The relevance of genetics in cardiovascular diseases has expanded, especially in the context of cardiomyopathies. Its relevance extends to the management of patients diagnosed with heart failure (HF), given its capacity to provide invaluable insights into the etiology of cardiomyopathies and identify individuals at a heightened risk of poor outcomes. Notably, the identification of an etiological genetic variant necessitates a comprehensive evaluation of the family lineage of the affected patients. In the future, these genetic variants hold potential as therapeutic targets with the capability to modify gene expression.
- heart failure
- genetics
- diagnosis
- prognosis
- therapy
1. Introduction
2. Advancements and Applications of Genetics in Cardiovascular Disease
2.1. Assessment of Pathogenic Genetic Variants
Every individual possesses variants within their genome, ranging from single nucleotide substitutions (single nucleotide variants [SNVs] or single nucleotide polymorphisms [SNPs]) [7][8][26,27] to duplications or deletions spanning entire chromosomes. On average, each person carries about 100 de novo SNVs that emerge during their development [8][27]. Given that protein-coding regions make up roughly 1% of the genome, but contain 85% of disease-causing variants, targeted sequencing frequently focuses on these areas [9][28]. Predominant approaches include sequencing the protein-coding regions of the roughly 20,000 known genes, termed whole-exome sequencing (WES) [10][29] or focusing on a select set of genes associated with a specific clinical condition, often called a “gene panel” (typically focusing on exons only) [11][30]. These techniques can identify minor variants, such as SNVs and minor insertions and deletions. However, the identification of larger and more intricate variants, such as the complete deletion of an exon or complex genomic rearrangements, can be more challenging [12][13][31,32]. The Sanger sequencing technique has been widely used since 1977 for direct sequencing of specific genes. It also serves to validate mutations detected by alternate sequencing approaches and is pivotal in genetic investigations, particularly when a mutated gene is already identified within a family lineage [10][14][29,33]. With the advent of next-generation sequencing (NGS) techniques [15][34] in the early 2000s [16][17][35,36], there has been a shift toward methods that bolster sequencing for increased parallelism and scalability. Presently, high-throughput sequencing stands as the predominant method in many diagnostic contexts [18][19][37,38]. NGS techniques are adept at detecting small variants, including SNVs and minor insertions and deletions. These techniques comprise the following:-
TGP (targeted gene panel): this method examines genes linked to a specific phenotype. However, its scope is primarily confined to selected genes known for their variants, necessitating ongoing updates. The process entails designing a gene panel correlated with a distinct disease and conducting parallel sequencing. It is commonly employed as the primary diagnostic test for probands [12][20][31,39].
-
WES: this method is adept at diagnosing probands presenting with diverse disorders, including pediatric and syndromic cardiomyopathies. It encompasses all genes with the objective of sequencing the complete exome. Through an integrated process, data corresponding to the entire exome can be produced, eliminating the need for additional analyses when updated information becomes available [21][22][40,41].
-
Whole-genome sequencing (WGS): this technique sequences the complete genome, offering diagnostic insights for probands with varied disorders and detailed data on pharmacokinetic variants. While comprehensive, WGS comes with a greater expense and necessitates intricate data analysis. If panel sequencing yields negative results, both WES and WGS stand as viable subsequent diagnostic options [23][42].
2.1.1. Sequencing Modalities
The analytical process begins with the collection of a small sample of peripheral blood or saliva from the patient. At times, samples from parents or close family members may also be required. The DNA essential for sequencing is then extracted from this sample. Upon acquiring the sequences, they undergo analysis and interpretation based on the most current genetic data in the international medical-scientific literature, focusing on the relevant diseases or symptoms. Identified pathological variants are subsequently validated in the original sample using alternative technological methods. In the context of targeted NGS (targeted gene panel, TGP), the assessment of diseases with pronounced genetic heterogeneity and recognized genes is undertaken using designated panels. These panels are of two main types:-
Presequencing panels (targeted resequencing): this approach enables the simultaneous analysis of multiple patients by selectively enriching specific genomic regions prior to sequencing.
