Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by AMAL NAITALI and Version 3 by Lindsay Dong.
Deepfakes, is a fast-developing field at the nexus of artificial intelligence and multimedia. These artificial media creations, made possible by deep learning algorithms, allow for the manipulation and creation of digital content that is extremely realistic and challenging to identify from authentic content. Deepfakes can be used for entertainment, education, and research; however, they pose a range of significant problems across various domains, such as misinformation, political manipulation, propaganda, reputational damage, and fraud.
- deepfake detection
- face forgery
- deep learning
- generative artificial intelligence
1. Introduction
Deepfakes are produced by manipulating existing videos and images to produce realistic-looking but wholly fake content. The rise of advanced artificial intelligence-based tools and software that require no technical expertise has made deepfake creation easier. With the unprecedented exponential advancement, the world is currently witnessing in generative artificial intelligence, the research community is in dire need of keeping informed on the most recent developments in deepfake generation and detection technologies to not fall behind in this critical arms race.
Deepfakes present a number of serious issues that arise in a variety of fields. These issues could significantly impact people, society [1], and the reliability of digital media [2]. Some significant issues include fake news, which can lead to the propagation of deceptive information, manipulation of public opinion, and erosion of trust in media sources. Deepfakes can also be employed as tools for political manipulation, influence elections, and destabilize public trust in political institutions [3][4][3,4]. In addition, this technology enables malicious actors to create and distribute non-consensual explicit content to harass and cause reputational damage or create convincing impersonations of individuals, deceiving others for financial or personal gains [5]. Furthermore, the rise of deepfakes poses a serious issue in the domain of digital forensics as it contributes to a general crisis of trust and authenticity in digital evidence used in litigation and criminal justice proceedings. All of these impacts show that deepfakes present a serious threat, especially in the current sensitive state of the international political climate and the high stakes at hand considering the conflicts on the global scene and how deepfakes and fake news can be weaponized in the ongoing media war, which can ultimately result in catastrophic consequences.
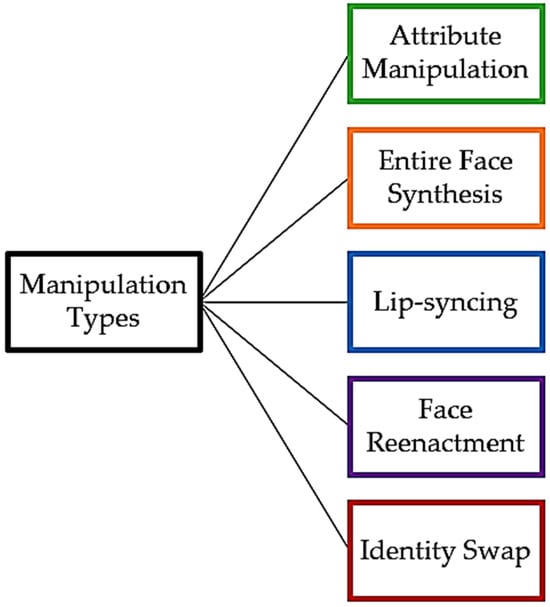 The most common manipulation types are identity swap or face swapping, face reenactment, and lip-syncing. Face swapping [8][9][34,35] is a form of manipulation that has primarily become prevalent in videos even though it can occur at the image level. It entails the substitution of one individual’s face in a video, known as the source, with the face of another person, referred to as the target. In this process, the original facial features and expressions of the target subject are mapped onto the associated areas of the source subject’s face, creating a seamless integration of the target’s appearance into the source video. The origins of research on the subject of identity swap can be traced to the morphing method introduced in [10][36].
The most common manipulation types are identity swap or face swapping, face reenactment, and lip-syncing. Face swapping [8][9][34,35] is a form of manipulation that has primarily become prevalent in videos even though it can occur at the image level. It entails the substitution of one individual’s face in a video, known as the source, with the face of another person, referred to as the target. In this process, the original facial features and expressions of the target subject are mapped onto the associated areas of the source subject’s face, creating a seamless integration of the target’s appearance into the source video. The origins of research on the subject of identity swap can be traced to the morphing method introduced in [10][36].
