Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Xuanchen Xiang and Version 2 by Dean Liu.
Reinforcement Learning (RL) is an approach to simulate the human’s natural learning process, whose key is to let the agent learn by interacting with the stochastic environment.
- reinforcement learning
- deep reinforcement learning
1. Introduction
DRL is the combination of Deep Learning and Reinforcement Learning, and it’s more robust than Deep Learning or Reinforcement Learning. However, it inherits some drawbacks that DP and RL have.
Deep Learning extracts features and tasks from data. Generally, the more data provided in training, the better performance DL has. Deep Learning requires lots of data and high-performance GPUs to achieve specific functions. Due to the complex data models, it’s costly to train the models. There’s no standard rule for selecting DL tools or architectures, and tuning the hyperparameters could also be time-consuming. This makes DL unpractical in many domains.
Reinforcement Learning imitates the learning process of humans. It is trained by making and then avoiding mistakes. It can solve some problems that conventional methods can’t solve. In some tasks, it also has the ability to surpass humans. However, RL also has some limitations. First of all, too much reinforcement might cause an overload of states, diminishing the results. Secondly, RL assumes the environment is a Markovian model, in which the probability of the event depends only on the previous state. Thirdly, it has the disadvantages of the curse of dimensionality and the curse of real-world samples. What’s more, we have mentioned the challenges of setting up rewards, balancing exploration and exploitation, etc. [1][28]. Reinforcement Learning is an expensive and complex method, so it’s not preferable for simple tasks.
Employing DRL in the real world is complex. Dulac-Arnold et al. [2][116] addressed nine significant challenges of practical RL in the real world. They presented examples for each challenge and provided some references for deploying RL:
-
Practical systems do not have separate training and evaluation environments. The agent must explore and act reasonably and safely. Thus, a sample-efficient and performant algorithm is crucial. Finn et al. [3][117] proposed Model Agnostic Meta-Learning (MAML) to learn within a distribution with few shot learning. Osband et al. [4][118] used Bootstrapped DQN to learn an ensemble of Q-networks and Thompson Sampling to achieve deep efficient exploration. Using expert demonstrations to bootstrap the agent can also improve efficiency, which has been combined with DQN [5][7] and DDPG [6][23].
-
Real-world environments usually have massive and continuous state and action spaces. Dulac-Arnold et al. [7][119] addressed the challenge for sizeable discrete action spaces. Action-Elimination Deep Q-Network (AE-DQN) [8][120] and Deep Reinforcement Relevance Network (DRRN) [9][121] also deals with the issue.
-
Formulating multi-dimensional reward functions is usually necessary and complicated. Distributional DQN Bellemare et al. [11][123] models the percentile distribution of the rewards. Dulac-Arnold et al. [2][116] presented multi-objective analysis and formulated the global reward function as a linear combination of sub-rewards. Abbeel and Ng [12][124] gave an algorithm is based on inverse RL to try to recover the unknown reward function.
-
Policy explainability is vital for real-world policies as humans operate the systems.
-
Most natural systems have delays in the perception of the states, the actuators, or the return. Hung et al. [15][127] proposed a memory-based algorithm where agents use recall of memories to credit actions from the past. Arjona-Medina et al. [16][128] introduced RUDDER (Return Decomposition for Delayed Rewards) to learn long-term credit assignments for delayed rewards.
2. Applications
2.1. Transportation
An intelligent transportation system (ITS) [17][1] is an application that aims to provide safe, efficient, and innovative services to transport and traffic management and construct more intelligent transport networks. The technologies include car navigation, traffic signal control systems, container management systems, variable message signs, and more. Effective technologies like sensors, Bluetooth, radar, etc., have been applied in ITS and have been widely discussed. In recent years, with DRL steps into vision, the application of DRL in ITS has been researched. Haydari and Yilmaz [18][2] presented a comprehensive survey on DRL for ITS.
2.2. Industrial Applications
2.2.1. Industry 4.0
Industry 4.0, which denotes The Fourth Industrial Revolution, uses modern innovative technology to automate traditional manufacturing and industrial practices. Artificial intelligence enables many applications in Industry 4.0, including predictive maintenance, diagnostics, and management of manufacturing activities and processes [19][4].
Robotics, including manipulation, locomotion, etc., will prevail in all aspects of industrial applications, which was mentioned in [1][28]. For example, Schoettler et al. [20][53] discussed insertion tasks, particularly in industrial applications; Li et al. [21][54] also discussed a skill-acquisition DRL method to make robots acquire assembly skills.
