Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by SONG Hyoung-Kyu and Version 2 by Catherine Yang.
Bioinformatics and genomics are driving a healthcare revolution, particularly in the domain of drug discovery for anticancer peptides (ACPs). The integration of artificial intelligence (AI) has transformed healthcare, enabling personalized and immersive patient care experiences. These advanced technologies, coupled with the power of bioinformatics and genomic data, facilitate groundbreaking developments. The precise prediction of ACPs from complex biological sequences remains an ongoing challenge in the genomic area.
- artificial intelligence
- machine learning
- bioinformatics
- metaverse
1. Introduction
Healthcare is paramount for global well-being and crucial in fostering services and contributing to economic growth [1]. Technological advancements such as blockchain, augmented reality (AR), and virtual reality (VR) have transformed patient–physician interactions [2]. At the same time, the healthcare system in the metaverse integrates AI, telepresence, digital twinning, and blockchain to facilitate affordable treatments and improve patient outcomes [3]. Figure 1 illustrates the different applications of metaverse in healthcare. The metaverse also delivers personalized, immersive care by integrating real and virtual worlds [4]. Cancer remains a major global health threat, causing millions of deaths annually [5]. Although conventional treatments such as radiotherapy, target therapy, and chemotherapy can effectively target cancer cells, they also impose significant financial burdens and affect healthy cells [6]. To address these challenges, there is a growing need for an automated system to accurately identify ACPs from complex biological sequences, ensuring timely diagnosis and management before the condition worsens. Peptides have been recognized as effective cancer treatments due to their minimal impact on normal physiological activities and have been extensively studied in preclinical research for multiple purposes, including cardiovascular disease, diabetes, and other types of cancer [7]. In studies by Ijaz et al. [8], an early cervical cancer prediction model was developed using the CCPM. Saha et al. [9] studied different prognostic characters of GLS and GLS2 in cancer, showcasing their variance impact on clinical results across diverse cancer types. Figure 2 illustrates different cancer treatment options that involve targeting peptides.
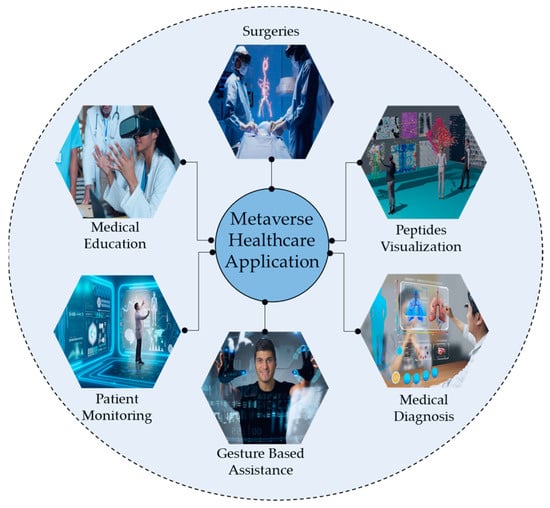
Figure 1.
Several applications of the metaverse in healthcare and education for peptides visualization.
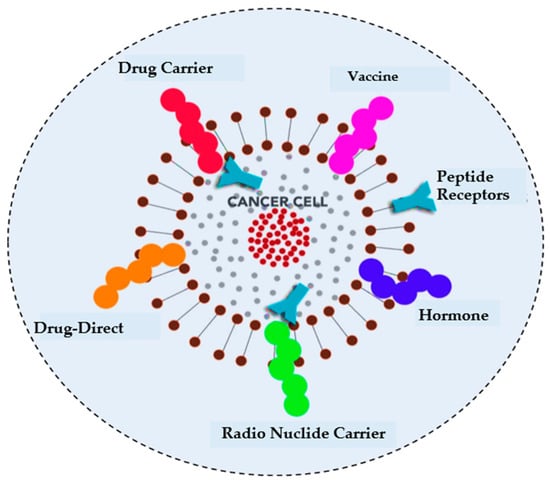
Figure 2.
Peptide sequences offer a range of potential treatment options for cancer, which can be explored and evaluated for their effectiveness.