- -
-
Cost: The difference in cost is influenced by the reagents used. The use of TGP is more economical if the number of samples per run is optimized. In economic terms, WGS is the most expensive, and although WES is pricier than panels, it can be advantageous depending on the type of study to be performed [27][46].
- -
-
Purpose: Typically, NGS techniques are employed for diseases with high genetic heterogeneity or Mendelian-based genetic diseases (or those suspected to be genetic) where the causative genes remain unidentified. For diseases with established genetic etiology, either custom-designed panels, WES, or WGS can be utilized [26][45].
- -
-
Sensitivity: Sensitivity largely depends on the coverage of the sequences under investigation, that is, the number of reads for specific DNA sections and the overlap extent between these reads. A greater number of reads for a specific region translates to higher sensitivity for that DNA segment [26][45]. During panel analysis, a reduced genome proportion under investigation leads to enhanced coverage and sensitivity. Thus, if a disease is believed to result from a mosaic genomic alteration, NGS panel analysis offers higher sensitivity compared to WES.
- -
-
IFs and VUSs: The probability of identifying IFs and VUSs depends on the genome proportion both analyzed and queried. Analysis based on panels has a reduced association with IFs, since the investigated sequences are directly relevant to the clinical presentation of the proband. In general, a broader sequence analysis correlates with a higher number of IFs and VUSs.
- -
-
Data storage: The extent of the genome analyzed directly influences the volume of data generated. Consequently, suitable platforms for data storage are essential, particularly for analyses yielding substantial data, such as those conducted via WES and, more prominently, WGS [26][45].
2.1.2. Identification and Interpretation of Pathogenic Genetic Variants in Clinical Diagnostics
Various software tools, including Bowtie2, BWA, MAQ, and SOAP2, assist in mapping a patient’s sequences to reference sequences found in databases. Through this method, the patient’s exome is aligned, signifying the alignment phase. After successful alignment, sequence variants can be detected, representing all deviations from the human reference sequence for each gene. This process is known as “variant calling”, an operation that is automated within NGS analysis. Upon detecting approximately 140,000 genetic variants in an individual (a figure representative of the average number derived from WES) through the previously mentioned variant calling operation, it becomes essential to determine their clinical significance. These variants are characterized based on the following:-
Their allele frequency within the general population;
2.2. Variants of Uncertain Significance (VUS)
A mutation denotes a permanent alteration in the nucleotide sequence, whereas a polymorphism represents a variant with a frequency exceeding 1% in the population. Both terms are now more commonly referred to as “variant”, further defined with specific qualifiers such as “pathogenic”, “likely pathogenic”, “uncertain significance”, “likely benign”, or “benign”. Some laboratories may incorporate additional levels, particularly for internal use, such as subclassifying VUSs. The designations “likely pathogenic” and “likely benign” imply a confidence level greater than 90% that the variant is, respectively, pathogenic or benign. Importantly, at present, there is no robust data that provides a quantitative assignment of variant certainty to any of the five categories, largely due to the varied nature of many diseases. VUSs are typically overlooked in clinical decision-making, as further information is required to categorize them definitively as either pathogenic or benign. However, the presence of uncertain sarcomere mutations or multiple VUSs in patients with hypertrophic cardiomyopathy (HCM) has been correlated with earlier disease onset and more severe outcomes. Therefore, a deeper understanding of these VUSs becomes imperative for optimized clinical management and better patient outcomes [34][53].CardioBoost uses a disease-specific variant classifier algorithm tailored to predict the pathogenicity of missense variants linked to inherited cardiomyopathies and arrhythmias. One of its distinct advantages is that, when focused on heart disease, this specific variant classifier surpasses the performance of leading whole-genome tools. This superiority underscores the significant potential for improved pathogenicity predictions through disease-specific approaches [35][55]. On the other hand, some tools harness detailed structural information about proteins, examining how mutations might affect protein folding and stability to make their pathogenicity predictions [34][53].
