Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 3 by Nora Tang and Version 2 by Surya Michrandi Nasution.
The traffic composition in developing countries comprises of variety of vehicles which include cars, buses, trucks, and motorcycles. Motorcycles dominate the road with 77.5% compared to other types. Meanwhile, route recommendation such as navigation and Advanced Driver Assistance Systems (ADAS) is limited to particular vehicles only. Traffic condition prediction aims to discuss the proper method to result a better prediction analysis. Route recommendation aims to explore the existing work on how to provide the best route for users. The two domains would be the parts of our framework to result contextual route recommendations in heterogeneous traffic flow.
- route recommendation
- heterogeneous traffic flow
- traffic prediction
- knowledge growing bayes classifier
- artificial intelligence
1. Prediction of Traffic Condition
There are numerous common methods to predicts traffic condition, namely Neural Networks [24[1][2][3],25,26], Deep Neural Networks [27][4], and Deep Learning [28][5]. It works based on network which created from training data and tries to predict the next situation using the networks. Kumar et al., implemented a combination of Multi-Layer Perceptron on Neural Network configuration to predict traffic conditions [24][1]. Based on their results, Neural Network has consistent performance for several time intervals for traffic prediction.
Hu et al., also implemented Neural Network with Backpropagation to predict short-term traffic [25][2]. They claimed Neural Network with Backpropagation is an effective method to use as short-term traffic prediction. Meanwhile, Nasution et al., tried to predict traffic conditions based on a voting system from several Neural Networks [26][3]. Their system delivers a better performance than conventional methods of Neural Network.
The improvement of Neural Networks also aids the prediction of the condition of traffic. Yi et al. claimed Deep Neural Network could estimate traffic congestion [27][4]. By using three hidden layers (40, 50, and 40 neurons), the tanh activation function, and AdaGrad optimization algorithm, the system achieved 99% accuracy in predicting congestion. On the other hand, Lv et al., stated that Deep Learning can understand the traffic feature without prior knowledge. They applied Stack Autoencoders as their main method, and compared it with Backpropagation Neural Network, Random Walk, Support Vector Machine, and Radial Basis Function. It happened that their proposed method has the smallest error rate among other methods.
The prediction of a condition could be implemented in the short-term and long-term. The Autoregressive Integrated Moving Average (ARIMA) model has a capability to predicts a future condition using time series data, such traffic flow [29][6] or passenger flow [30][7]. Chen et al. predicts passenger flow in subway stations using ARIMA model and its variances (SGARCH, EGARCH, GJRGARCH, NAGARCH). Based on their results on a subway station, basic ARIMA model has the highest Mean Average Percentage Error (27.971%). Meanwhile, ARIMA NAGARCH has the lowest error (MAPE = 9.056%) among all the compared ARIMA models.
The other common methods for predicting the traffic condition are Decision Trees [31][8] and Bayesian [11,32,33][9][10][11]. A Decision Tree creates a classification system using Information Gain and Entropy of the data. Sujatha et al., detected traffic congestion by using this method and comparing it with the Neural Network method [31][8]. Even though the performance of Decision Tree is not as good as Neural Network, it can predict faster. Meanwhile, Bayesian methods predicts the situation based on the probability of the conditions [11][9]. Khan et al., forecasts traffic situation at junctions using Bayesian Model [32][10]. The traffic condition is determined based on the principles of conditional probability distributions. The accuracy rate of their system reaches 73% when predicting the 5-level traffic states. Anitha et al., uses Naïve Bayes to predict the traffic based on multi-source data [33][11]. According to their result, this method is not only easy to build and useful in handling a very large dataset, but it also outperforms the other highly sophisticated classification methods. In general, Decision Tree and Bayesian runs efficiently since these methods need not process the training data into another form.
Despite of the greatness of these methods, they seem incapable of handling the real-world situations which have dynamic conditions. It may appear with changes and instability of traffic conditions which are difficult to address with previous methods. In particular, there are lots of attributes that could change the traffic conditions.
The Knowledge Growing System is one of the important concepts used to deal with the mentioned changes in order to enhance the model’s prediction capabilities [34,35][12][13]. The use of growing the data concept in conventional machine learning methods is likely to boost its performances due to the data’s periodic growth over time. Figure 1 shows that data training in t−1 time predict the current (t) traffic condition based its testing data. The result of this pipeline is not only to determine the traffic condition at time (t), but also to grow the dataset using the current testing data and the prediction result.