An ACP is a small sequence typically containing fewer than 50 amino acids [10]. A new direction for cancer treatment has been opened by determining ACPs because they have cationic properties that can easily target cancer-affected cells without interacting with normal cells [11]. However, ACPs have some potential drawbacks in the drug development process, i.e., high production costs and low stability [12]; despite this, they have some unique merits. ACPs are biological substances that naturally exist in a living organism; hence, they are more harmless than synthetic drugs and have better efficacy [13]. Over the last decade, peptide-based techniques have been used in numerous clinical trials for disease prevention and treatment [14], including heart disease, diabetes, and tumors. Experimental identification process of ACPs is very costly and time-consuming which is rarely utilized in clinical practice.
2. Metaverse Applications in Bioinformatics
Several intelligent models for identifying ACPs have been proposed by different researchers. For example, a silico model was proposed by [15], where AAC and binary profile-based information are used as a feature extraction method, obtaining 91.44% accuracy for binary classification. Similarly, Hajisharifi et al. [16] developed a novel approach, where PseAAC and local alignment kernel techniques are explored for feature extraction and achieved the outcomes of 89.7% and 83.82%, respectively. Next, this work is further boosted by Chen et al. [17], who introduced a sequence-based model that utilizes g-gap dipeptide composition and cross-validation techniques for superior performance; therefore, 94.77% accuracy was obtained for the discrimination of peptides. Akbar et al. [18] utilized an ensemble classifier for the discrimination of various peptides to obtain robust features: amphibolic PseAAC, reduced AAC, and g-gap DPC were considered, and a 96.45% classification score was obtained. Xu et al. [19] developed a model that considers ACP composition by incorporating binary encoding and physicochemical properties to obtain meaningful information but the performance is 91.86% which is a low discrimination score as compared to the other models. The sequence-based models have successfully identified novel ACP but due to technological advancement substantial work has been presented in the metaverse specifically for human healthcare. Recent research has explored the metaverse’s potential in healthcare, covering various applications and challenges. Bansal et al. [20] outlined its uses in immersive training experiences, telemedicine, and clinical care, emphasizing extended reality (XR) technologies and hardware. Another study [21] focused on ophthalmology, utilizing VR and digital twins (DTs) for personalized care. Next, Ali et al. [22] proposed a secure metaverse architecture with blockchain and eXplainable AI (XAI) for transparent disease prediction. Moreover, Razdan and Sharma [23] proposed a comprehensive metaverse architecture, emphasizing big data processing and security measures, while a reference architecture with distinct layers is also presented for metaverse applications, ensuring robust governance and quality of service. Moreover, some researchers have used alternative methods such as the generalized chaos game representation [24] short-term memory models with binary profile features and k-mer sparse matrices using two novel benchmark datasets (ACP740 and ACP240) [25]. Chen et al. introduced an ACP-DA model, composed of DL and augmentation approaches, resulting 82.03% and 88.33% on ACP740 and ACP240 datasets, respectively [26]. Next, Ye et al. [27] proposed an ensemble learning model using numerous datasets [16][28][16,28] with which 95.4% and 92.4% accuracies were obtained after comprehensive experiments. Moreover, in [29] ETree classfier and AAC feature extractor are used for the discrimination of different biological sequences. Akbar et al. also explored ensemble classification for ACPs and attained 96.45% accuracy using an evolutionary genetic algorithm (iACP-GAEnsC) [18]. Shahid Akbar et al. developed cACP-DeepGram by utilizing three statistical feature representation schemes and achieved satisfactory outcomes of 96.94% accuracy [30]. Shahid Akbar et al. also introduced cACP, a discriminatory computational technique employing diverse statistical feature representation schemes, and feature selection PCA, and achieved a tremendous classification score of 96.91% [31]. Shahid Akbar et al. made a notable contribution with their proposed cACP-2LFS, a novel sequential discriminative model designed for ACP classification. In addition, their model utilizes the K-space amino acid pair (KSAAP) for extracting correlated descriptors and incorporates a two-level feature selection (2LFS) method, resulting in impressive accuracy rates of 94.11% and 93.72% using independent and LEE datasets, respectively. These achievements highlight its potential applications in the fields of medicine, proteomics, and research