Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Sangin Lee and Version 2 by Rita Xu.
Pedestrian detection is a critical task for safety-critical systems, but detecting pedestrians is challenging in low-light and adverse weather conditions. Thermal images can be used to improve robustness by providing complementary information to RGB images.
- autonomous vehicle
- computer vision
- data augmentation
- feature fusion
1. Introduction
Pedestrian detection, which involves predicting bounding boxes to locate pedestrians in an image, has long been studied due to its utility in various real-world applications, such as autonomous vehicles, video surveillance and unmanned aerial vehicles [1][2][3][4][1,2,3,4]. In particular, robust pedestrian detection in challenging scenarios is essential in autonomous driving application since it is directly related to human safety. However, modern RGB-based pedestrian detection methods failed to operate in challenging environments characterized by low illumination, rain, and fog [5][6][7][8][5,6,7,8]. To alleviate this problem, several methods [5][9][10][5,9,10] have emerged that leverage a thermal camera as a sensor complementary to the RGB camera already in use. Thermal cameras offer visual cues in challenging environments by capturing long-wavelength radiation emitted by subjects, thereby overcoming the limitations of RGB cameras in complex conditions.
To achieve successful multispectral pedestrian detection, it is important to consider three key factors: enhancing individual spectral features, understanding the relationships between inter-spectral features, and effectively aggregating these features. Building upon these principles, diverse multispectral pedestrian detection approaches have emerged, including single/multi-scale feature fusion [11][12][13][14][15][16][11,12,13,14,15,16] as well as iterative fusion-and-refinement methods [17][18][17,18]. These approaches have achieved impressive results with novel fusion techniques. However, most previous methods rely on a convolutional layer to enhance the modality-specific features and capture the correlations between them. Due to the lack of a receptive field in such convolution layers given their small kernel size, they have trouble capturing the long-range spatial dependencies of both intra- and inter-spectral images.
Recently, transformer-based fusion methods [19][20][19,20] that enhance the representation of each spectral feature map to improve the multispectral feature fusion have emerged. These methods capture the complementary information between multispectral images by employing an attention mechanism that assigns importance to input sequences by considering their relationships. While existing approaches achieve satisfactory detection results, they still have the disadvantage of neglecting or inadequately addressing the inherent relationship among intra-modality features.
In addition, rwesearchers observed that the detection performance was restricted due to the imbalanced distribution of locations where pedestrians appear. This imbalanced distribution frequently occurs in both multispectral [5][10][5,10] and single-spectral thermal pedestrian detection datasets [21][22][21,22]. To analyze this phenomenon, rwesearchers plot the distribution of the center of annotated pedestrians in the KAIST multispectral dataset and LLVIP dataset in Figure 1. As shown in the yellow square in Figure 1a, the number of pedestrian appearances is concentrated in specific regions biased to the right side. This result stems from the fact that KAIST dataset entries are acquired under right-hand traffic conditions, making it challenging to provide sufficient sight to detect pedestrians on the left side. In particular, pedestrian counts become intensely imbalanced in road scenarios where images were collected along arterial roads where sidewalks and traffic lanes are sharply divided (as shown in Figure 1b). As observed in Figure 1c, the phenomenon of pedestrian concentration persists even though the LLVIP dataset was captured from a video surveillance camera angle.
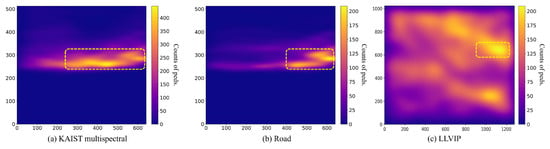
Figure 1. Analyzing the distribution of pedestrians in the KAIST multispectral dataset and LLVIP dataset using Gaussian Kernel Density Estimation (Gaussian KDE). In the (a) KAIST dataset, especially in the (b) road scene, pedestrians are more concentrated on the right side of the image for several reasons, including the road environment, where sidewalks are clearly divided and a right-hand driving condition prevails. In the (c) LLVIP dataset, while displaying a more uniform distribution, there is a persistent bias toward pedestrian over-appearance on the right side of the images. A plasma colormap is used to encode the distribution of the density, with blue indicating low density and yellow indicating high density. High density is marked with a yellow square.