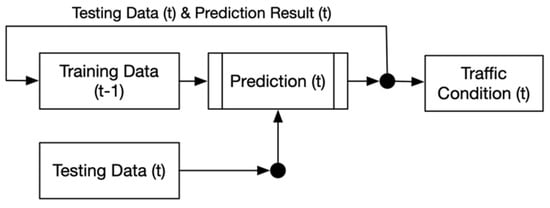
Figure 1. Scheme of Knowledge Growing Prediction Methods.
The basic concept of Knowledge Growing System tries to imitate the human’s inferencing capability using their senses. In its implementation, the human’s senses are replaced using sensors and its information is combined using information fusion methods in order to define a condition (or knowledge) [34][12]. In the Knowledge Growing System, every new condition will be stored in a knowledge database [35][13]. Later, whenever there is similar information that is collected, the system will easily understand the condition based on its knowledge database.
Husni et al., compared several methods for predicting the traffic condition by using the Knowledge Growing concept, and compared their performances over time [23][14]. Based on their results, Knowledge Growing Bayes Classifier had the highest performance gain among other methods (Knowledge Growing Deep Neural Network and Knowledge Growing Decision Tree). Knowledge Growing Bayes Classifier is also the fastest method compared to others, since it only calculates the probability of each traffic condition.
Although their method shows great results when using a dataset that grows over time, it predicts each road segment using whole map datatest and it makes the prediction not specific to selected road. Based on this situation, there will be a probability that the system will predict the traffic condition using other roads’ data. The attributes that are used in their paper are days, time, origin, destination, road width, weather, weather location, and traffic condition.
All prediction results illustrate each road segment condition specifically. We also simplified the attributes into “Days”, “Rush Hour”, “Weather”, “Temperature”, “Traffic Condition”. The attributes “Origin” and “Destination” exclude from dataset since it already specified for its road segments. The attribute of time is adjusted into rush hour status which could be used to define the traffic better. The static attribute “Road Width” also excludes from the prediction system, it also cannot describe the road situation clearly. Meanwhile the weather aspect is expanded to its condition and temperature.
2. Route Recommendation
Route recommendation aims to provide the best route for users. In order to define the recommended route, it could be calculated by using the route choice model approach. Route choice model tries to find the best path for drivers from an origin to a destination [36,37][15][16] among several alternative routes [38][17]. One of the most common methods in route choice model is shortest path algorithm [36,39][15][18]. It tries to determine the shortest or fastest route in a graph of road network.
Route Recommendation starts with the conversion from the road networks into directed graph which has nodes, edges, and weights. Intersections and road segments in road network will be nodes and edges in a graph. Meanwhile, the traffic conditions [40][19], travel distance [41][20], travel time [42][21], pricing (ridesharing) [43[22][23],44], etc. could be described as the weight of the graph. Shortest path algorithm will find the recommended route based on the weight compilation from all observed road segments by finding the minimum sum of weights from the origin to a particular destination. The compilation of weight is based on several attributes that effects situation of the road.
Attributes of Road Situation
Generally, the use of a driving assistant system to find the best route minimizes the travel time [42,45,46][21][24][25]. On the other hand, to support the convenience and safety of driving, the other attributes in driving should be considered. There are several attributes that should be used in defining the route, such as easy-driving, popular or familiar routes [47][26], road infrastructure (road length and width) [20][27], emission (eco-driving) [40,48][19][28]. Moreover, for several types of vehicle, weather is also considered as an important attribute to decide the travel route [9,10,11,12,13,14,15,16][29][30][9][31][32][33][34][35].
He et al. [49][36] collaborate the time and road length to find the route for taxis based on the driver’s experience and preferences. By using collective intelligence, they tried to calculate top k-routes for the taxi drivers. Meanwhile, Kazhaev et al. [50][37], tried to determine the best route by reducing the conflict situation at public transportation stop-point. The conflict situation refers to competition among drivers who feel prioritized. This situation increases the throughput capacity at the stop-point, and it will inflict a congestion. The result of this research shows that the reduction in conflict situation also will minimize total delay while travelling.
