Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Weixin Zeng and Version 1 by Weixin Zeng.
知识图谱的归纳关系预测作为一个重要的研究课题,旨在预测未知实体与许多实际应用之间的缺失关系。现有的解决该问题的方法大多使用封闭子图来提取目标节点的特征进行预测Inductive relationship prediction for knowledge graphs, as an important research topic, aims to predict missing relationships between unknown entities and many practical applications. Most of the existing approaches to this problem use closed subgraphs to extract features of target nodes for prediction;然而,有一种趋势是忽略封闭子图之外的相邻关系,从而导致预测不准确。此外,他们还忽略了丰富的常识性信息,这些信息可以帮助过滤掉不太令人信服的结果。 however, there is a tendency to ignore neighboring relationships outside the closed subgraphs, which leads to inaccurate predictions. In addition, they ignore the rich commonsense information that can help filter out less compelling results.
- inductive relation prediction
- commonsense
- dual attention
- contrastive learning
1. Introduction
Knowledge graphs (KGs) are composed of organized knowledge in the form of factual triples (entity, relation, entity), and they form a collection of interrelated knowledge, thereby facilitating downstream tasks such as question answering [1], relation extraction [2], and recommendation systems [3]. However, even state-of-the-art KGs suffer from an issue of incompleteness [4,5], such as FreeBase [6] and WikiData [7]. To solve this issue, many studies have been proposed mining missing triples in KGs, in which the embedding-based methods become a dominant paradigm, such as TransE [8], ComplEx [9], RGCN [10], and CompGCN [11]. In particular, certain scholars have explored knowledge graph completion under low-data regime conditions [12]. In actuality, the aforementioned methods are often only suitable for transductive scenarios, which assumes that the set of entities in KGs is fixed.
However, KGs undergo continuous updates, whereby new entities and triples are incorporated to store additional factual knowledge, such as new users and products on e-commerce platforms. Predicting the relation links between new entities requires inductive reasoning capabilities, which implies that generality should be derived from existing datasets and extended to a broader spectrum of fields, as shown in Figure 1. The crux of the inductive relation prediction [13] resides in utilizing information that is not specifically tied to a particular entity. A representative strategy in inductive relation prediction techniques is rule mining [14], which extracts first-order logic rules from a given KG and employs weighted combinations of these rules for inference. Each rule can be regarded as a relational path, comprising a set of relations from the head entity to the tail entity, which signifies the presence of a target relationship between two entities. For example, consider the straightforward rule (X, part_of, Y) ∧ (Y, located_in, Z) → (X, lives_in, Z), which was derived from the KG depicted in Figure 1a. These relational paths exist in symbolic forms and are independent of particular entities, thus rendering them inductive and highly interpretable.
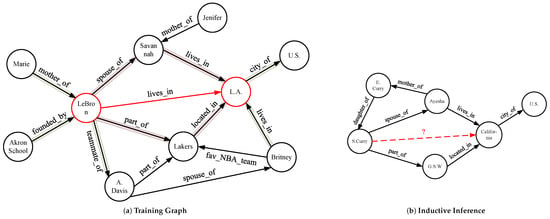
Figure 1. An explanatory case in inductive relation prediction, which learned from a (a) training graph, and generalizes to be (b) without any shared entities for inference. A red dashed line denotes the relation to be predicted.
Motivated by graph neural networks (GNNs) that have the ability of aggregating local information, researchers have recently proposed GNN-based inductive models. GraIL [15] models the subgraphs of target triples to capture topologies. Based on GraIL, some works [16,17,18] have further utilized enclosing subgraphs for inductive prediction. Recent research has also considered few-shot settings for handling unseen entities [19,20]. SNRI [21] extracts the neighbor features of target node and path features, solves the problem of sparse subgraphs, and introduces mutual information (MI) maximization to model from a global perspective, which improves the prediction effect of inductive relationships.
2. Relation Prediction Methods
为了提高To improve the integrity of KG的完整性,最先进的方法使用KG内部结构s, state-of-the-art approaches use either internal KG structures [8,15]或外部 or external KG信息 information [22,23]。. 转导方法。转导方法用于学习每个节点的实体特定嵌入,它们有一个共同点:对原始Transduction methods. Transduction methods are used to learn entity-specific embeddings for each node, and they have one thing in common: reasoning about the original KG. However, 进行推理。然而,很难预测看不见的节点之间缺失的环节。例如,it is difficult to predict missing links between unseen nodes. For example, TransE [8] 基于翻译,而is based on translation, while RGCN [10] 和and CompGCN [11] are based 基于 GNN。它们之间的主要区别在于评分函数和是否利用了KG中的结构信息。Wang等提出,利用全局邻域聚合器获取实体的全局结构信息,以解决某些快照下局部结构信息稀疏的问题on GNN. the main difference between them is the scoring function and whether or not the structural information in the KG is utilized. wang et al. proposed to obtain global structural information about an entity by using a global neighborhood aggregator to solve the problem of sparse local structural information under certain snapshots [24]。. Meng等提出了一种基于稀疏时间知识图谱的多跳路径推理模型 et al. proposed a multi-hop path inference model based on sparse temporal knowledge graph [25]。