A term that attempts to describe the procedures that have been brought about by recent technological changes in the field of journalism. Characterized by researchers as “the process of using software or algorithms to automatically generate news stories" (Graefe 2016) and “the combination of algorithms, data, and knowledge from the social sciences to supplement the accountability function of journalism” (Hamilton and Turner 2009).
- Algorithmic Journalism
- Automated content production
- Data mining
- News dissemination
- Content optimization
1. Introduction
2. Definition of Algorithmic Journalism
3. Areas of Application
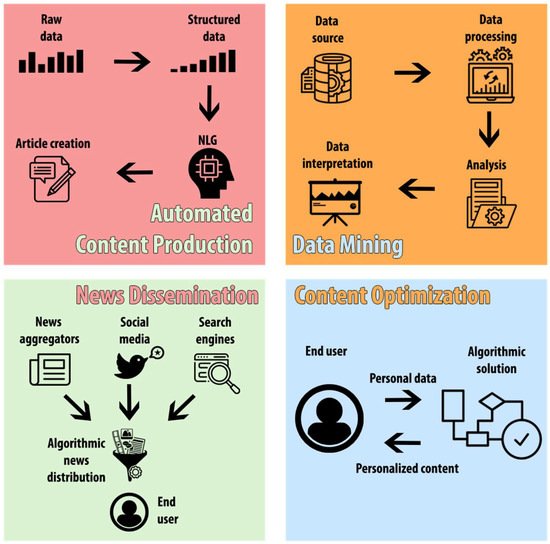
-
Automated content production;
-
Data mining;
-
News dissemination;
-
Content optimization.
3.1 Automated contend production
3.1 Automated contend production
The automation of the news creation process is perhaps the most important - and as a result the most controversial - of all the fields of application for algorithmic technology in journalism (Montal and Reich 2017; Schapals and Pmontaorlezza 2020). In the grand scheme of things, this particular field of application is considered a relatively recent development in the field of journalism (Ali and Hassoun, 2019; Graefe 2016) and it consists mainly of algorithms and automated software that are capable of creating news stories on their own (Diakopoulos 2019).
One of the most well known examples of early applications for automatic content production is that of "Quakebot", a program that was created on behalf of the Los Angeles Times in 2014. Its purpose was to closely monitor data from the US Geological Survey in an attempt to identify instances on seismic activity and proceed to write and publish simple reports on them (Otter 2017). Since then, automatic content production has taken major steps forward, to the point where some of the biggest contributors to the industry such as Forbes and The New York Times often rely on algorithmic production for their content, with the end result being almost impossible to distinguish from human writing (Clerwall 2014).
The basis for the innovations in automated content production is a technology called "Natural Language Generation" or NLG for short. Natural language generation is defined as "the automatic creation of text from digital structured data" (Caswell and Dörr 2018) and it is a technology that first made its appearance in the 1950s within the context of machine translation (Reiter 2010). NLG has seen exponential growth in the past few years and in light of these developments many industries begun to utilize it alongside artificial intelligence to further improve their products and services, with the news media industry being no exception to this rule (Diakopoulos 2019).