academia [32]. Despite these attempts, some recent studies have explored DL models for the efficient classification of ACPs from complex biological sequences. Ahmed et al. presented a novel multi-head deep CNN by extracting discriminative physicochemical properties from diverse peptides, followed by evolutionary-based features, leading 83.0%, 86.0%, and 91.0% accuracies levels on ACP-240, ACP-740, and a combination both datasets, respectively [33]. Hulam et al. proposed DL-based method that uses dipeptide deviation from the expected mean (DDE) as a feature extractor for precise predictions of ACPs, outperforming the 85.88% and 84.8% accuracies score using ACP240 and ACP740 datasets [34]. Advanced DL methods such as MLACP 2.0 [35] incorporate seven distinctive classifiers and multiple feature encoding methods. In addition, other mainstream approaches applied neural networks and multitask learning, where they incorporate hybrid sequencing information [36][37][36,37]. Recently, ensemble classifiers have gained popularity in ACP classification, where a decision has been made based on the majority vote of multiple machine learning algorithms, such as an SVM, an RF, and AdaBoost. Ensemble classifiers leverage individual algorithms for their strengths and mitigate their weaknesses for improved performance. The results obtained with this approach are superior to those from a single algorithm [38]. Multi-algorithm ensemble clustering aggregates the results of different clustering algorithms to produce more accurate and robust consensus clustering results. Ensemble clustering has many applications, such as image segmentation and gene expression analysis, and can make the clustering process more robust and accurate by embracing ensemble methods [39]. Various integrated methods have been used to evaluate regression [40][41][40,41] and classification [42][43][42,43] problems in the literature, including weighted averaging [44], weighted voting [45], simple averaging [46], and majority voting [47]. Other techniques can also be used for protein analysis, such as combining individual sequence-based models to generate a final prediction. To predict the biological functions and properties of peptides and proteins, sequence-based statistical predictors require machine learning algorithms and feature extraction techniques. Predictors of protein–protein interactions, protein subcellular localization, and ACPs have shown promising results in several applications, and developing new therapeutics requires the development of such predictors [48]. Several computational methods have been developed to classify ACPs and non-ACPs, but there is still room for improvement. To overcome the research gap mentioned later in the paper, this study proposed a new collection of computational approaches to improve the classification performance for new biological sequences. The suggested system could lead to a better understanding of ACPs and aid in the development of new therapeutics.-
The imbalanced nature of datasets in anticancer peptide classification poses a significant hurdle for many existing machine learning methods. Biased models can emerge, favoring classes with a higher number of instances, thereby compromising the model’s ability to accurately identify and classify less-represented classes. This imbalance issue is particularly critical in the context of anticancer peptides, where a thorough understanding of diverse instances is crucial for effective classification.
-
Prevailing methods often lean towards simplicity, employing single-feature extractions and classifiers. While this simplicity aids in model interpretability and computational efficiency, it may fall short of capturing the intricate and nuanced patterns inherent in anticancer peptides. The complex nature of these peptides demands more sophisticated approaches that can discern subtle variations and relationships within the data, enhancing the model’s discriminatory power.
-
Current strategies aimed at enhancing classification accuracy often resort to fusion techniques. While these techniques offer potential improvements, they may inadvertently introduce homogeneity in the utilized information, leading to limiting the model’s ability to discern diverse and subtle characteristics crucial for accurate anticancer peptide classification. Striking a balance between fusion for improved accuracy and preserving the diversity of information remains a key challenge in developing robust models.
-
Some machine learning-based methods in anticancer peptide classification may exhibit a tendency to overlook the expansive landscape of feature extraction models and selection techniques. A more comprehensive exploration of this landscape is imperative to ensure that potentially more effective approaches are not neglected. The diversity among anticancer peptides demands a thorough examination of various feature extraction methods and selection techniques to uncover the most suitable combination for accurate classification.