2.3. Classification, Implications, and Clinical Utility of Genetic Variants in Cardiovascular Disease
When a genetic variant correlates with an observed phenotype, laboratories typically categorize it using a five-tier system. If strong evidence supports the variant’s causative role in the condition, it will be labeled as either “pathogenic” or “likely pathogenic”. Conversely, if robust evidence suggests that the variant is not the causative agent for the disease, it will be termed “benign” or “likely benign”. In instances where the evidence is either conflicting or not conclusive, the variant is designated as having “uncertain significance”, often abbreviated as “VUS”. It is crucial to note that VUSs should not be used for cascade testing, and rarely hold clinical significance for the proband [36][57]. Upon identification of a pathogenic or likely pathogenic variant, initiating clinical evaluations and cascade genetic testing for family members is recommended. Family members who test positive for the variant should undergo long-term monitoring, especially if they exhibit the clinical phenotype. In contrast, family members who do not have the variant can generally be exempted from further genetic investigations [37][38][22,58]. In cases where a VUS is identified, supplementary analyses, such as segregation studies and, where feasible, functional studies, should be conducted. Decisions regarding genetic testing and clinical screenings for family members are based on the findings from these analyses. Equally significant, re-evaluation of other potential causes of the disease is warranted when a genetic variant is absent or a genetic test is inconclusive. Clinical screenings of family members should also be considered. PRSs, also known as GRSs, are becoming increasingly relevant in the evaluation of multiple genetic variants [39][60]. These scores consider variants across the genome, each contributing a small amount to disease risk, to compute a cumulative risk score. However, the definitive clinical utility of PRSs in the management of cardiomyopathies remains to be established [40][41][42][43][61,62,63,64]. In the contemporary medical landscape, identifying a genetic variant or assessing an individual’s susceptibility to genetic diseases equates to equipping the patient or their family with a genetic profile (genotype). This profile subsequently stratifies risk considering the identified genetic variant, related diseases, coexisting health conditions, and resultant manifestations (phenotype). Such stratifications can indicate events such as SCD or the onset of clinically evident HF. Furthermore, this genetic “identity card” can dictate whether a patient receives a recommendation for an implantable cardioverter-defibrillator (ICD) insertion, along with all the consequential implications it entails [44][65].2.4. Diagnosis and Counseling
Incorporating genetics into the care regimen for these patients necessitates a structured follow-up and extended surveillance, both for the proband (the initial patient diagnosed with the condition) and their family. This approach not only fosters a more profound comprehension of the disease, but also paves the way for specific and individualized treatments, thereby enhancing both the patient’s prognosis and their clinical management. When diagnosing a patient with cardiomyopathy through genetic testing, the scope extends beyond merely identifying the patient’s present condition. It encompasses continuous genetic assessments for family members and the initiation of a broad counseling framework for both the patient and their family [45][46][47][66,67,68]. For those diagnosed with cardiomyopathy, the genetic trajectory, both for the proband and their relatives, invariably begins with genetic counseling. This step is pivotal, as grappling with an inherited cardiomyopathy can present numerous challenges. Genetic counseling, conducted by healthcare professionals with specific training, strives to assist patients and their families in comprehending and adjusting to the medical, psychosocial, and familial consequences of genetic diseases. It encompasses a range of topics, including understanding inheritance risks, educational sessions on genetic diseases, guidance during genetic testing processes, interpreting genetic variant results, compiling a comprehensive three-generation family medical history, and offering psychosocial support to patients and their families [48][69]. Addressing the communication strategy with family members is a critical component of genetic counseling. The index patient, often referred to as the proband, might choose not to inform at-risk relatives about the inherited condition and the availability of family screening for a variety of reasons [49][50][51][70,71,72]. This situation is concerning, especially given the severe complications and risk of SCD associated with many inherited cardiac conditions. Since many inherited cardiomyopathies exhibit an autosomal dominant inheritance pattern, it is essential to emphasize the importance of both clinical and genetic testing for immediate family members.2.5. Gene Therapy