23. Deepfake Generation
2.1. Deepfake Manipulation Types
3.1. Deepfake Manipulation Types
There exist five primary types of deepfake manipulation, as shown in Figure 1. Face synthesis [6][32] is a manipulation type which entails creating images of a human face that does not exist in real life. In attribute manipulation [7][33], only the region that is relevant to the attribute is altered alone in order to change the facial appearance by removing or donning eyeglasses, retouching the skin, and even making some more significant changes, like changing the age and gender.Figure 1.
The five principal categories of deepfake manipulation.
2.2. Deepfake Generation Techniques
3.2. Deepfake Generation Techniques
Multiple techniques exist for generating deepfakes. Generative Adversarial Networks GANs [11][40] and Autoencoders are the most prevalent techniques. GANs consist of a pair of neural networks, a generator network and discriminator network, which engage in a competitive process. The generator network produces synthetic images, which are presented alongside real images to the discriminator network. The generator network learns to produce images that deceive the discriminator, while the discriminator network is trained to differentiate between real and synthetic images. Through iterative training, GANs become proficient at producing increasingly realistic deepfakes. On the other hand, Autoencoders can be used as feature extractors to encode and decode facial features. During training, the autoencoder learns to compress an input facial image into a lower-dimensional representation that retains essential facial features. This latent space representation can then be used to reconstruct the original image. Though, for deepfake generation, two autoencoders are leveraged, one trained on the face of the source and another trained on the target. Numerous sophisticated GAN-based techniques have emerged in the literature, contributing to the advancement and complexity of deepfakes. AttGAN [12][41] is a technology for facial attribute manipulation; its attribute awareness enables precise and high-quality attribute changes, making it valuable for applications like face-swapping and age progression or regression. Likewise, StyleGAN [13][42] is a GAN architecture that excels in generating highly realistic and detailed images. It allows for the manipulation of various facial features, making it a valuable tool for generating high-quality deepfakes. Similarly, STGAN [7][33] modifies specific facial attributes in images while preserving the person’s identity. The model can work with labeled and unlabeled data and has shown promising results in accurately controlling attribute changes. Another technique is StarGANv2 [14][43], which is able to perform multi-domain image-to-image translation, enabling the generation of images across multiple different domains using a single unified model. Unlike the original StarGAN [15][44], which could only perform one-to-one translation between each pair of domains, StarGANv2 [14][43] can handle multiple domains simultaneously. An additional GAN variant is CycleGAN [16][45], which specializes in style transfer between two domains. It can be applied to transfer facial features from one individual to another, making it useful for face-swapping applications. In addition to the previously mentioned methods, there is a range of open-source tools readily available for digital use, enabling users to create deep fakes with relative ease, like FaceApp [17][48], Reface [18][49], DeepBrain [19][50], DeepFaceLab [20][51], and Deepfakes Web [21][52]. These tools have captured the public’s attention due to their accessibility and ability to produce convincing deepfakes. It is essential for users to utilize these tools responsibly and ethically to avoid spreading misinformation or engaging in harmful activities. As artificial intelligence is developing fast, deepfake generation algorithms are simultaneously becoming more sophisticated, convincing, and hard to detect.34. Deepfake Detection
3.1. Deepfake Detection Clues
4.1. Deepfake Detection Clues
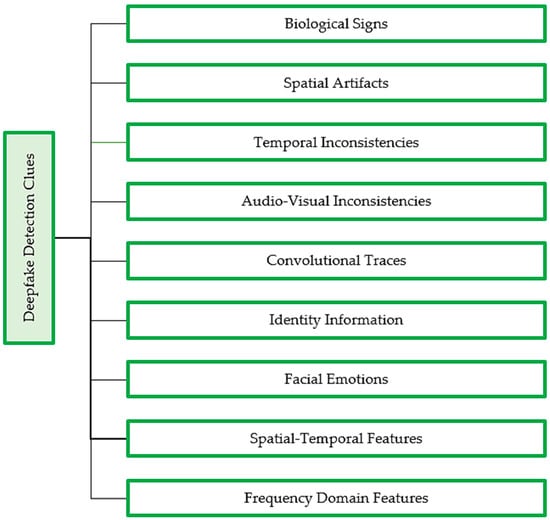
Deepfakes can be detected by exploiting various clues, as summarized in Figure 2. One approach is to analyze spatial inconsistencies by closely examining deepfakes for visual artifacts, facial landmarks, or intra-frame inconsistencies. Another method involves detecting convolutional traces that are often present in deepfakes as a result of the generation process, for instance, bi-granularity artifacts and GAN fingerprints. Additionally, biological signals such as abnormal eye blinking frequency, eye color, and heartbeat can also indicate the presence of a deepfake, as can temporal inconsistencies or the discontinuity between adjacent video frames, which may result in flickering, jittering, and changes in facial position. Poor alignment of facial emotions on swapped faces in deepfakes is a high-level semantic feature used in detection techniques. Detecting audio-visual inconsistencies is a multimodal approach that can be used for deepfakes that involve swapping both faces and audio.Figure 2. Clues and features employed by deepfake detection models in the identification of deepfake content.