The adoption of these technologies by the journalistic profession brought with it a number of advantages, including a significant increase in productivity thanks to the publishing of stories without any human intervention (Ali and Hassoun 2019) as well as the ability to allow journalists to redefine their core skill set (Van Dalen 2012) and provide them with more creative freedom in their work (Milosavljević and Vobič 2019), since computers were able to execute part of their responsibilities by taking over routine tasks (Glahn 1970). Those advantages also seem to coincide with the increasingly high market demands for fast and accurate news stories, making algorithmic news production even more beneficial (Clerwall 2014; Diakopoulos 2019). Thanks to the above, algorithmically generated news started to become a near necessity in the modern news production cycle (Zangana 2017), which, in turn, has led to various forms of controversy from members of the news industry. The main discussion point between journalists and people that are employed in the news industry as a whole is the possibility that the automatization process might render human workers in the field obsolete (Veglis and Maniou 2019). There have been many arguments recorded in related literature when it comes to this topic, and many workers have also voiced their opinion, suggesting that the increasingly dominant role of algorithms in the newsroom will pose a serious threat to the future of human journalists (Kirley 2016). On the opposite end of the spectrum, a number of researchers seem to suggest that those fears are mostly unfounded, pointing out that artificial intelligence and algorithms are only going to enhance journalistic practice in the long run instead of replacing it (Hansen et al. 2017). Drawing a line between what might be a useful innovation and what might pose a threat to the industry due to the potential loss of jobs is certainly no easy task, and that is perhaps the reason behind this apparent split in the existing literature, with many researchers pointing out the benefits of automation, and others focusing on the potential danger it encompasses for the employees of the media industry. It is certain that automated content production plays a major role in the news production process nowadays, and it is commonly agreed by researchers that automation will hold a critical role in the future of news agencies (Liu et al. 2017). As competition within the industry continues to rise, the only way to keep up with the ever-increasing demand for more news stories seems to be the utilization of automated content production technologies. The question remains, however, as to how the industry is going to adapt to these new conditions of automation, as the displacement of employees and an overall reduction of the workforce is indeed inevitable based on current projections (Carlson 2015), as machines become more and more capable in substituting human workers in specific tasks. There are a number of views shared by researchers and employees in the media industry that tend to challenge the arguments presented above, regarding the ability of algorithms to “free” journalists and allow them more time to pursue more investigative tasks (Schapals and Porlezza 2020). These concerns mostly stem from the fact that computational technology is shaping journalism into a more streamline and sterile process, one that does not necessarily require human input in order to function, and they bring up some very valid points regarding the skill set that a modern journalist is expected to have in order to compete in this environment. Taking that into consideration, the fact that automation will make a number of jobs obsolete given enough time seems to be an inevitable outcome. While the way the industry intents to deal with this problem still remains to be seen, perhaps one potential solution to it lies in the adjustment of expectations and the redefining of the term “journalistic labor”. As Carlson (2015) puts it, “Automated journalism requires the transformation of journalistic labor to include such new positions as “meta-writer” or “metajournalist” to facilitate automated stories”. This point of view suggests that in order to achieve a fully symbiotic relationship between human workers and machines, a middle ground has to be reached, specifically one where media industry workers need to reevaluate their priorities and develop a skill set that supplements algorithmic news production, instead of attempting to compete head-on with it. In accordance to what Van Dalen (2012) has stated, this can be seen as an opportunity for workers to redefine their core skills and work in tandem with algorithms, as ultimately, these programs are fundamentally different from humans, since they lack traits such as creativity, flexibility and analytical thinking, which would mean that in order to achieve the best and overall most efficient result, both parties would need to work together and cooperate. The fact that these programs lack traits such as creativity, flexibility and analytical thinking is an important factor that separates them from humans (Van Dalen 2012); as such, these technologies do not present an immediate threat to the practitioners of the journalistic profession (Ali and Hassoun 2019). Despite how important automated content creation has been for the industry, it is apparent that algorithmic journalism is not limited just to the creation of automated news stories (Jamil 2020). There are other important fields of application for these technological innovations that that have also impacted journalism in a major way, which will be examined below.3.2 Data Mining