Gene therapy is a prominent strategy within advanced therapies. At its core, it aims to address the root cause of a disease by providing affected cells with a functional version of a gene. Methods of gene editing include RNA therapy, CRISPR/Cas9 techniques, antisense therapies, and the introduction of innovative drugs [52][73], as summarized in Figure 1. While many clinical phenotypes primarily rely on generic and symptomatic medications, treatments that focus on the underlying cause and offer targeted interventions (specifically, etiology-based and precision therapies) are still in their developmental stages.Research on inherited cardiomyopathies has encountered obstacles due to the lack of suitable in vitro human cardiac cell or tissue models, especially those that replicate patient-specific anomalies. A promising solution is the generation of human-induced pluripotent stem cell-derived cardiomyocytes (hiPSC-CMs) that are tailored to individual patients [52][73]. Specialized models of hiPSC-CMs, designed to match specific patients or diseases, have been developed, encompassing mutations in genes encoding cardiac sarcomeric and cytoskeletal proteins, ion channels, nuclear proteins, mitochondrial proteins, and lysosomal proteins. The integration of hiPSC-CM technology with genome-editing methods such as the CRISPR/Cas9 system has yielded deeper insights into the genetic origins of diverse cardiomyopathies, leading to the creation of isogenic control lines [53][74]. Transitioning from a cellular perspective to three-dimensional engineered heart tissues, made possible by integrating polymer-based scaffolds with hiPSC-CMs, offers more clinically relevant models for cardiomyopathy studies [54][55][75,76].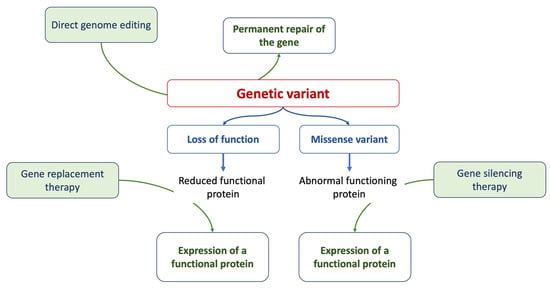 Figure 1.The figure summarizes the current approaches of gene therapy.
Figure 1.The figure summarizes the current approaches of gene therapy.3. Genetics, Cardiomyopathies, and Heart Failure
3.1. Genetic Factors Predisposing to Heart Failure
In patients with cardiomyopathy and those with a genetic variant (i.e., carrier), it is crucial to identify those at an elevated risk of developing HF. The proportion of patients possessing a genetic variant linked to cardiomyopathies who eventually develop HF can differ substantially. This variability can be attributed to multiple factors, including the specific genetic variant in question, its severity, the patient’s family history, age, and other individual risk determinants [56][100]. At present, there are no well-established and scientifically validated multiparametric risk scores that can precisely predict which patients will manifest HF. Nevertheless, a comprehensive evaluation of individual risk should incorporate several parameters. In this context, family history and genetic information can be instrumental in identifying heightened risk. It is well-established that having a first-degree relative with HF augments the risk relative to the broader population [56][57][100,109]. This familial predisposition could potentially stem from shared genetic variants. Various genetic variants have been associated with different types of cardiomyopathies, which can significantly influence the course and outcome of the disease. For example, in DCM, there is evidence that patients with TTN truncation variants might be more susceptible to developing HF when exposed to stressors such as alcohol, pregnancy, or cardiotoxic drugs. Furthermore, those with DCM who carry sarcomeric rare variants or RNA-binding motif protein 20 (RBM20) variants generally experience a more rapid disease progression, sometimes leading to the necessity for interventions such as heart transplantation. Variations in the LMNA gene can have diverse effects on cardiomyocyte structure and function. In the context of HCM, a large multicenter cohort study has shown that a sarcomere mutation is associated with an earlier onset of the disease and serves as a strong predictor of unfavorable clinical outcomes, including the occurrence of VAs and HF [58][111]. The MYH7 gene is a significant genetic factor responsible for encoding the β-myosin heavy-chain (β-MHC) subunit of cardiac myosin. Alterations in this myosin directly influence myocardial mechanical function, contributing to impaired myocardial performance that can result in HF [59][112]. Individuals carrying MYBPC3 missense VUSs demonstrate an elevated incidence of adverse clinical outcomes. These outcomes include VAs, HF, all-cause mortality, atrial fibrillation, and stroke, similar to those with pathogenic MYBPC3 variants [60][113]. Evidence indicates that patients with MYH7 gene mutations present with more severe disease manifestations compared to those with MYBPC3 mutations [61][114]. Moreover, patients harboring MYH7 or MYBPC3 mutations also face a heightened risk of SCD [62][115]. In the context of ARVC, it has been observed that patients with mutations in the DSP, desmocollin-2 (DSC2), and DSG2 genes more commonly exhibit a diminished left ventricular ejection fraction (LVEF) of ≤45% on cardiac magnetic resonance (CMR) imaging in comparison to those with PKP2-related ARVC (27% vs. 4%, p < 0.01) [63][116].3.2. Genetics in Assessing the Risk of Heart Failure Progression