3.1.1. Detection Based on Spatial Artifacts
To effectively use face landmark information, in Ref. [22], Liang et al. described a facial geometry prior module. The model harnesses facial maps and correlation within the frequency domain to study the distinguishing traits of altered and unmanipulated regions by employing a CNN-LSTM network. In order to predict manipulation localization, a decoder is utilized to acquire the mapping from low-resolution feature maps to pixel-level details, and SoftMax function was implemented for the classification task. A different approach, dubbed forensic symmetry, by Li, G. et al. [23], assessed whether the natural features of a pair of mirrored facial regions are identical or dissimilar. The symmetry attribute extracted from frontal facial images and the resemblance feature obtained from profiles of the face images are obtained by a multi-stream learning structure that uses DRN as its backbone network. The difference between the two symmetrical face patches is then quantified by mapping them into angular hyperspace. A heuristic prediction technique was used to put this model into functioning at the video level. As a further step, a multi-margin angular loss function was developed for classification.
3
Clues and features employed by deepfake detection models in the identification of deepfake content.
4.1.1. Detection Based on Spatial Artifacts
To effectively use face landmark information, in Ref. [53], Liang et al. described a facial geometry prior module. The model harnesses facial maps and correlation within the frequency domain to study the distinguishing traits of altered and unmanipulated regions by employing a CNN-LSTM network. In order to predict manipulation localization, a decoder is utilized to acquire the mapping from low-resolution feature maps to pixel-level details, and SoftMax function was implemented for the classification task. A different approach, dubbed forensic symmetry, by Li, G. et al. [54], assessed whether the natural features of a pair of mirrored facial regions are identical or dissimilar. The symmetry attribute extracted from frontal facial images and the resemblance feature obtained from profiles of the face images are obtained by a multi-stream learning structure that uses DRN as its backbone network. The difference between the two symmetrical face patches is then quantified by mapping them into angular hyperspace. A heuristic prediction technique was used to put this model into functioning at the video level. As a further step, a multi-margin angular loss function was developed for classification.
 Furthermore, data augmentation plays a crucial role in training deep learning-based detection models. This technique involves augmenting the training dataset with synthetic or modified samples, which enhances the model’s capacity to generalize and recognize diverse variations of deepfake media. Data augmentation enables the model to learn from a wider range of examples and improves its robustness against different types of manipulations. Attention mechanisms have also proven to be valuable additions to deep learning-based detection models. By directing the model’s focus toward relevant features and regions of the input data, attention mechanisms enhance the model’s discriminative power and improve its overall accuracy. These mechanisms help the model select critical details [43][92], making it more effective in distinguishing between real and fake media. Collectively, the combination of deep learning-based architectures, meta-learning, data augmentation, and attention mechanisms has significantly advanced the field of deepfake detection. These technologies work in harmony to equip models with the ability to identify and flag manipulated media with unprecedented accuracy.
The Convolutional Neural Network is a powerful deep learning algorithm designed for image recognition and processing tasks. It consists of various levels, encompassing convolutional layers, pooling layers, and fully connected layers. There are different types of CNN models used in deepfake detection such as ResNet [44][93], short for Residual Network, which is an architecture that introduces skip connections to fix the vanishing gradient problem that occurs when the gradient diminishes significantly during backpropagation; these connections involve stacking identity mappings and skipping them, utilizing the layer’s prior activations. This technique accelerates first training by reducing the number of layers in the network. The concept underlying this network is different from having the layers learn the fundamental mapping.
