Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Hamid Behnam and Version 2 by Sirius Huang.
Ultrasound (US) has become a widely used imaging modality in clinical practice, characterized by its rapidly evolving technology, advantages, and unique challenges, such as a low imaging quality and high variability. There is a need to develop advanced automatic US image analysis methods to enhance its diagnostic accuracy and objectivity. Vision transformers, a recent innovation in machine learning, have demonstrated significant potential in various research fields, including general image analysis and computer vision, due to their capacity to process large datasets and learn complex patterns. Their suitability for automatic US image analysis tasks, such as classification, detection, and segmentation, has been recognized.
- transformer
- ultrasound (US)
- deep learning
- convolutional neural network (CNN)
- vision transformer (ViT)
- swin transformer
1. Introduction
Ultrasound (US) is a versatile imaging technique that has become a fundamental resource in medical diagnosis and screening. Its wide acceptance and use by both physicians and radiologists underscore its importance and reliability. US is widely utilized due to its safety, affordability, non-invasive nature, real-time visualization capabilities, and the comfort it provides to those performing the procedure. It stands out among other imaging techniques like X-ray, MRI, and CT scans because of its several significant benefits, including its absence of ionizing radiation, portability, ease of access, and cost-efficiency [1]. US is applied in various medical fields, such as breast US, echocardiography, transrectal US, intravascular US (IVUS), prenatal diagnostic US, and abdominal US. It is particularly prevalent in obstetrics [2]. However, despite its numerous benefits, US also presents certain challenges. These include a lower image quality due to noise and artifacts, a high dependence on the operator or diagnostician’s experience, and significant variations in performance across different institutions and manufacturers’ US systems [3].
Artificial intelligence (AI) methods, particularly deep learning models, have brought about ultrasound imaging by automating image processing and enabling the automated diagnosis of disease and detection of abnormalities. Convolutional neural networks (CNNs) have played a vital role in this transformation, demonstrating improvements in various medical imaging modalities [4][5][6][7][8][9][4,5,6,7,8,9]. However, the limitations of CNNs in capturing long-range dependencies and contextual information led to the development of vision transformers (ViTs) [10] in image processing. The self-attention mechanism, a key part of the transformer, possesses the capability to establish relationships between sequence elements, thus facilitating the learning of long-range interactions.
Significant strides have been made in the vision community to integrate attention mechanisms into architectures inspired by CNNs. Recent research has shown that these transformer modules can potentially substitute standard convolutions in deep neural networks by working on a sequence of image patches culminating in the creation of ViTs.
In recent years, the integration of vision transformers into medical US analysis has encompassed a diverse range of methodological tasks. These tasks include traditional diagnostic functions like segmentation, classification, biometric measurements, detection, quality assessment, and registration, as well as innovative applications like image-guided interventions and therapy.
Notably, segmentation, detection, and classification stand out as the fundamental tasks, with widespread utilization across various anatomical structures in medical US analysis. The anatomical structures covered here include the heart [11], prostate [12], liver [13], breast [14], brain [15], lymph node [16], lung [17], pancreatic [18], carotid [19], thyroid [11], intravascular [20], fetus [21], urinary bladder [22], gallbladder, and other structures [23].
2. Fundamentals of Transformers
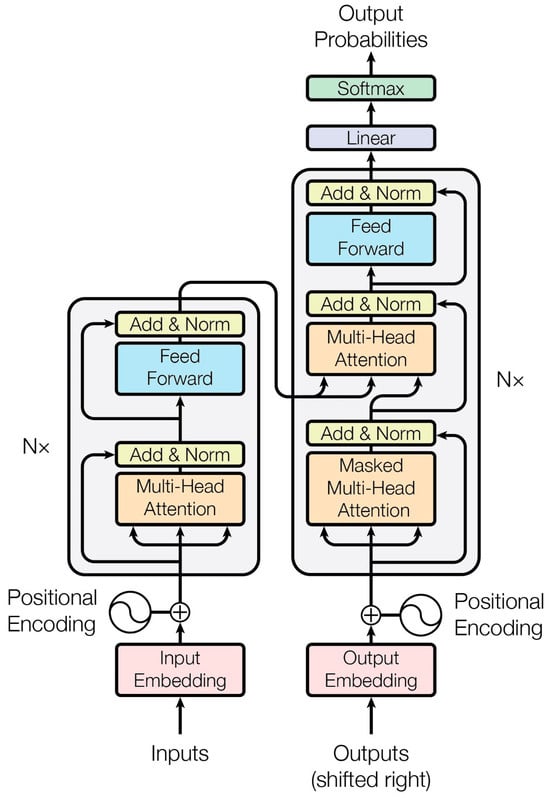
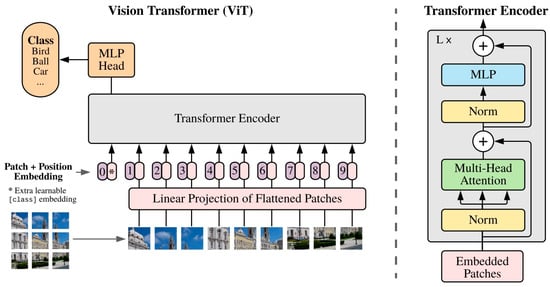