Driver’s preference is also something that must be considered. Based on Shenpei and Xinping [47][26] who consider the driver’s preferences (using familiar routes) with traffic light, it could calibrate the delay time and create a strategy to passing through the signalized intersection (based on driver behavior).
The implementation of multi-attributes combination is done by Paiva et al. [51][38], by creating driving assistance that collects weather information, driving behavior, road situation, or condition inside the vehicle. Weather is considered as the most important attribute in the road, especially in bad weather (ice sheet).
Information of traffic congestion is also needed in order to find the best travel route. Namoun et al. used a traffic congestion for the prediction of traffic condition [40][19]. The information source that used is comes from road-side sensors and floating car. The traffic condition is used to find the best type of vehicle which has waiting time while traveling. Others existing system also tried to combine several attributes to define the routes [41,52,53,54][20][39][40][41].
Table 1 shows the comparison of attributes between existing and proposed framework. In this paper, the collaboration of multi-attributes is conducted which will be used as determination of the best route based on driver’s preference. The attributes that are used for finding the best route are the prediction of traffic condition, weather condition, temperature, humidity, heterogeneity, current travel speed, road length and width.
Table 1. Attributes Comparison between Proposed and Existing Framework.
| Data Source | Attributes | User Preferences | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Traffic Condition | Weather | Temperature | Humidity | Road Infrastructure | Travel Time | Heterogeneity | Compatibility | ||||
| [20] | [27] | Electric Vehicle | × | × | × | × | ✓ | ✓ | × | × | × |
| [45] | [24] | Mobil Robots | × | × | × | × | × | ✓ | × | × | × |
| [46] | [25] | PetriNets | × | × | × | × | × | ✓ | × | × | × |
| [42] | [21] | GPS | × | × | × | × | × | ✓ | × | × | × |
| [47] | [26] | - | × | × | × | × | × | ✓ | × | × | ✓ |
| [48] | [28] | Real Data | × | × | × | × | × | × | ✓ | × | × |
| [40] | [19] | Live Traffic Data | ✓ | × | × | × | ✓ | ✓ | × | × | × |
| [49] | [36] | Vehicle’s Trajectories | × | × | × | × | ✓ | ✓ | × | × | ✓ |
| [50] | [37] | - | × | × | × | × | × | ✓ | × | × | × |
| [51] | [38] | Multi Sensors | × | ✓ | ✓ | ✓ | × | × | × | ✓ | ✓ |
| [41] | [20] | GPS Log | × | × | × | × | ✓ | × | × | × | × |
| [52] | [39] | - | × | × | × | × | ✓ | ✓ | × | × | ✓ |
| [53] | [40] | Smartphone & IoT | × | × | × | × | × | ✓ | × | × | ✓ |
| [54] | [41] | Real Weather Data | × | ✓ | ✓ | × | × | ✓ | × | ✓ | × |
| Proposed Framework | CCTV & TomTom | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
References
- Kumar, K.; Parida, M.; Katiyar, V.K. Short Term Traffic Flow Prediction for a Non Urban Highway Using Artificial Neural Network. Procedia—Soc. Behav. Sci. 2013, 104, 755–764.
- Hu, W.; Liu, Y.; Li, L.; Xin, S. The Short-Term Traffic Flow Prediction Based on Neural Network. In Proceedings of the 2nd International Conference on Future Computer and Communication, Wuhan, China, 21–24 May 2010.
- Nasution, S.M.; Husni, E.; Yusuf, R.; Kuspriyanto. Semi-Ensemble Learning Using Neural Network for Classifying Traffic Condition. In Proceedings of the 6th International Conference on Information Technology Systems and Innovation, ICITSI 2020, Bandung, Indonesia, 19–23 October 2020.
- Yi, H.; Jung, H.; Bae, S. Deep Neural Networks for Traffic Flow Prediction. In Proceedings of the IEEE international conference on big data and smart computing (BigComp), Jeju Island, Korea, 13–16 February 2017.
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.-Y. Traffic Flow Prediction With Big Data: A Deep Learning Approach. Intell. Transp. Syst. IEEE Trans. 2014, 16, 1–9.
- Kumar, S.V.; Vanajakshi, L. Short-Term Traffic Flow Prediction Using Seasonal ARIMA Model with Limited Input Data. Eur. Transp. Res. Rev. 2015, 7, 1–9.
