Against the backdrop of ongoing urbanization, issues such as traffic congestion and accidents are assuming heightened prominence, necessitating urgent and practical interventions to enhance the efficiency and safety of transportation systems. A paramount challenge lies in realizing real-time vehicle monitoring, flow management, and traffic safety control within the transportation infrastructure to mitigate congestion, optimize road utilization, and curb traffic accidents. In response to this challenge, the present study leverages advanced computer vision technology for vehicle detection and tracking, employing deep learning algorithms. The resultant recognition outcomes provide the traffic management domain with actionable insights for optimizing traffic flow management and signal light control through real-time data analysis. The study demonstrates the applicability of the SE-Lightweight YOLO algorithm, as presented herein, showcasing a noteworthy 95.7% accuracy in vehicle recognition. As a prospective trajectory, this research stands poised to serve as a pivotal reference for urban traffic management, laying the groundwork for a more efficient, secure, and streamlined transportation system in the future.
To solve the existing vehicle detection problems in vehicle type recognition, recognition and detection accuracy need to be improved, alongside resolving the issues of slow detection speed, and others. In this paper, we made innovative changes based on the YOLOv7 framework: we added the SE attention transfer mechanism in the backbone module, and the model achieved better results, with a 1.2% improvement compared with the original YOLOv7. Meanwhile, we replaced the SPPCSPC module with the SPPFCSPC module, which enhanced the trait extraction of the model. After that, we applied the SE-Lightweight YOLO to the field of traffic monitoring. This can assist transportation-related personnel in traffic monitoring and aid in creating big data on transportation. Therefore, this research has a good application prospect.
- vehicle inspection
- YOLOv7
- deep learning
- attention mechanism
1. Introduction
2. Breif Introduction of YOLOv7
2.1. YOLOv7 Object Detection Algorithm
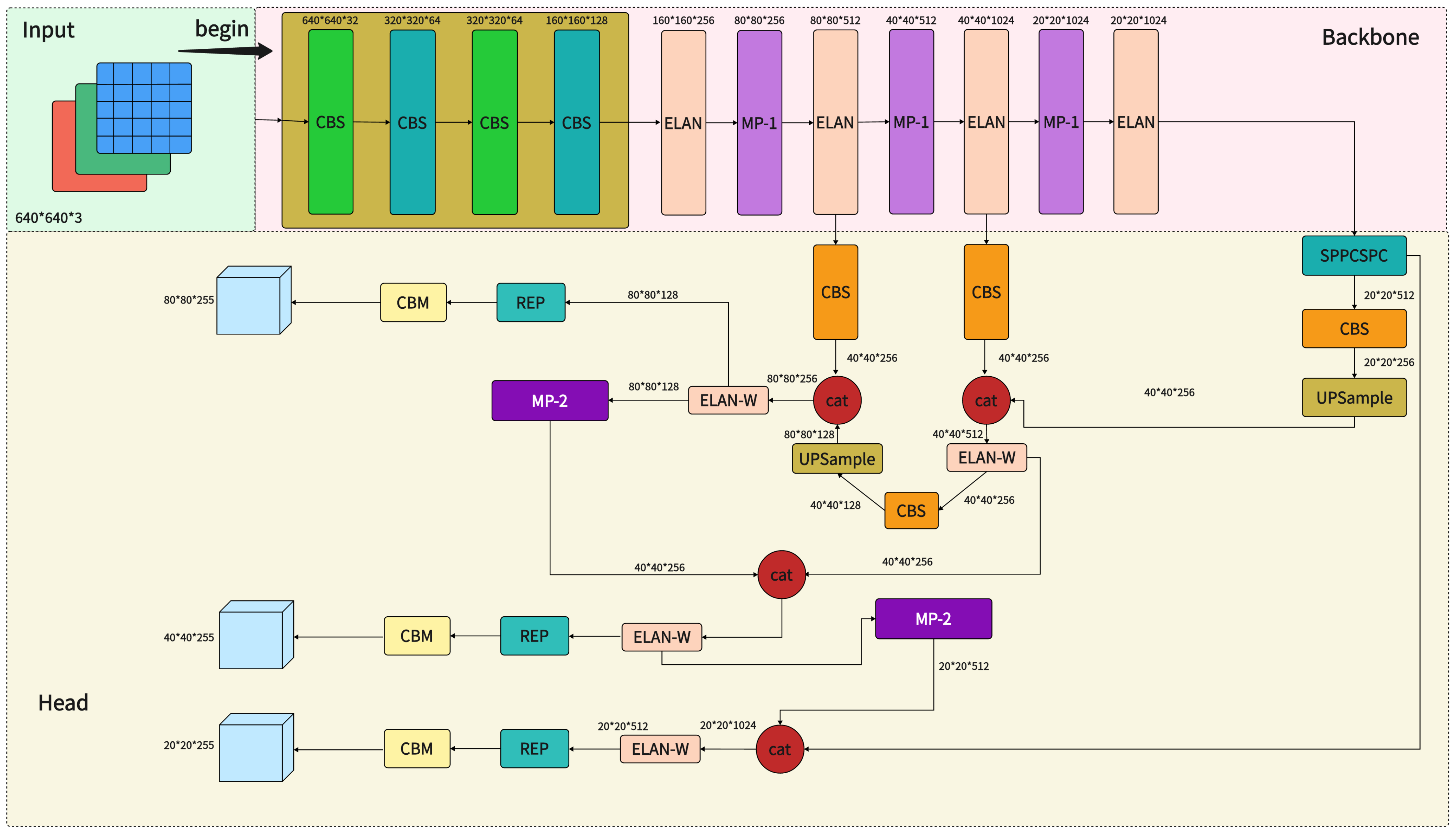
As we know, the YOLOv7 series has eight variants: YOLOv7-tiny, YOLOv7, YOLOv7-W6, YOLOv7-X, YOLOv7-E6, YOLOv7-E6E, and other two models which use leaky ReLU and SiLU as the activation function of the model. YOLOv7 contains four modules: input, backbone, head, and neck.2.1.1. Input
The input side of YOLOv7 follows the overall logic of YOLOv5 and does not introduce new tricks. The logic mainly calculates the scaling ratio between the native size of the image and the input size to obtain the scaled image size. It then finally performs adaptive filling to obtain the final input image. After inputting the image into the model, it is normalized and converted into many layers of 640×640×3640×640×3 images, and the processed image is fed into the backbone later.2.1.2. Backbone