2. Multispectral Pedestrian Detection
Multispectral pedestrian detection research has made significant progress with thermal images able to detect accurately pedestrians in a variety of challenging conditions. Hwang et al. [5] released a large-scale multispectral pedestrian dataset and proposed a hand-crafted Aggregated Channel Feature (ACF) approach that utilized the thermal channel features. This work had a significant impact on subsequent multispectral pedestrian detection research. Liu et al. [23] analyzed the feature fusion performance outcomes at different stages using the NIN (Network-In-Network) fusion strategy. Li et al. [16] demonstrated that multi-task learning using semantic segmentation could improve object detection performance capabilities compared to a detection-only approach. Zhang et al. [17] proposed a cyclic multispectral feature fusion and refinement method that improves the representation of each modality feature. Yang et al. [24] and Li et al. [25] designed an illumination-aware gate that adaptively modulates the fusion weights between RGB and thermal features using illumination information predicted from RGB images. Zhou et al. [18] leveraged common- and differential-mode information simultaneously to address modality imbalance problems considering both illumination and feature factors. Zhang et al. [11] proposed a Region Feature Alignment (RFA) module that adaptively interacts with the feature offset in an effort to address weakly aligned phenomena. Kim et al. [15] proposed a novel multi-label learning method to distinguish between paired and unpaired images for robust pedestrian detection in commercialized sensor configurations such as stereo vision systems. Although previous studies have achieved remarkable performance gains, convolution-based fusion strategies struggle to capture the global context effectively in both intra- and inter-spectral images despite the importance of doing so during the feature fusion process.
3. Attention-Based Fusion Strategies
Attention mechanisms [26][27][28][26,27,28] have led to a model capable of learning enhanced modality-specific information. Zhang et al. [12] proposed a cross-modality interactive attention mechanism that encodes the interaction between RGB and thermal modalities and adaptively fuses features to improve the pedestrian detection performance. Fu et al. introduced a pixel-level feature fusion attention module that incorporates spatial and channel dimensions. Zhang et al. [13] designed Guided Attentive Feature Fusion (GAFF) to guide the feature fusion of intra-modality and inter-modality features with an auxiliary pedestrian mask. With the success of the attention-based transformer mechanism [29] in natural language processing (NLP) and the subsequent development of a vision transformer (ViT) [30], several methods have attempted to utilize transformer-based attention schemes for multispectral pedestrian detection. Shen et al. [20] proposed a dual cross-attention transformer feature fusion framework for simultaneous global feature interaction and complementary information capturing across modalities. The proposed framework uses a query-guided cross-attention mechanism to interact with cross-modal information. Zhu et al. [31] proposed a Multi-modal Feature Pyramid Transformer (MFPT) using a feature pyramid architecture that simultaneously attends to spatial and scale information within and between modalities. Fang et al. [19] leveraged self-attention to execute intra-modality and inter-modality fusion simultaneously and to capture the latent interactions between RGB and thermal spectral information more effectively. However, transformer-based feature fusion methods have not yet fully realized the potential of attention mechanisms, as they do not effectively learn the complementary information between modalities.
4. Data Augmentations in Pedestrian Detection
Data augmentation is a key technique for improving the robustness and generalization of object detection. Pedestrian detection models commonly use augmentation approaches such as geometric transformations, including flips, rotation, and cropping, as well as other techniques such as zoom in, zoom out, cutmix [32], mixup [33], and others. In a previous study, Cygert et al. [34] proposed patch-based augmentation that utilized image distortions and stylized textures to achieve competitive results. Chen et al. [35] proposed shape transformations to generate more realistic-looking pedestrians. Chi et al. [36] and Tang et al. [37] introduced an occlusion-simulated augmentation method that divides pedestrians into parts and fills in with the mean values of ImageNet [38] or images to improve the degree of robustness to occlusions. To address the motion blur problem in an autonomous driving scene, Khan et al. [39] designed hard mixup augmentation, which is an image-aware technique that combines mixup [33] augmentation with hard labels. To address the paucity of data on severe weather conditions, Tumas et al. [40] used a DNN-based augmentation that modified training images with Gaussian noise to mimic adverse weather conditions. Kim et al. [15] proposed semi-unpaired augmentation, which stochastically applies augmentation to one of the multispectral images. This breaking of the pair allows the model to learn from both paired and unpaired conditions, demonstrating good generalization performance.