Furthermore, data augmentation plays a crucial role in training deep learning-based detection models. This technique involves augmenting the training dataset with synthetic or modified samples, which enhances the model’s capacity to generalize and recognize diverse variations of deepfake media. Data augmentation enables the model to learn from a wider range of examples and improves its robustness against different types of manipulations. Attention mechanisms have also proven to be valuable additions to deep learning-based detection models. By directing the model’s focus toward relevant features and regions of the input data, attention mechanisms enhance the model’s discriminative power and improve its overall accuracy. These mechanisms help the model select critical details [43][92], making it more effective in distinguishing between real and fake media. Collectively, the combination of deep learning-based architectures, meta-learning, data augmentation, and attention mechanisms has significantly advanced the field of deepfake detection. These technologies work in harmony to equip models with the ability to identify and flag manipulated media with unprecedented accuracy.
The Convolutional Neural Network is a powerful deep learning algorithm designed for image recognition and processing tasks. It consists of various levels, encompassing convolutional layers, pooling layers, and fully connected layers. There are different types of CNN models used in deepfake detection such as ResNet [44][93], short for Residual Network, which is an architecture that introduces skip connections to fix the vanishing gradient problem that occurs when the gradient diminishes significantly during backpropagation; these connections involve stacking identity mappings and skipping them, utilizing the layer’s prior activations. This technique accelerates first training by reducing the number of layers in the network. The concept underlying this network is different from having the layers learn the fundamental mapping.
4.1.2. Detection Based on Biological/Physiological Signs
Li, Y. et al. [24][59] adopted an approach based on identifying eye blinking, a biological signal that is not easily conveyed in deepfake videos. Therefore, a deepfake video can be identified by the absence of eye blinking. To spot open and closed eye states, a deep neural network model that blends CNN and a recursive neural network is used while taking into account previous temporal knowledge.34.1.3. Detection Based on Audio-Visual Inconsistencies
Boundary Aware Temporal Forgery Detection is a multimodal technique introduced by Cai et al. [25][61] for correctly predicting the borders of fake segments based on visual and auditory input. While an audio encoder using a 2DCNN learns characteristics extracted from the audio, a video encoder leveraging a 3DCNN learns frame-level spatial-temporal information.34.1.4. Detection Based on Convolutional Traces
To detect deepfakes, Huang et al. [26][64] harnessed the imperfection of the up-sampling process in GAN-generated deepfakes by employing a map of gray-scale fakeness. Furthermore, attention mechanism, augmentation of partial data, and clustering of individual samples are employed to improve the model’s robustness. Chen et al. [27][65] exploited a different trace which is bi-granularity artifacts, intrinsic-granularity artifacts that are caused by up-convolution or up-sampling operations, and extrinsic granularity artifacts that are the result of the post-processing step that blends the synthesized face to the original video. Deepfake detection is tackled as a multi-task learning problem where ResNet-18 is used as the backbone feature extractor.34.1.5. Detection Based on Identity Information
Based on the intuition that every person can exhibit distinct patterns in the simultaneous occurrence of their speech, facial expressions, and gestures, Agarwal et al. [28][70] introduced a multimodal detection method with a semantic focus that incorporates speech transcripts into gestures specific to individuals analysis using interpretable action units to model facial and cranial motion of an individual. Meanwhile, Dong et al. [29][71] proposed an Identity Consistency Transformer that learns simultaneously and identifies vectors for the inner face and another for the outer face; moreover, the model uses a novel consistency loss to drive both identities apart when their labels are different and to bring them closer when their labels are the same.34.1.6. Detection Based on Facial Emotions
