Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Xueping Wang and Version 2 by Catherine Yang.
There are problems associated with facial expression recognition (FER), such as facial occlusion and head pose variations. These two problems lead to incomplete facial information in images, making feature extraction extremely difficult.
- facial expression recognition
- sliding window
- local feature enhancement
1. Introduction
Facial expressions are the most intuitive and effective body language symbols to convey emotions. Facial expression recognition (FER) enables machines to recognize human facial expressions automatically. FER has made a massive contribution to the fields of human–computer interactions [1], vehicle-assisted driving [2], medical services [3], and social robots [4]. FER is becoming an increasingly active field, and great progress has been made in this area in the past few decades.
Excellent recognition results [5][6][5,6] have been achieved on datasets collected in controlled laboratory environments, such as CK+ [7], MMI [8], and JAFFE [9]. However, in the wild, FER is still far from satisfactory. Occlusions and head pose variations are the common, intractable problems experienced in unconstrained settings. Therefore, researchers have proposed diverse real-world facial expression datasets such as FER2013 [10], RAF-DB [11], AffectNet [12] to advance the development of FER in the wild. The authors of [13][14][15][16][13,14,15,16] have made great contributions based on datasets of natural scenes. Li et al. [15] used the face as a whole to obtain various global features to produce a competitive performance, but they ignored the importance of local features. Occlusion or the appearance of poses in the wild can cause the effective information about the face to be incomplete. Therefore, it is difficult to mine significant expression features, resulting in the model having a poor discrimination ability. Karnati et al. [5] and Ruan et al. [6] showed that the learning of fine-grained features plays a huge role in expression recognition, thus considering both global features and local features is a better choice.
Most current methods for obtaining local features crop essential areas of the face through prior knowledge [16][17][18][16,17,18] or directly crop the face into patches of fixed size [14][19][14,19]. However, these methods have some problems: (1) The method of cropping faces through prior knowledge is in the data preprocessing stage, and most research methods conduct cropping based on landmarks. Although this method is intuitive, facial keypoint detection is prone to the effects of occlusion and pose. As shown in Figure 1a, landmarks are not accurately located. Therefore, the cropping method based on prior knowledge itself contains certain noise. (2) The cropping of images into fixed-scale patches does not require prior knowledge but may divide useful features into different patches. As shown in Figure 1b, eyes are an essential feature for judging expressions, and direct segmentation may divide the same eye into several different patches, causing the integrity of essential features to be destroyed. Thus, the sliding window-based cropping strategy is introduced to obtain the complete feature, as shown in Figure 1c. It requires no prior knowledge and ensures that essential features are not segmented, which is beneficial for FER.
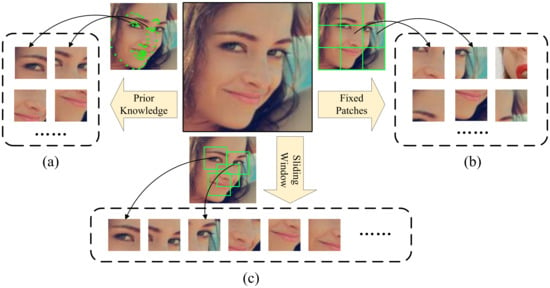
Figure 1. Different cropping strategies for facial expression images. (a) Cropping based on prior knowledge. Green dots represent facial landmarks. Positioning and cropping can be performed according to point coordinates. (b) Cropping based on fixed-size patches. The face image is equally divided into 9 regions. (c) Cropping based on sliding window. The window scans the entire face image and accurately locates the key regions of the face.
2. Facial Expression Recognition in the Wild
Some traditional methods use feature engineering, including SIFT [20], HOG [21], and Gabor [22], to focus on global facial information. This has achieved good results. Convolutional Neural Networks (CNN) have been employed with success in the image field, and Fasel et al. [23] found that they have strong robustness to facial pose and scale in face recognition tasks. Tang et al. [24] and Kahou et al. [25] designed deep CNN models to win the championships of FER2013 and Emotiw2013. With the development of GPU hardware, more and more models using deep CNN are being developed. FER based on deep learning has gradually gained the upper hand and become a mainstream research method. Researchers rely on powerful deep learning to quickly overcome the challenge associated with FER in a controlled environment.
More and more researchers are turning their attention to challenging wild environment conditions and working on solving facial recognition problems under natural conditions [26] including illumination changes, occlusions, head pose variations, and blur. Karnati et al. [5] proposed the use of multiscale convolution to obtain more fine-grained features and reduce intraclass differences, aiming to solve the illumination problem. Zhang et al. [27] proposed the use of “uncertainty” learning to quantify the degree of “uncertainty” for various noise problems in facial expressions, mixing “uncertainty” features from different faces to separate noise and expression features. Zou et al. [28] regarded expressions as a weighted sum of different types of expressions and learned basic expression features through a sequential decomposition mechanism. Fan et al. [29] designed a two-stage training program to further recognize expressions using identity information. Zhang et al. [13] proposed Erasing Attention Consistency, which mines the features of the expression itself, rather than the label-related features, to suppress the learning of noise information during training. Ruan et al. [6] learned intraclass features and interclass features by decomposing and reconstructing. Jiang et al. [30] proposed an identity and pose disentangled method, which separates expression features from the identity and pose.
3. Facial Expression Recognition Based on Local Features
Due to the enormous difficulty in recognizing expression images in the natural environment, guiding models to mine local significant features has become the choice of more researchers. Local-based FER uses some strategies to crop the face image into several local regions and solves the noise problem associated with facial images in the real world by obtaining local information. Li et al. [18] cut out 24 small patches according to the landmark coordinates, generated corresponding weights according to the degree of occlusion, and then predicted the result with the global features. Wang et al. [17] considered multiple cropping strategies and proposed the RB-Loss method to assign different weights to different regions. Zhao et al. [19] reduced the occlusion and pose interference through the use of multiscale features and local attention modules. Liu et al. [16] proposed adaptive local cropping, and particularly cropped the eye and mouth parts, guiding the model to find more distinguishable parts. This method is robust to occlusion and pose changes. Krithika et al. [31] segmented the face and background information and then cut out the eyes, nose, and mouth and proposed a Minimal Angular Feature-Oriented Network to obtain specific expression features. Xue et al. [14] guided the model to learn diverse information within patches and identified rich relationships between patches. Although these methods focus on local features through facial key point cropping or fixed-size cropping, the former will cause inaccurate key point positioning due to facial occlusion and head poses, and the latter may divide essential features into different patches, thereby destroying the integrity of features. Even if this effect is mitigated by mixing the two cropping strategies, the model will still ignore finer expression details, such as brows and muscle lines.