3.2 Data Mining
One of the most defining characteristics of the information age that we are currently undergoing is the so-called “data explosion”, which refers to the constant increase of widely available data on the internet, with some sources approximating that the digital universe roughly doubles in size every 18 months (Zhu et al. 2009). Data, however, should not be mistaken for information (Aljazairi 2016). Within this ever-increasing landscape of available resources, journalists are struggling more than ever to separate clutter from actually useful information (Chen and Liu 2004), and this is where the need for procedures such as data mining starts to become apparent. According to Bramer (2007), data mining is a central part of a broader process called “knowledge discovery” and it refers to the extraction of useful information from a larger subset of data (Figure 2). There are many applications for this type of technology in journalism, with the most obvious one being the acquisition of specific information from large databases. The case of “Quakebot” that was mentioned above also constitutes a very good example of data mining, despite the fact that it is mostly known to be an instance of automated content production, since the program was able to single out and use information form a much larger dataset (which was all of the data provided by the US geological survey). Chatbots and other similar automated agents have been utilized extensively in these procedures (Veglis and Kotenidis 2020).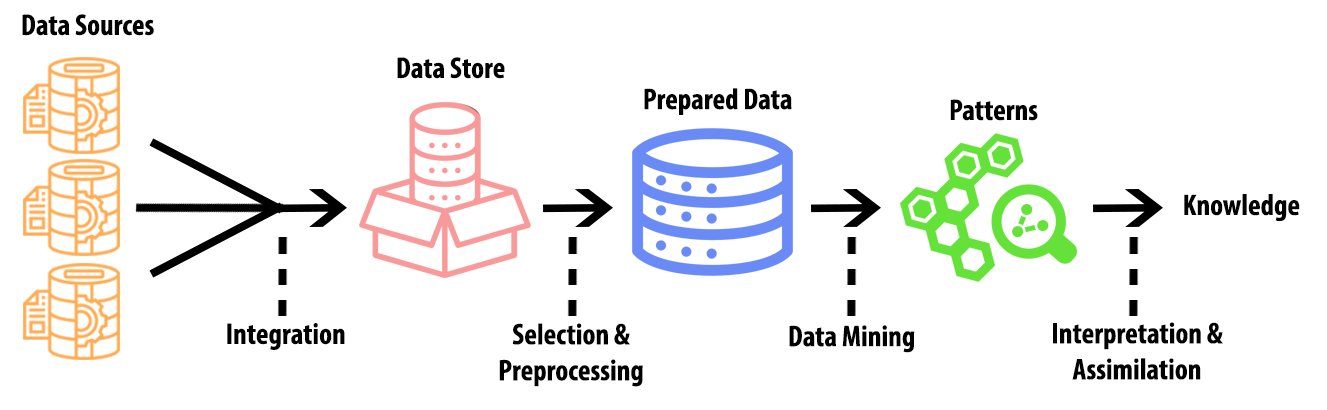
3.3 News dissemination
In this day and age, the internet accounts for a very large portion of daily media consumption (Gaskins and Jerit 2012) and as such the way the dissemination of news is handled proves to be exceedingly important (Orellana-Rodriguez and Keane 2018). There are three main platforms through which the majority of internet users receivetheir news content from, namely: news aggregators, search engines and social media sites (Foster 2012). These digital intermediaries all have something in common: they largely rely on algorithms and automated systems in order to appropriately distribute content to their users (Cádima 2018). As media companies started to shift their focus on online news and the implementation of more interactive features (Deuze 2005), these automatic news dissemination technologies proved to be a major driving force for journalism since news organizations started to utilize them more and more (Carlson 2018). The advantages that emerged in the field of journalism through the use of these innovations became apparent quite quickly. Specifically, news outlets were able to utilize algorithms in order to automatically and systematically disseminate news on social media and other similar platforms, by using software agents called “news bots”. These programs are capable of distributing news and information to a large audience, as well as interacting with users in various ways and ensuring high visibility for the content in question, thereby supplementing the news dissemination process and helping media agencies to reach as wide an audience as possible (Lokot and Diakopoulos 2016). Controversy has also been observed in this field of application, although perhaps not to the extent of automated content production. Specifically, concerns have arisen from researchers over the years regarding the role of algorithmic news distribution technology as a “gatekeeper” of news (Nechushtai and Lewis 2019; Cádima 2018), the accountability and the impartiality of these programs (Diakopoulos 2015) as well as ethical considerations regarding algorithmic transparency (Diakopoulos and Koliska 2017) and the role these agents play in the spread of fake news and misinformation (Shao et al. 2017; Shin and Valente 2020; Fernandez and Alani 2018).All of the above constitutes well-funded criticism related news dissemination that has yet to be addressed in a meaningful way. When it comes to news gatekeeping in particular, Cádima (2018) brings up an important point regarding the intermediation issue. As digital intermediaries are estimated to be redirecting more than 70% of internet news traffic, it is difficult to ensure that news circulation will remain democratic going forward. This poses a lot of questions about the future of journalism that are related both to quality deterioration, as well as censorship issues that could potentially affect a very large subset of the population. Ensuring that communication channels remain open and not allowing any third parties to consistently prioritize certain voices over others will prove vital for the future of the journalistic profession. Ultimately, however, an agreed-upon standard for humans as news gatekeepers does not exist, and this fact makes it all the more challenging to assess the performance of algorithms in this regard (Nechushtai and Lewis 2019).