Inspection and Maintenance
Health Indicator Learning (HIL) is an aspect of maintenance that learns the health conditions of equipment over time. Zhang et al. [22][55] proposed a data-driven approach for solving HIL problem based on model-based and model-free RL methods; Holmgren [23][56] presented a general-purpose maintenance planner based on Monte-Carlo tree search (MCTS); Ong et al. [24][57] proposed a model-free DRL algorithm, Prioritized Double Deep Q-Learning with Parameter Noise (PDDQN-PN) for predictive equipment maintenance from an equipment-based sensor network context, which can rapidly learn an optimal maintenance policy; Huang et al. [25][58] proposed a DDQN-based algorithm to learn the predictive maintenance policy.
Management of Engineering Systems
Decision-making for engineering systems can be formulated as an MDP or a POMDP problem [26][59]. Andriotis and Papakonstantinou [27][60] developed Deep Centralized Multi-agent Actor-Critic (DCMAC), which provides solutions for the sequential decision-making in multi-state, multi-component, partially, or fully observable stochastic engineering environments. Most studies on industrial energy management are working on modeling complex industrial processes. Huang et al. [28][61] developed a model-free demand response (DR) scheme for industrial facilities, with an actor-critic-based DRL algorithm to determine the optimal energy management policy.
Process Control
Automatic process control in engineering systems is to achieve a production level of consistency, economy, and safety. In contrast to the traditional design process, RL can learn appropriate closed-loop controllers by interacting with the process and incrementally improving control behavior.
Spielberg et al. [29][62] proposed a DRL method for process control with the controller interacting with a process through control actions. Deep neural networks serve as function approximators to learn the control policies. In 2019, Spielberg et al. [30][63] also developed an adaptive model-free DRL controller for set-point tracking problems in nonlinear processes, evaluated on Single-Input-Single-Output (SISO), Multi-Input-Multi-Output (MIMO), and a nonlinear system. The results show that it can be utilized as an alternative to traditional model-based controllers.
2.2.2. Smart Grid
Smart grids are the development trend of power systems. They’ve been researched for years. The rise of artificial intelligence enables more complex techniques in smart grids and their future development. Zhang et al. [31][64] provided a review on the research and practice on DRL in smart grids, including anomaly detection, prediction, decision-making support for control, etc.
Rocchetta et al. [32][65] developed a DQN-based method for the optimal management of the operation and maintenance of power grids, which can exploit the information gathered from Prognostic Health Management devices, thus selecting optimal Operation and Maintenance (O&M) actions.
State estimation is critical in monitoring and managing the operation of a smart grid. An et al. [33][66] proposed a DQN detection (DQND) scheme to defend against data integrity attacks in AC power systems, which applies the main network and a target network to learn the detection strategy.
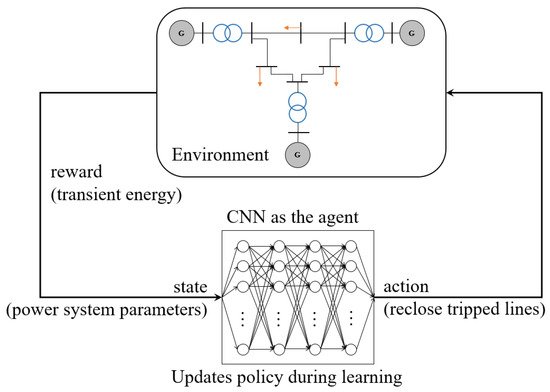
Wei et al. [34][67] proposed a recovery strategy to reclose the tripped transmission lines at the optimal time. The DDPG-based method is applied to adapt to uncertain cyber-attack scenarios and to make decisions in real-time, shown in Figure 2. The action in the cycle is to to reclose the tripped lines at a proper time. The reward is the transient energy including potential energy and kinetic energy.
2.3. Communications and Networking
Modern networks, including the Internet of Things (IoT) and unmanned aerial vehicle (UAV) networks, need to make the decisions to maximize the performance under uncertainty. DRL has been applied to enable network entities to obtain optimal policies and deal with large and complex networks. Jang et al. [36][51] provided a survey on applications of DRL in communications and networking for traffic routing, resource sharing, and data collection. By integrating AI and blockchain, Dai et al. [37][69] proposed a secure and intelligent architecture for next-generation wireless networks to enable flexible and secure resource sharing and developed a caching scheme based on DRL. Also, Yang et al. [38][70] presented a brief review of ML applications in intelligent wireless networks.
2.4. More Topics
There are many applications based on DRL in various domains. In this section, the applications in healthcare, education, finance and aerospace will be briefly discussed.