28][7][24], the interpretation outcome can be roughly distinguished into one of the following stages:
Feature summary: Explaining ML model outcome by providing a summary (statistic or visualization) for each feature extracted from ML model.
- -Feature summary statistics: ML model outcomes describing statistic summary for each feature. The statistic summary contains a single number for each feature, such as feature importance, or a single number for each couple of features, such as pairwise feature interaction strengths.-Feature summary visualization: Visualizing the feature summary is one of the most popular methods. It provides a visualization in form of graphs representing the impact of the feature to the ML model prediction.
Model internals: The model outcomes are presented in model intrinsic form such as the learned tree structure of decision trees and the weights of linear models.
Data point: Data point results explain a sample’s prediction by locating a comparable sample and modifying some of the attributes for which the expected outcome changes in a meaningful way, i.e., counterfactual explanations. Interpretation techniques that generate new data points must be validated by interpreting the data points themselves. This is great for images and text, but not so much for tabular data with a lot of features.
Surrogate intrinsically interpretable model: Surrogate models are another way to interpret the ML model by approximating them with the intrinsically interpretable model and then providing the internal model parameters or feature summary.
References
- Chan, W.; Park, D.; Lee, C.; Zhang, Y.; Le, Q.; Norouzi, M. SpeechStew: Simply mix all available speech recognition data to train one large neural network. arXiv 2021, arXiv:2104.02133.
- Ding, K.; Ma, K.; Wang, S.; Simoncelli, E.P. Comparison of full-reference image quality models for optimization of image processing systems. Int. J. Comput. Vis. 2021, 129, 1258–1281.
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160.
- London, A.J. Artificial intelligence and black-box medical decisions: Accuracy versus explainability. Hastings Cent. Rep. 2019, 49, 15–21.
- Scott, I.; Cook, D.; Coiera, E. Evidence-based medicine and machine learning: A partnership with a common purpose. BMJ Evid. Based Med. 2020, 2020 26, 290–294.
- Amann, J.; Blasimme, A.; Vayena, E.; Frey, D.; Madai, V.I. Explainability for artificial intelligence in healthcare: A multidisciplinary perspective. BMC Med. Inform. Decis. Mak. 2020, 20, 310.
- Molnar, C. Interpretable Machine Learning. 2020. Lulu.com. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 2 November 2021).
- Ahmad, M.A.; Eckert, C.; Teredesai, A. Interpretable machine learning in healthcare. In Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Washington, DC, USA, 29 August–1 September 2018; pp. 559–560.
- Stiglic, G.; Kocbek, P.; Fijacko, N.; Zitnik, M.; Verbert, K.; Cilar, L. Interpretability of machine learning-based prediction models in healthcare. Wiley Interdiscip.-Rev.-Data Min. Knowl. Discov. 2020, 10, e1379.
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832.
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Interpretable machine learning: Definitions, methods, and applications. arXiv 2019, arXiv:1901.04592.
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89.
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115.
- Belle, V.; Papantonis, I. Principles and practice of explainable machine learning. arXiv 2020, arXiv:2009.11698.
- Lakkaraju, H.; Kamar, E.; Caruana, R.; Leskovec, J. Interpretable & explorable approximations of black box models. arXiv 2017, arXiv:1707.01154.
- Salman, S.; Payrovnaziri, S.N.; Liu, X.; Rengifo-Moreno, P.; He, Z. DeepConsensus: Consensus-based Interpretable Deep Neural Networks with Application to Mortality Prediction. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8.
- Du, M.; Liu, N.; Hu, X. Techniques for interpretable machine learning. Commun. ACM 2019, 63, 68–77.
- Lipton, Z.C. The Mythos of Model Interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57.
- Jiang, P.; Zhou, Q.; Shao, X. Surrogate Model-Based Engineering Design and Optimization; Springer: Berlin/Heidelberg, Germany, 2020.
- Clinciu, M.A.; Hastie, H. A survey of explainable AI terminology. In Proceedings of the 1st Workshop on Interactive Natural Language Technology for Explainable Artificial Intelligence (NL4XAI 2019), Tokyo, Japan, 29 October 2019; pp. 8–13.
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 0210–0215.
- Gaur, M.; Faldu, K.; Sheth, A. Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable? IEEE Internet Comput. 2021, 25, 51–59.
- Rudin, C.; Ertekin, Ş. Learning customized and optimized lists of rules with mathematical programming. Math. Program. Comput. 2018, 10, 659–702.
- Molnar, C.; Casalicchio, G.; Bischl, B. Interpretable Machine Learning—A Brief History, State-of-the-Art and Challenges. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Cham, Switzerland, 2020.
- Biran, O.; Cotton, C. Explanation and justification in machine learning: A survey. In Proceedings of the IJCAI-17 Workshop on Explainable AI (XAI), Melbourne, Australia, 20 August 2017; Volume 8, pp. 8–13.
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38.
- Doshi-Velez, F.; Kim, B. A roadmap for a rigorous science of interpretability. arXiv 2017, arXiv:1702.08608.
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080.
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15.
- Yang, F.; Du, M.; Hu, X. Evaluating explanation without ground truth in interpretable machine learning. arXiv 2019, arXiv:1907.06831.
- Ras, G.; van Gerven, M.; Haselager, P. Explanation methods in deep learning: Users, values, concerns and challenges. In Explainable and Interpretable Models in Computer Vision and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2018; pp. 19–36.
- Doshi-Velez, F.; Kim, B. Considerations for evaluation and generalization in interpretable machine learning. In Explainable and Interpretable Models in Computer Vision and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–17.
- Yan, L.; Zhang, H.T.; Goncalves, J.; Xiao, Y.; Wang, M.; Guo, Y.; Sun, C.; Tang, X.; Jing, L.; Zhang, M. An interpretable mortality prediction model for COVID-19 patients. Nat. Mach. Intell. 2020, 2, 283–288.
- Yeh, C.K.; Hsieh, C.Y.; Suggala, A.S.; Inouye, D.I.; Ravikumar, P. How Sensitive are Sensitivity-Based Explanations? arXiv 2019, arXiv:1901.09392.
- Phillips, R.; Chang, K.H.; Friedler, S.A. Interpretable active learning. In Proceedings of the Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018; pp. 49–61.
- Ustun, B.; Spangher, A.; Liu, Y. Actionable recourse in linear classification. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 10–19.
- Lipton, Z.C. The Mythos of Model Interpretability. Commun. ACM 2018, 61, 36–43.
More