3.4 Content Optimization
Personalized content for individual recipients is not a new idea in the media industry, as some researchers have suggested functioning models for it even before the turn of the 21st century (Bharat et al. 1998; Billsus and Pazzani 1999). Despite this, however, it was not until the past few years that developments in algorithmic technology allowed news providers to target specific audiences on a large scale and deliver customized news experiences for them, thanks to the internet’s ability to provide almost real-time recommendations and information from all over the world (Li et al. 2011). These personalized news content services have proved to be very useful because they can save time for the end used by drastically reducing the amount of irrelevant information and provide content only for subjects that are of interest (Jokela et al. 2001). Content optimization for users usually works in a similar manner to search engines, which utilize automated ranking algorithms in order to return the most relevant results for a user’s search. Using a similar structure, personalized news content and online ads are served to specific users with the use of automated algorithms (Agarwal et al. 2008). Content optimization with the help of algorithmic technology has also been observed in other parts of the news production process, as some organizations utilize algorithms for tasks such as A/B testing for article headlines in order to better gauge their effectiveness (Lokot and Diakopoulos 2016). The prime use for this technology, however, has been the delivery of personalized news content through customized newsfeeds or automated agents such as chatbots. These automated bots in particular have proven to be very effective in engaging with audiences by providing more interactive and personalized instances of news and articles as opposed to the traditional methods of content consumption (Jones and Jones 2019). Even though this technology provides a user-friendly way of consuming more relevant content, there have been a number of concerns regarding its use that are worth addressing. First off, some privacy concerns have been brought to light by users over the years in regard to content optimization. Specifically, those concerns are related to the way these algorithmic solutions function, since most content optimization systems from media organizations and other companies alike rely on the collection of personal data in order to fulfill their duties (Das et al. 2007). Furthermore, the personalization employed by these algorithms often remains unnoticed by the users (Powers 2017), which further feeds into this issue. That is the reason many researchers, such as Diakopoulos and Koliska (2017) and Graefe (2016), have started to advocate for algorithmic transparency over the past years, since many users do not feel comfortable with the idea of “being watched” by automated programs without them being notified while they are browsing the internet, even if that action ultimately aims to benefit them with more streamlined recommendations. The privacy concerns mentioned above are likely to grow in scale with each passing year as technology gradually envelops more and more aspects of daily life, and as such, it is important for algorithmic transparency to be established as one of the pillars upon which future innovations can be developed, in order to avoid further frictions. Despite their importance, however, these concerns are not the only ones that were brought to light when it comes to personalization algorithms. Another relevant issue in this field of application has to do with the content that is being distributed. Specifically, researchers have noted that the constant stream of personalized content has the potential to negatively affect the news ecosystem, since it has been known to reduce news diversity for recipients and consequently lead to partial information blindness (Haim et al. 2018). This phenomenon became widely known with the term “filter bubbles”, with similar theoretical constructs such as “news echo chambers” describing constant user exposure to like-minded opinions (Garrett 2009). These online environments that stand devoid of varied viewpoints constitute a serious criticism regarding news personalization, since they tend to reinforce the user’s opinion on specific matters, and usually offer no counterpoints, or even alternative viewpoints to the one they have chosen to adopt. Even though this phenomenon is not exclusive to these technologies, or even to the internet as it can be observed in other media as well, the nature of online personalized content delivery seems to be enhancing this particular problem. To put it in simpler terms, while algorithmic personalization caters to the needs of the user and creates a more enjoyable and customizable experience, it also simultaneously encompasses them in their own “bubble” and prevents them from challenging their beliefs. This criticism puts the model of personalized news delivery into question, as it can be the epicenter of some serious ramifications in the future that can range from the spread of misinformation to the potential fragmentation of the public opinion (Graefe 2016).References
- Pavlik, John. 2000. The impact of technology on journalism. Journalism Studies 1: 229–37.