Genetics can be pivotal in guiding the clinical management of patients diagnosed with cardiomyopathy, especially those with established HF. Understanding both the patient’s clinical phenotype and genetic background provides the HF specialist with a unique profile (genotype) for that specific patient, enabling more accurate predictions regarding disease progression and outcomes. Currently, there are no predefined and scientifically validated multiparametric risk scores that can accurately project which patients will develop HF or experience clinical deterioration [56][57][100,109]. Nonetheless, certain genetic variants have been linked to a heightened risk of malignant VAs and progression to advanced HF [4][64][4,110]. Routine clinical evaluations, complemented by echocardiography or CMR every 1–2 years and cardiopulmonary exercise testing every 2–3 years, serve as reliable tools to detect early indicators of disease progression. In this context, timely clinical evaluation and preventive strategies are of paramount importance. Leveraging genetic insights allows for enhanced risk stratification in patients with cardiomyopathy [65][122].3.3. Arrhythmic Risk Stratification
In individuals with cardiomyopathies, atrial fibrillation stands out as the most prevalent arrhythmia across all phenotypes. This condition is linked to an elevated risk of HF, cardioembolic events, and increased mortality. The primary concern for clinicians, however, is managing the risk of VAs leading to SCD, as well as sustained VAs and electrical storms [66][123]. Indeed, while the implantation of an ICD is advocated for secondary prevention, determining its use in patients who have not yet experienced sustained symptomatic VAs remains a complex clinical decision. In DCM, individuals carrying pathogenic variants such as DSP, LMNA, PLN, folliculin (FLCN), TMEM43, and RBM20 demonstrate an increased incidence of notable arrhythmic events [67][68][124,125]. This elevated risk is observed irrespective of their LVEF, and these patients also tend to follow a more challenging clinical trajectory compared to DCM patients not carrying these specific genetic variants. Genes associated with an increased risk of arrhythmias include those encoding nuclear envelope proteins (TMEM43, LMNA, and emerin [EMD]), as well as cytoskeletal and desmosomal proteins (PKP2, DSP, DSC2, and DSG2) [65][122]. Patients with DCM-causing variants in these high-risk genes should be viewed as having a pronounced genetic predisposition to SCD. The decision to implant an ICD for primary prevention in those with LMNA-related cardiomyopathies might be informed by the LMNA-risk ventricular tachyarrhythmia (VTA) calculator, which evaluates the risk of experiencing a life-threatening VTA within a 5-year period [65][122]. This calculator provides a more nuanced risk assessment compared to the prevailing standard of care [4], which identifies high risk based on the presence of ≥2 of the following factors: male gender, non-missense mutations, nonsustained ventricular tachycardia, and an LVEF of ≤45%. In individuals without a high-risk genotype and an LVEF ≥ 35%, the use of LGE on CMR imaging becomes an essential tool for risk assessment [69][127]. It is recommended that genetic testing, encompassing at least the PLN, LMNA, FLNC, and RBM20 genes, be conducted for patients with DCM and atrioventricular (AV) conduction delay before the age of 50, or if a family history of SCD in a first-degree relative is present [65][122]. For DCM patients carrying a pathogenic LMNA gene mutation, considering the placement of an ICD for primary prevention is essential, particularly if the projected 5-year risk of encountering life-threatening VA is ≥10%. This consideration is heightened when the coexistence of nonsustained ventricular tachycardia (NSVT) with an LVEF of ≤50% or an AV conduction delay is observed [65][70][122,128]. MYH7-related dilated cardiomyopathy (MYH7-DCM) is characterized by an early onset, pronounced phenotypic manifestation, limited left ventricular reverse remodeling, and a frequent progression to end-stage HF (ESHF). Complications related to HF are more common than the occasional VAs [71][129]. In HCM, NSVT identified during extended (24/48 h) ambulatory electrocardiogram (ECG) monitoring, particularly in individuals below 30 years of age and those who experience NSVT during physical exertion, is significantly associated with an increased risk of SCD [72][130].