Despite the fact that deepfakes can produce convincing audio and video, it can be difficult to produce material that maintains coherence concerning high-level semantics, including emotions. Unnatural displays of emotion, as determined by characteristics like valence and arousal, where arousal indicates either heightened excitement or tranquility and valence represents positivity or negativity of the emotional state, can offer compelling proof that a video has been artificially created. Using the emotion inferred from the visage and vocalizations of the speaker, Hosler et al. [30][74] introduced an approach for identifying deepfakes. The suggested method makes use of long, short-term memory networks and visual descriptors to infer emotion from low-level audio emotion; a supervised classifier is then incorporated to categorize videos as real or fake using the predicted emotion.34.1.7. Detection Based on Temporal Inconsistencies
To leverage temporal coherence to detect deepfakes, Zheng et al. [31][76] proposed an approach to reduce the spatial convolution kernel size to 1 while keeping the temporal convolution kernel size constant using a fully temporal convolution network in addition to a Transformer Network that explores the long-term temporal coherence. Pei et al. [32][77] exploited the temporal information in videos by incorporating a Bidirectional-LSTM model.34.1.8. Detection Based on Spatial-Temporal Features
The forced mixing of the manipulated face in the generation process of deepfakes causes spatial distortions and temporal inconsistencies in crucial facial regions, which Sun et al. [33][80] proposed to reveal by extracting the displacement trajectory of the facial region. For the purpose of detecting fake trajectories, a fake trajectory detection network, utilizing a gated recurrent unit backbone in conjunction with a dual-stream spatial-temporal graph attention mechanism, is created. In order to detect the spatial-temporal abnormalities in the altered video trajectory, the network makes use of the extracted trajectory and explicitly integrates the important data from the input sequences.3.2. Deep Learning Models for Deepfake Detection
4.2. Deep Learning Models for Deepfake Detection
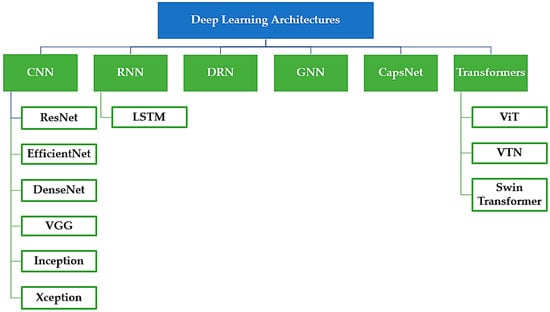
Several advanced technologies have been employed in the domain of deepfake detection, such as machine learning [34][35][36][83,84,85] and media forensics-based approaches [37][86]. However, it is widely acknowledged that deep learning-based models currently exhibit the most remarkable performance in discerning between fabricated and authentic digital media. These models leverage sophisticated neural network architectures known as backbone networks, displayed in Figure 3, which have demonstrated exceptional efficacy in computer vision tasks. Prominent examples of such architectures include VGG [38][87], EfficientNet [39][88], Inception [40][89], CapsNet [41][90], and ViT [42][91], and are particularly renowned for their prowess in the feature extraction phase. Deep learning-based detection models go beyond conventional methods by incorporating additional techniques to further enhance their performance. One such approach is meta-learning, which enables the model to learn from previous experiences and adapt its detection capabilities accordingly. By leveraging meta-learning, these models become more proficient at recognizing patterns and distinguishing between genuine and manipulated content.Figure 3. Overview of predominant deep learning architectures, networks, and frameworks employed in the development of deepfake detection models.
45. Datasets
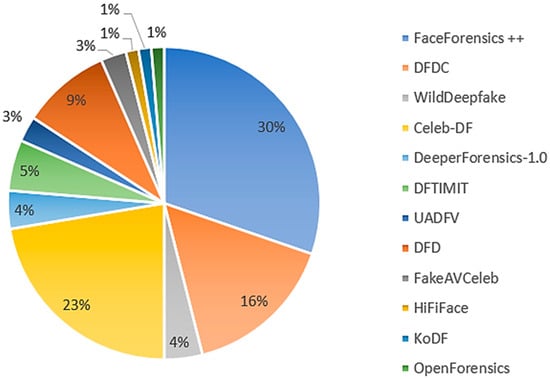
In the context of deepfakes, datasets serve as the foundation for training, testing, and benchmarking deep learning models. The accessibility of reliable and diverse datasets plays a crucial role in the development and evaluation of deepfake techniques. A variety of important datasets, summarized in Table 13, have been curated specifically for deepfake research, each addressing different aspects of the problem and contributing to the advancement of the field. Figure 46 shows some of the widely used datasets in deepfake detection models’ improvement.Figure 46.
Frequency of usage of different deepfake datasets in the discussed detection models within this survey.
Table 13.