- Deuze, Mark, and Tamara Witschge. 2018. Beyond journalism: Theorizing the transformation of journalism. Journalism 19: 165–81.
- Dörr, Konstantin. Nicholas. 2015. Mapping the field of algorithmic journalism. Digital Journalism.
- Spyridou, Lia-Paschalia, Maria Matsiola, Andreas Veglis, George Kalliris, and Charalambos Dimoulas. 2013. Journalism in a state of flux: Journalists as agents of technology innovation and emerging news practices. International Communication Gazette 75: 76–98.
- Frey, Carl Benedikt, and Michael A. Osborne. 2017. The future of employment: How susceptible are jobs to computerisation? Technological Forecasting and Social Change 114: 254–80.
- Graefe, Andreas. 2016. Guide to automated journalism. Tow Center for Digital Journalism.
- Van Dalen, Arjen. 2012. The algorithms behind the headlines: How machine-written news redefines the core skills of human journalists. Journalism Practice 6: 648–58.
- Anderson, C. W. 2012. Towards a sociology of computational and algorithmic journalism. New Media & Society 15: 1005–21.
- Hamilton, James T., and Fred Turner. 2009. Accountability through Algorithm. Center for Advanced Study in the Behavioral Sciences Summer Workshop. Available online: (accessed on 5 February 2021).
- Garrison, Bruce. 1998. Computer-Assisted Reporting, 2nd ed. Mahwah: Lawrence Erlbaum Associates.
- Diakopoulos, Nicholas. 2011. A Functional Roadmap for Innovation in Computational Journalism. Nick Diakopoulos [Blog Post]. Available online: (accessed on 6 February 2021).
- Lindén, Carl-Gustav, Hanna Tuulonen, Asta Bäck, Nicholas Diakopoulos, Mark Granroth-Wilding, Lauri Haapanen, Leo Leppänen, Magnus Melin, Tom Moring, Myriam Munezero, and et al. 2019. News Automation: The Rewards, Risks and Realities of Machine Journalism. WAN-IFRA Report. Available online: (accessed on 10 February 2021).
- Lindén, Carl-Gustav. 2017. Algorithms for journalism: The future of news work. The Journal of Media Innovations.
- Ali, Waleed, and Mohamed Hassoun. 2019. Artificial intelligence and automated journalism: Contemporary challenges and new opportunities. International Journal of Media, Journalism and Mass Communication 5: 40–49.
- Milosavljević, Marko, and Igor Vobič. 2019. ‘Our task is to demystify fears’: Analysing newsroom management of automation in journalism. Journalism.
- Glahn, Harry R. 1970. Computer-produced worded forecasts. Bulletin of the American Meteorological Society 51: 1126–32.
- Clerwall, Christer. 2014. Enter the robot journalist: Users’ perceptions of automated content. Journalism Practice 8: 519–31.