- Chen, E.; Ye, Z.; Wang, C.; Xu, M. Subway Passenger Flow Prediction for Special Events Using Smart Card Data. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1109–1120.
- Sujatha, R.; Nithya, R.A.; Subhapradha, S.; Srinithibharathi, S. Decision Tree Classification for Traffic Congestion Detection Using Data Mining. Int. J. Eng. Tech. 2018, 4, 166–173.
- Rahman, F.I.; Hasnat, A.; Lisa, A.A. Traffic Flow Prediction by Incorporating Weather Information in Naïve Bayes Classifier. J. Adv. Civ. Eng. Pract. Res. 2019, 8, 10–16.
- Khan, S.Z.; Rahuman, W.M.A.; Dey, S.; Anwar, T.; Kayes, A.S.M. Road Crowd: An Approach to Road Traffic Forecasting at Junctions Using Crowd-Sourcing and Bayesian Model. In Proceedings of the International Conference on Research and Innovation in Information Systems (ICRIIS), Langkawi Island, Malaysia, 16–17 July 2017; pp. 1–6.
- Anitha, E.B.; Aravinth, R.; Deepak, S.; Jotheeswari, R.; Karthikeyan, G. Prediction of Road Traffic Using Naive Bayes Algorithm. Int. J. Eng. Res. Technol. 2019, 7, 1–4.
- Sumari, A.; Ahmad, A.; Wuryandari, A. Knowledge Growing System: A New Perspective on Artificial Intelligence. In Proceedings of the 5th International Conference Information & Communication Technology and System, London, UK, 20–21 February 2009.
- Sumari, A.D.W.; Ahmad, A.S.; Wuryandari, A.I.; Sembiring, J.; Widjajati, F.A. An Introduction To Knowledge-Growing System: A Novel Field in Artificial Intelligence. JUTI J. Ilm. Teknol. Inf. 2010, 8, 11.
- Husni, E.; Nasution, S.M.; Kuspriyanto; Yusuf, R. Predicting Traffic Conditions Using Knowledge-Growing Bayes Classifier. IEEE Access 2020, 8, 191510–191518.
- Li, D.; Yang, M.; Jin, C.J.; Ren, G.; Liu, X.; Liu, H. Multi-Modal Combined Route Choice Modeling in the MaaS Age Considering Generalized Path Overlapping Problem. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2430–2441.
- Cao, Q.; Ren, G.; Li, D.; Ma, J.; Li, H. Semi-Supervised Route Choice Modeling with Sparse Automatic Vehicle Identification Data. Transp. Res. Part C Emerg. Technol. 2020, 121, 102857.
- Ben-Akiva, M.E.; Ramming, M.S.; Bekhor, S. Route Choice Models. In Human Behaviour and Traffic Networks; Springer: Berlin/Heidelberg, Germany, 2004; pp. 23–45.
- Prato, C.G. Route Choice Modeling: Past, Present and Future Research Directions. J. Choice Model. 2009, 2, 65–100.
- Namoun, A.; Tufail, A.; Mehandjiev, N.; Alrehaili, A.; Akhlaghinia, J.; Peytchev, E. An Eco-Friendly Multimodal Route Guidance System for Urban Areas Using Multi-Agent Technology. Appl. Sci. 2021, 11, 2057.
- Ge, Y.; Li, H.; Tuzhilin, A. Route Recommendations for Intelligent Transportation Services. IEEE Trans. Knowl. Data Eng. 2021, 33, 1169–1182.
- Yang, Z.S.; Cai, C.Q.; Bao, L.X. Intelligent In-Vehicle Control and Navigation Based on Multi-Route Traffic Optimization. In Proceedings of the International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006; pp. 962–966.
- Wu, C.; le Vine, S.; Sivakumar, A.; Polak, J. Dynamic Pricing of Free-Floating Carsharing Networks with Sensitivity to Travellers’ Attitudes towards Risk. Transportation 2021, 2019, 16.
- Ma, J.; Xu, M.; Meng, Q.; Cheng, L. Ridesharing User Equilibrium Problem under OD-Based Surge Pricing Strategy. Transp. Res. Part B Methodol. 2020, 134, 1–24.
- Das, P.; Ribas-Xirgo, L. Parameter Estimation for Optimal Path Planning in Internal Transportation. CoRR 2018, arXiv:1808.00522.