3.4. Implications of Genetic Variants in Clinical Decisions
As previously mentioned, determining the genetic variants within a patient through genetic testing provides a distinctive “identity card”, revealing potential clinical phenotypic traits of the individual. Such characteristics might predispose them to malignant VAs, potential SCD, and the initiation and progression of HF symptoms. ndividuals harboring mutations in genes such as DSP, LMNA, PLN, FLCN, RBM20, and TMEM43 are more susceptible to significant arrhythmic events, irrespective of their LVEF, and tend to follow a more challenging clinical trajectory than those with DCM who are genotype-negative. Specifically, a patient with a mutation in the LMNA gene faces an elevated risk of SCD. As a result, the criteria for ICD implantation for these individuals will be more stringent compared to those without such a mutation, but who are still at high risk for SCD. Consequently, patients in this category should consider ICD implantation as a precaution, even when their LVEF is above 35% [4][65][4,122]. Recognizing one’s genetic profile and inherent predispositions will gain paramount importance in the future, as numerous scientific studies have already highlighted. For instance, in peripartum cardiomyopathy, which was historically viewed as an environmental condition, there is a notable prevalence of truncating variants in genes associated with DCM. Thus, it becomes essential to embrace the idea of individual genetic predispositions. This suggests that specific genetic variants might have a direct correlation with either favorable or unfavorable outcomes. This is even applicable to less prevalent cardiomyopathies, where previously only external or secondary causes were considered as potential etiologies [73][138].4. Heart Failure and Genetics
HF emerges as a multifaceted outcome shaped by the interplay of genetic, acquired, and environmental dimensions. Common genetic variants can precipitate its onset, suggesting that these variants, in conjunction with environmental factors, amplify the susceptibility to HF. Empirical evidence robustly underscores the hereditary dimensions of HF. The Framingham database [74][75][139,140], for instance, revealed a marked 70% increase in the likelihood of HF development in individuals with a family history of the condition. Nonetheless, it is pivotal to recognize that numerous cases are also influenced by lifestyle and external environmental determinants. The trajectory of HF evolution is determined by individual predispositions coupled with the intrinsic factors of accompanying comorbidities. Genetic predispositions can influence susceptibility to the initial event that triggers HF, dictate the progression post-onset, and modulate the efficacy of therapeutic strategies [76][141]. Figure 2 summarizes the complexity of the influence of genetic background observed in HF patients.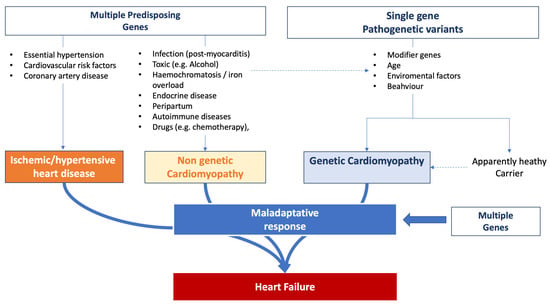 Figure 2.Influence of genetic background on heart failure onset and progression.
Figure 2.Influence of genetic background on heart failure onset and progression.