Transformers have advanced the field of Natural Language Processing (NLP) by providing a fundamental framework for processing and understanding language. Originally introduced by Vaswani et al. in 2017 [24][25], transformers have since become a cornerstone in NLP, particularly with the development of models such as BERT, GPT-3, and T5. Fundamentally, transformers represent a kind of neural network architecture that does not rely on convolutions. They excel at identifying long-range dependencies and relationships in sequential data, which makes them especially effective for tasks related to language. The groundbreaking aspect of transformers is their attention mechanism, which empowers them to assign weights to the significance of various words in a sentence. This capability allows them to process and comprehend context more efficiently than earlier NLP models. In addition to their significant impact on NLP, transformers have also shown promise in the field of computer vision. Vision transformers (ViTs) have emerged as a novel approach to image recognition tasks, challenging the traditional CNN architectures. By applying the self-attention mechanism to image patches, vision transformers can effectively capture global dependencies in images, enabling them to understand the context and relationships between different parts of an image. This has led to impressive results in tasks such as image classification, object detection, and image segmentation. The introduction of vision transformers has also opened up opportunities for cross-modal learning, where transformers can be applied to tasks that involve both text and images, such as image captioning and visual question answering. This demonstrates the versatility of transformers in handling multimodal data and their potential to drive innovation at the intersection of NLP and computer vision. Overall, the application of transformers in computer vision showcases their adaptability and potential to revolutionize not only NLP, but also other domains of artificial intelligence, paving the way for new advancements in multimodal learning and our understanding of complex data.2.1. Self-Attention
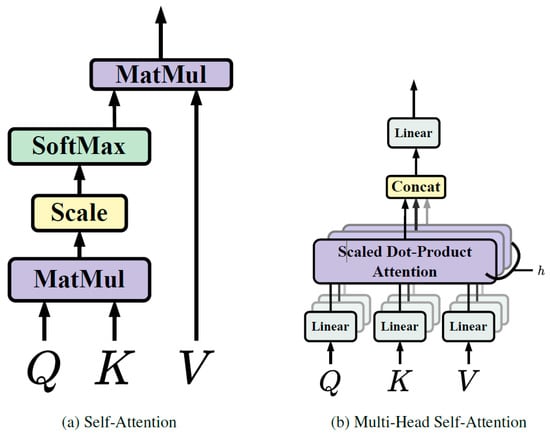
In transformers, self-attention is an element of the attention mechanism that allows the model to focus on various segments of the input sequence and identify dependencies among them [24][25]. This process involves converting the input sequence into three vectors: queries, keys, and values. The queries are employed to extract pertinent data from the keys, while the values are utilized to generate the output. The attention weights are determined based on the correlation between the queries and keys. The final output is produced by summing the weighted values. This mechanism is especially potent in detecting long-term dependencies within the input sequence, thereby making it a valuable instrument for natural language processing and similar sequence-based tasks. To elaborate, before the input sentence is fed into the self-attention block, it is first converted into an embedding vector. This process is known as “word embedding” or “sentence embedding”, and it forms the basis of many Natural Language Processing (NLP) tasks. After the embedding vector, the positional information of each word is also included because the position can alter the meaning of the word or sentence. This is performed to allow the model to track the position of each vector or word. Once the vectors are prepared, the next step is to calculate the similarity between any two vectors. The dot product is commonly used for this purpose due to its computational efficiency and space optimization. The dot product provides scalar results, which are suitable for our needs. After obtaining the similarity scores, the next step involves normalizing and applying the softmax function to obtain the attention weights. These weights are then multiplied with the original input vector to adjust the values according to the weights received from the softmax function.2.2. Multi-Head Self-Attention
Multi-head self-attention is a strategy used in transformers to boost the model’s capacity to grasp a variety of relationships and dependencies within the input sequence [24][25]. This methodology involves executing self-attention multiple times concurrently, each time with different sets of learned queries, keys, and values. Each set originates from a linear projection of the initial input, offering multiple unique viewpoints on the input sequence (Figure 13).