Key characteristics of the most prominent and publicly available deepfake datasets.
| Dataset | Year Released |
Real Content |
Fake Content |
Generation Method | Modality |
|---|---|---|---|---|---|
| FaceForensics ++ [45][118] | 2019 | 1000 | 4000 | DeepFakes [46][119], Face2Face2 [47][37], FaceSwap [48][120], NeuralTextures [49][121], FaceShifter [8][34] | Visual |
| Celeb-DF (v2) [50][122] | 2020 | 590 | 5639 | DeepFake [50][122] | Visual |
| DFDC [51][123] | 2020 | 23,654 | 104,500 | DFAE, MM/NN, FaceSwap [48][120], NTH [52][124], FSGAN [53][125] | Audio/Visual |
| DeeperForensics-1.0 [54][126] | 2020 | 48,475 | 11,000 | DF-VAE [54][126] | Visual |
| WildDeepfake [55][127] | 2020 | 3805 | 3509 | Curated online | Visual |
| OpenForensics [56][128] | 2021 | 45,473 | 70,325 | GAN based | Visual |
| KoDF [57][129] | 2021 | 62,166 | 175,776 | FaceSwap [48][120], DeepFaceLab [20][51], FSGAN [53][125], FOMM [58][130], ATFHP [59][131], Wav2Lip [60][132] | Visual |
| FakeAVCeleb [61][133] | 2021 | 500 | 19,500 | FaceSwap [48][120], FSGAN [53][125], SV2TTS [62][134], Wav2Lip [60][132] | Audio/Visual |
| DeepfakeTIMIT [63][135] | 2018 | 640 | 320 | GAN based | Audio/Visual |
| UADFV [64][136] | 2018 | 49 | 49 | DeepFakes [46][119] | Visual |
| DFD [65][137] | 2019 | 360 | 3000 | DeepFakes [46][119] | Visual |
| HiFiFace [66][138] | 2021 | - | 1000 | HifiFace [66][138] | Visual |
56. Challenges
Although deepfake detection has improved significantly, there are still a number of problems with the current detection algorithms that need to be resolved. The most significant challenge would be real-time detection of deepfakes and the implementation of detection models in diverse sectors and across multiple platforms. A challenge difficult to surmount due to several complexities, such as the computational power needed to detect deepfakes in real-time considering the massive amount of data shared every second on the internet and the necessity that these detection models be effective and have almost no instances of false positives. To attain this objective, one can leverage advanced learning techniques, such as meta-learning and metric learning, employ efficient architectures like transformers, apply compression techniques such as quantization, and make strategic investments in robust software and hardware infrastructure foundations.
In addition, detection methods encounter challenges intrinsic to deep learning, including concerns about generalization and robustness. Deepfake content frequently circulates across social media platforms after undergoing significant alterations like compression and the addition of noise. Consequently, employing detection models in real-world scenarios might yield limited effectiveness. To address this problem, several approaches have been explored to strengthen the generalization and robustness of detection models, such as feature restoration, attention guided modules, adversarial learning and data augmentation. Additionally, when it comes to deepfakes, the lack of interpretability of deep learning models becomes particularly problematic, making it challenging to directly grasp how they arrive at their decisions. This lack of transparency can be concerning, especially in critical applications, such as forensics, where understanding the reasoning behind a model’s output is important for accountability, trust, and safety. Furthermore, since private data access may be necessary, detection methods raise privacy issues.
The quality of the deepfake datasets is yet another prominent challenge in deepfake detection. The development of deepfake detection techniques is made possible by the availability of large-scale datasets of deepfakes. The content in the available datasets, however, has some noticeable visual differences from the deepfakes that are actually being shared online. Researchers and technology companies such as Google and Facebook constantly put forth datasets and benchmarks to improve the field of deepfake detection. A further threat faced by detection models is adversarial perturbations that can successfully deceive deepfake detectors. These perturbations are strategically designed to exploit vulnerabilities or weaknesses in the underlying algorithms used by deepfake detectors. By introducing subtle modifications to the visual or audio components of a deepfake, adversarial perturbations can effectively trick the detectors into misclassifying the manipulated media as real.
Deepfake detection algorithms, although crucial, cannot be considered the be-all end-all solution in the ongoing battle against the threat they pose. Recognizing this, numerous approaches have emerged within the field of deepfakes that aim to not only identify these manipulated media but also provide effective means to mitigate and defend against them. These multifaceted approaches serve the purpose of not only detecting deepfakes but also hindering their creation and curbing their rapid dissemination across various platforms. One prominent avenue of exploration in combating deepfakes involves the incorporation of adversarial perturbations to obstruct the creation of deepfakes. An alternative method involves employing digital watermarking, which discreetly embeds data or signatures within digital content to safeguard its integrity and authenticity. Additionally, blockchain technology offers a similar solution by generating a digital signature for the content and storing it on the blockchain, enabling the verification of any alterations or manipulations to the content.