In YOLOv7, the primary function of the backbone network is to extract features from the input image. Feature extraction is a critical step that transforms the original image into a series of feature maps with high-level semantic information that will be used in subsequent target detection tasks.2.1.3. Neck
The neck acts as a bridge between the backbone and head modules. The neck plays a crucial role in target detection. It is used for multi-scale feature fusion and further feature processing. Therefore, one of the main functions of the neck is to fuse feature maps from different backbone network layers. Since the backbone network usually includes multiple feature maps from different layers, the neck fuses these feature maps so that the model can simultaneously process information at multiple scales. This is important for detecting targets of different sizes.2.1.4. Head
The detection header of the target detection model is a vital component of the entire YOLOv7 architecture and is responsible for generating the final target detection results. The detailed functions of the detection head in YOLOv7 are below:-
Bounding Box RegressionThe target’s position in the input image is usually represented as the bounding box coordinates. For each detection box, the header generates four values representing the coordinates of the bounding box’s upper left and lower right corners.
-
Class ClassificationAnother critical function is to categorize the detected targets. The detection header generates a category probability distribution for each detection frame, indicating the probability that the target belongs to each possible category. Usually, the model selects the category with the highest probability as the predicted category.
-
Object Confidence EstimationIn addition to location and category, the detection header generates a target confidence score, which indicates the model’s confidence in whether each bounding box contains a valid target. This score is typically used to filter out detections with high confidence.
-
Other function
References
- Dimitrakopoulos, G.; Demestichas, P. Intelligent Transportation Systems. IEEE Veh. Technol. Mag. 2010, 3, 77–84.
- Zeng, Y. Optimal Control and Application of Traffic Light Timing Based on Fuzzy Control. Master’s Thesis, Changsha University of Technology, Changsha, China, 2020.
- Issues Report: Smart Transportation Market. Manufacturing Close-Up. 2020. Available online: https://www.researchandmarkets.com/ (accessed on 26 October 2023).
- Cao, Z.W. Research on highway congestion mitigation technology based on intelligent transport. Intell. Build. Smart City 2023, 168–170.