Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Shimin Cai and Version 2 by Rita Xu.
Event coreference resolution is the task of clustering event mentions that refer to the same entity or situation in text and performing operations like linking, information completion, and validation. Existing methods model this task as a text similarity problem, focusing solely on semantic information, neglecting key features like event trigger words and subject.
- coreference resolution
- relationship prediction
- universal information extraction
1. Introduction
Event coreference resolution (ECR) is a crucial natural language processing task that involves identifying and clustering together different textual mentions of the same event. The task holds significant importance in enabling a variety of downstream applications, including information extraction, question answering, text summarization, etc. [1][2][1,2]. For example, in the application of information extraction, ECR can help to build more coherent and complete knowledge graphs or databases by linking different mentions of the same event and correctly identifying and linking relevant information to answer questions accurately [3]. Figure 1 shows an example of the ECR task, where the input consists of two different segments of text and the output is the binary confidence of event coreference.
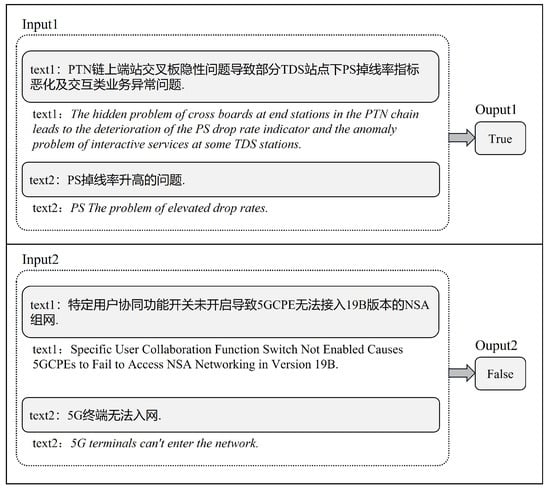
Figure 1. Example illustration of ECR task.
ECR is also an important part of constructing event graphs [4]. The entire process is similar to entity linking in knowledge graphs, where identical event nodes in the real world are clustered together, further improving and supplementing the various components of the event and saving them as a new node in the graph structure. Some researchers have modeled the ECR task as a text similarity calculation problem, using neural networks such as CNN (Convolutional Neural Network) [5] and RNN (Recurrent Neural Network) [6] to represent two pieces of text as vectors and determining whether they are coreferential by calculating the similarity between the vectors. With the emergence of pre-training models such as BERT [7], some researchers have used the output of pre-training models as the vector representation of text and calculated similarity. Others have used Siamese networks [8] to classify event pairs and determine if they are coreferential.
However, training neural networks such as CNN and RNN to represent text as vectors requires training parameters from scratch and is not suitable for small datasets [9]. In contrast, pre-training models only need to be fine-tuned after being pre-trained on a large corpus, which can achieve faster convergence speed when combined with downstream tasks. Additionally, determining event coreference based on whether the similarity reaches a threshold is biased, as there may not be a clear classification boundary for this task, making it difficult to determine the threshold, or there may not be a clear boundary at all. Using BERT for text representation or Siamese networks for text classification also fails to fully utilize the inherent next sentence prediction (NSP). Furthermore, the above techniques only focus on the semantic information of the event description text, ignoring a variety of key features such as event trigger words and event subjects, resulting in missing features.
To address the limitations of existing techniques, reswearchers propose a short text event coreference resolution method based on context prediction (referred to ECR-CP). The novelty of ECR-CP is illustrated from three perspectives. In more detail, from a problem-modeling perspective, researcherswe model the ECR task as a sentence-level relationship prediction issue by utilizing the NSP inherent in BERT. ResearchersWe consider pairs of events that can form a continuous sentence-level relationship to have coreferential relationships. This is consistent with human language habits, where coherent sentences in everyday conversations often describe the same fact. From a feature extraction perspective, researcherswe extract key information such as trigger words, argument roles, event types, and tense from event extraction and incorporate them as auxiliary features to improve the accuracy. From the algorithm performance perspective, BERT-based ECR-CP has a smaller training cost and achieves better performance in comparison to the other benchmark methods based on neural networks.