最近,. Recently, Wang等人提出了多层次交互的知识图谱补全,其中实体和关系在细粒度和粗粒度上同时交互 et al. proposed knowledge graph complementation with multi-level interactions, in which entities and relations interact at both fine- and coarse-grained levels [26]。. 归纳法。归纳法可用于学习如何在看不见的节点上进行推理。方法主要分为两类:基于规则的方法和基于图形的方法。基于规则的方法旨在学习与实体无关的逻辑推理规则。例如,Induction methods. Inductive methods can be used to learn how to reason over unseen nodes. The methods fall into two main categories: rule-based methods and graph-based methods. Rule-based methods aim to learn logical reasoning rules that are entity-independent. For example, NeuralLP [14] 和and DRUM [27] 将神经网络与符号规则集成在一起,以端到端的微观方式学习逻辑规则和规则置信度。integrate neural networks with symbolic rules to learn logical rules and rule confidence in an end-to-end microscopic manner. 在基于图的方法方面,近年来,研究人员从图神经网络的局部信息聚合能力中汲取灵感,并将图神经网络(In terms of graph-based approaches, in recent years, researchers have drawn inspiration from the local information aggregation capability of graph neural networks and incorporated graph neural networks (GNN)纳入其模型中。GraILs) into their models. GraIL [15]通过提取目标三元组的封闭子图来获取目标节点的拓扑结构,从而表现出归纳预测能力。 demonstrated inductive prediction by extracting closed subgraphs of the target triad to capture the topology of the target nodes. TACT [16]在此模型的基础上,引入了子图中关系的相关性,并构建了关系相关网络( built on this model by introducing subgraphs in the correlation of relations and constructed a relational correlation network (RCN)来增强子图的编码。) to enhance the coding of subgraphs. CoMPLIE [17]提出了一种节点 proposed a node-边缘通信消息传播网络,以增强节点与边缘之间的交互,并自然地处理非对称或反对称关系,以增强关系信息的充分流动。edge communication message propagation network to enhance the interaction between nodes and edges and naturally handle asymmetric or antisymmetric relations to enhance the adequate flow of relational information. ConGLR [13] 制定了一个上下文图来表示子图中的关系路径,其中应用两个formulated a contextual graph to represent subgraphs of relational paths, where two GCN 来处理封闭的子图和上下文,其中不同的层以交互方式利用对应的输出来更好地表示特征。s are applied to handle closed subgraphs and contexts, where different layers utilize the corresponding outputs in an interactive manner to better represent features. RE-PORT [28] 聚合关系路径和上下文,通过统一的分层转换框架捕获实体的联系和内在性质。然而,由于aggregates relational paths and contexts to capture the linkages and intrinsic properties of entities through a unified layered transformation framework. However, the RE-PORT的实验指标与其他先进模型不同,因此在本文的实验部分没有选择RE-PORT模型作为对比模型。RMPI model is not selected as a comparison model in the experimental part of this paper since its experimental metrics are different from other state-of-the-art models. RMPI [29]使用一种新颖的关系消息传递网络进行完全归纳知识图谱的完成。 uses a novel relational message-passing network for complete inductive knowledge graph completion. SNRI [21]提取节点的邻居关系特征和路径嵌入,充分利用实体的完整邻居关系信息,以获得更好的归纳效果。然而,所有这些方法都只是增加了额外的简单处理负荷,并没有充分利用 extracts nodes' neighbor-relationship features and path embeddings to fully utilize an entity's complete neighborhood relationship information for better generalization. However, all these approaches just add extra simple processing load and do not fully utilize the overall structural features of KGs的整体结构特征,与SNRI不同,CNIA保留了集成的邻关系,利用双注意力机制对子图的结构特征进行处理,并引入了常识性重新排序。. Unlike SNRI, CNIA preserves the integrated neighbor relations, utilizes the dual attention mechanism to process the structural features of the subgraphs and introduces common-sense reordering.3. 常识性知识Commonsense Knowledge
常识性知识是解决人工智能和知识工程技术瓶颈的关键环节。而常识知识的获取是该领域的基本问题。最早的构建方法涉及专家手动定义知识库的架构和关系类型。Commonsense knowledge is a key component in solving bottlenecks in artificial intelligence and knowledge engineering technologies. And the acquisition of commonsense knowledge is a fundamental problem in the field. The earliest construction methods involved experts manually defining the architecture and types of relationships of a knowledge base. Lenat [30] constructed one of the oldest 在 1980 年代构建了最古老的知识库之一 CYC。然而,专家的施工方法需要大量的人力和物力资源。因此,研究人员开始开发半结构化和非结构化文本提取方法。YAGOknowledge bases, CYC, in the 1980s.However, expert construction methods require a lot of human and material resources. Therefore, researchers started to develop semi-structured and unstructured text extraction methods. YAGO [31]构建的常识性知识库包含超过 constructed a common-sense knowledge base containing more than 100万个实体和500万个事实,这些实体和事实来自半结构化的维基百科数据,并通过精心设计的基于规则和启发式方法的组合与 million entities and 5 million facts derived from semi-structured Wikipedia data and harmonized with WordNet协调一致。 上述方法通过建立定义明确的实体空间和相应的关系系统来优先考虑百科全书式的知识和结构存储。然而,实际的一般知识结构更加松散,并且很难应用于具有已知关系的两个实体的模型。因此,现有的解决方案是将实体部分建模为自然语言短语,并将关系建模为可以连接实体的任何概念。例如,t through a well-designed combination of rule-based and heuristic methods.The above approach prioritizes encyclopedic knowledge and structure storage by creating well-defined entity spaces and corresponding relational systems. However, actual general knowledge structures are more loosely organized and are difficult to apply to models of two entities with known relationships. Therefore, existing solutions model entity parts as natural language phrases and relationships as any concepts that can connect entities. For example, the OpenIE 方法揭示了开放文本实体和关系的属性。然而,该方法具有抽取性,难以获得文本的语义信息。approach reveals properties of open text entities and relationships. However, the method is extractive and it is difficult to obtain semantic information about the text.