- Diakopoulos, Nicholas. 2019. Automating the News: How Algorithms Are Rewriting the Media. Cambridge: Harvard University Press.
- Zangana, Abdulsamad. 2017. The Impact of New Technology on the News Production Process in the Newsroom. Ph.D. thesis, University of Liverpool, Liverpool, UK. Available online: (accessed on 14 February 2021).
- Veglis, Andreas, and Theodora A. Maniou. 2019. Chatbots on the rise: A new narrative in journalism. Studies in Media and Communication 7: 1–6.
- Kirley, Elizabeth A. 2016. The robot as cub reporter: Law’s emerging role in cognitive journalism. European journal of Law and Technology 7: 17–18. Available online: (accessed on 11 February 2021).
- Hansen, Mark, Meritxell Roca-Sales, Jon M. Keegan, and George King. 2017. Artificial intelligence: Practice and implications for journalism. In Tow Center for Digital Journalism. New York: Columbia University.
- Liu, Xiaomo, Armineh Nourbakhsh, Quanzhi Li, Sameena Shah, Robert Martin, and John Duprey. 2017. Reuters tracer: Toward automated news production using large scale social media data. Paper presented at the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, December 11–14; pp. 1483–93.
- Carlson, Matt. 2015. The robotic reporter: Automated journalism and the redefinition of labor, compositional forms, and journalistic authority. Digital Journalism 3: 416–31.
- Schapals, Aljosha Karim, and Colin Porlezza. 2020. Assistance or resistance? Evaluating the intersection of automated journalism and journalistic role conceptions. Media and Communication 8: 16–26.
- Jamil, Sadia. 2020. Artificial intelligence and journalistic practice: The crossroads of obstacles and opportunities for the Pakistani journalists. Journalism Practice, 1–23.
- Zhu, Yangyong, Ning Zhong, and Yun Xiong. 2009. Data explosion, data nature and dataology. In International Conference on Brain Informatics. Berlin/Heidelberg: Springer, pp. 147–58.
- Aljazairi, Sena. 2016. Robot Journalism: Threat or an Opportunity. Master’s thesis, School of Humanities, Education and Social Sciences, Örebro University, Örebro, Sweden. Available online: (accessed on 18 February 2021).
- Chen, Sherry. Y., and Xiaohui Liu. 2004. The contribution of data mining to information science. Journal of Information Science 30: 550–58.
- Bramer, Max. 2007. Principles of Data Mining, 1st ed. London: Springer, vol. 180, p. 2.
- Veglis, Andreas, and Efthimis Kotenidis. 2020. Employing chatbots for data collection in participatory journalism and crisis situations. Journal of Applied Journalism & Media Studies.
- Kitchin, Rob. 2014. Big Data, new epistemologies and paradigm shifts. Big Data & Society 1: 1–12.
- Latar, Noam Lemelshtrich. 2015. The robot journalist in the age of social physics: The end of human journalism? In The New World of Transitioned Media. Cham: Springer, pp. 65–80.
- Kennedy, Helen, and Giles Moss. 2015. Known or knowing publics? Social media data mining and the question of public agency. Big Data & Society 2.
- Hammond, Philip. 2017. From computer-assisted to data-driven: Journalism and Big Data. Journalism 18: 408–24.
- Veglis, Andreas, and Theodora A. Maniou. 2018. The mediated data model of communication flow: Big data and data journalism. KOME: An International Journal of Pure Communication Inquiry 6: 32–43.
- Gaskins, Benjamin, and Jennifer Jerit. 2012. Internet news: Is it a replacement for traditional media outlets? The International Journal of Press/Politics 17: 190–213.
- Orellana-Rodriguez, Claudia, and Mark T. Keane. 2018. Attention to news and its dissemination on Twitter: A survey. Computer Science Review 29: 74–94.
- Foster, Robin. 2012. News Plurality in a Digital World. Oxford: New Reuters Institute for the Study of Journalism.