- Qu, Y.; Li, L.; Liu, Y.; Chen, Y. Travel Routes Estimation in Transportation Systems Modeled by Petri Nets. In Proceedings of the 2010 IEEE International Conference on Vehicular Electronics and Safety, QingDao, China, 15–17 July 2010; pp. 73–77.
- Zhou, S.; Yan, X. Driver’s Route Choice Model Based on Traffic Signal Control. In Proceedings of the 3rd IEEE Conference on Industrial Electronics and Applications, Singapore, 3–5 June 2008; pp. 2331–2334.
- Ferreira, H.; Rodrigues, C.M.; Pinho, C. Impact of Road Geometry on Vehicle Energy Consumption and CO2 Emissions: An Energy-Efficiency Rating Methodology. Energies 2019, 13, 119.
- Sayarshad, H.R.; Mahmoodian, V.; Bojović, N. Dynamic Inventory Routing and Pricing Problem with a Mixed Fleet of Electric and Conventional Urban Freight Vehicles. Sustainability 2021, 13, 6703.
- Alirezaei, M.; Onat, N.; Tatari, O.; Abdel-Aty, M. The Climate Change-Road Safety-Economy Nexus: A System Dynamics Approach to Understanding Complex Interdependencies. Systems 2017, 5, 6.
- Akin, D.; Sisiopiku, V.P.; Skabardonis, A. Impacts of Weather on Traffic Flow Characteristics of Urban Freeways in Istanbul. Procedia—Soc. Behav. Sci. 2011, 16, 89–99.
- Omranian, E.; Sharif, H.; Dessouky, S.; Weissmann, J. Exploring Rainfall Impacts on the Crash Risk on Texas Roadways: A Crash-Based Matched-Pairs Analysis Approach. Accid. Anal. Prev. 2018, 117, 10–20.
- Ali, Q.; Yaseen, M.R.; Khan, M.T.I. The Impact of Temperature, Rainfall, and Health Worker Density Index on Road Traffic Fatalities in Pakistan. Environ. Sci. Pollut. Res. 2020, 27, 19510–19529.
- Afshari, A.; Schuch, F.; Marpu, P. Estimation of the Traffic Related Anthropogenic Heat Release Using BTEX Measurements—A Case Study in Abu Dhabi. Urban Clim. 2018, 24, 311–325.
- Khalifa, A.; Bouzouidja, R.; Marchetti, M.; Buès, M.; Bouilloud, L.; Martin, E.; Chancibaut, K. Individual Contributions of Anthropogenic Physical Processes Associated to Urban Traffic in Improving the Road Surface Temperature Forecast Using TEB Model. Urban Clim. 2018, 24, 778–795.
- Gładyszewska-Fiedoruk, K.; Teleszewski, T.J. Modeling of Humidity in Passenger Cars Equipped with Mechanical Ventilation. Energies 2020, 13, 2987.
- He, Z.; Chen, K.; Chen, X. A Collaborative Method for Route Discovery Using Taxi Drivers’ Experience and Preferences. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2505–2514.
- Kazhaev, A.; Almetova, Z.; Shepelev, V.; Shubenkova, K. Modelling Urban Route Transport Network Parameters with Traffic, Demand and Infrastructural Limitations Being Considered. In Proceedings of the IOP Conference Series Earth and Environmental Science, Moscow, Russia, 18 May 2018.
- Paiva, S.; Pañeda, X.G.; Corcoba, V.; García, R.; Morán, P.; Pozueco, L.; Valdés, M.; del Camino, C. User Preferences in the Design of Advanced Driver Assistance Systems. Sustainability 2021, 13, 3932.
- Jung, J.; Park, S.; Kim, Y.; Park, S. Route Recommendation with Dynamic User Preference on Road Networks. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Kyoto, Japan, 27 March 2019; pp. 1–7.
- Bin, C.; Gu, T.; Sun, Y.; Chang, L.; Sun, L. A Travel Route Recommendation System Based on Smart Phones and IoT Environment. Wirel. Commun. Mob. Comput. 2019, 2019, 1–16.
- Litzinger, P.; Navratil, G.; Sivertun, Å.; Knorr, D. Using Weather Information to Improve Route Planning. In Bridging the Geographic Information Sciences; Springer: Berlin/Heidelberg, Germany, 2012.
More