- Cádima, Francisco Rui. 2018. Journalism at the crossroads of the algorithmic turn. Media & Jornalismo 18: 171–85.
- Deuze, Mark. 2005. What is journalism? Professional identity and ideology of journalists reconsidered. Journalism 6: 442–64.
- Carlson, Matt. 2018. Automating judgment? Algorithmic judgment, news knowledge, and journalistic professionalism. New Media & Society 20: 1755–72.
- Lokot, Tetyana, and Nicholas Diakopoulos. 2016. News Bots: Automating news and information dissemination on Twitter. Digital Journalism 4: 682–99.
- Nechushtai, Efrat, and Seth C. Lewis. 2019. What kind of news gatekeepers do we want machines to be? Filter bubbles, fragmentation, and the normative dimensions of algorithmic recommendations. Computers in Human Behavior 90: 298–307.
- Diakopoulos, Nicholas. 2015. Algorithmic accountability: Journalistic investigation of computational power structures. Digital Journalism 3: 398–415.
- Diakopoulos, Nicholas, and Michael Koliska. 2017. Algorithmic transparency in the news media. Digital Journalism 5: 809–28.
- Shao, Chengcheng, Giovanni Luca Ciampaglia, Onur Varol, Kai-Cheng Yang, Alessandro Flammini, and Filippo Menczer. 2017. The spread of fake news by social bots. arXiv arXiv:1707.07592.
- Shin, Jieun, and Thomas Valente. 2020. Algorithms and health misinformation: A case study of vaccine books on amazon. Journal of Health Communication 25: 394–401.
- Fernandez, M., and H. Alani. 2018. Online misinformation: Challenges and future directions. Paper presented at the Companion Web Conference 2018, Lyon, France, April 23–27; pp. 595–602.
- Bharat, Krishna, Tomonari Kamba, and Michael Albers. 1998. Personalized, interactive news on the web. Multimedia Systems 6: 349–58.
- Billsus, Daniel, and Michael J. Pazzani. 1999. A hybrid user model for news story classification. In Um99 User Modeling. Vienna: Springer, pp. 99–108.
- Li, Lei, Dingding Wang, Tao Li, Daniel Knox, and Balaji Padmanabhan. 2011. Scene: A scalable two-stage personalized news recommendation system. Paper presented at the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, July 25–29; pp. 125–34.
- Jokela, Sami, Marko Turpeinen, Teppo Kurki, Eerika Savia, and Reijo Sulonen. 2001. The role of structured content in a personalized news service. Paper presented at the 34th Annual Hawaii International Conference on System Sciences, Maui, HI, USA, January 6; pp. 1–10.
- Agarwal, Deepak, Bee-Chung Chen, Pradheep Elango, Nitin Motgi, Seung-Taek Park, Raghu Ramakrishnan, Scott Roy, and Joe Zachariah. 2008. Online models for content optimization. In Advances in Neural Information Processing Systems. Vancouver: NeurIPS, pp. 17–24.
- Jones, Bronwyn, and Rhianne Jones. 2019. Public service chatbots: Automating conversation with BBC News. Digital Journalism 7: 1032–53.
- Das, Abhinandan S., Mayur Datar, Ashutosh Garg, and Shyam Rajaram. 2007. Google news personalization: Scalable online collaborative filtering. Paper presented at the 16th International Conference on World Wide Web, Banff, AB, Canada, May 8–12; pp. 271–80.
- Powers, Elia. 2017. My news feed is filtered? Awareness of news personalization among college students. Digital Journalism 5: 1315–35.
- Haim, Mario, Andreas Graefe, and Hans-Bernd Brosius. 2018. Burst of the filter bubble? Effects of personalization on the diversity of Google News. Digital Journalism 6: 330–43.
- Garrett, R. Kelly. 2009. Echo chambers online?: Politically motivated selective exposure among Internet news users. Journal of Computer-Mediated Communication 14: 265–85.