Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Shuai Li and Version 3 by Rita Xu.
Semantic segmentation of large-scale indoor 3D point cloud scenes is crucial for scene understanding but faces challenges in effectively modeling long-range dependencies and multi-scale features. ResearchersA present RegionPVT, a nonovel Regional-to-Local Point-Voxel Transformer that synergistically integrates voxel-based regional self-attention and window-based point-voxel self-attention was proposed for concurrent coarse-grained and fine-grained feature learning. The voxel-based regional branch focuses on capturing regional context and facilitating inter-window communication. The window-based point-voxel branch concentrates on local feature learning while integrating voxel-level information within each window.
- point cloud
- semantic segmentation
- regional-to-local
1. Introduction
Semantic segmentation of large-scale point cloud scenes is a crucial task in 3D computer vision, serving as the core capability for machines to comprehend the 3D world. It has found extensive applications in autonomous driving [1][2][1,2], robotics [3][4][3,4], and augmented reality [5][6][5,6]. In particular, deep learning has made striking breakthroughs in computer vision over the past few years. Enabling reliable semantic parsing of point cloud data using deep neural networks has become an emerging hot research direction and attracted wide interest [7]. Unlike 2D images, 3D point clouds are intrinsically sparse and irregularly scattered in a continuous 3D space. They are unstructured in nature and often at a massive scale. These unique properties impose difficulties in directly adopting convolution operations, which have been the mainstay for 2D image analysis [8][9][8,9]. In recent years, convolutional networks (CNNs) [10][11][12][10,11,12] and Transformer [13][14][15][13,14,15] architectures have led to striking advances in semantic parsing of 2D visual data. However, efficiently learning discriminative representations from disordered 3D point sets using deep neural networks, especially at large-scale indoor scenes, remains a challenging open problem.
Abundant methods have explored the comprehension of 3D point clouds and obtained decent performance. In order to leverage convolutional neural networks (CNNs) for point cloud analysis, one category of approaches [16][17][18][19][16,17,18,19] first transforms the 3D points into discrete representations such as voxels, before applying CNN models to extract high-dimensional features. Another line of work [9][20][21][22][23][9,20,21,22,23], pioneered by PointNet [8], directly processes points in the native continuous space. Through alternating steps of grouping and aggregation, PointNet-style models are able to capture multi-scale contextual information from unordered 3D point sets. However, most of these existing methods concentrate on aggregating local feature representations but do not explicitly model long-range dependencies, which have been shown to be vital for capturing contextual information from distant spatial locations [24].
Transformers [25] based on self-attention come naturally with the ability to model long-range dependencies, and the permutation and cardinality invariance of self-attention in Transformers make them inherently suitable for point cloud processing. Recently, inspired by the transformer’s remarkable success [13][14][15][26][27][28][13,14,15,26,27,28] in the 2D image domain, a number of studies [29][30][31][32][29,30,31,32] have investigated adapting Transformer architectures to process unstructured 3D point sets. Engel et al. [29] proposed a kind of point transformer algorithm, which incorporates standard self-attention to extract global features for capturing point relationships and shape information in the 3D space. Guo et al. [31] presented offset-attention that computes the offset difference between self-attention features and input features in an element-wise manner. Concurrently, a spectrum of scholars have explored embedding self-attention modules in diverse point cloud tasks, witnessing noteworthy successes as showcased in works like [30][33][30,33]. Despite the promising advancements in point cloud transformers, a clear limitation persists. These models need to generate expansive attention maps due to the use of conventional self-attention mechanisms, placing a high computational complexity (quadratic) and consuming a huge number of GPU memory. This methodology, while rigorous, becomes implausible when scaling up to expansive 3D point cloud datasets, thereby hindering large-scale modeling pursuits.
Furthermore, in an effort to aggregate localized neighborhood information from point clouds, Zhao et al. [30] introduced another kind of point transformer algorithm, which establishes local vector attention within neighboring point sets. Guo et al. [31] proposed the use of neighbor embedding strategies to enhance point embedding. The PointSwin, as presented by Jiang et al. [34], employs self-attention based on a sliding window to capture local details from point clouds. While the two point transformers, PCT and the PointSwin, have achieved significant advancements, certain challenges continue to hinder their efficiency and performance. These methods fall short of establishing attention across features of different scales, which is crucial for 3D visual tasks [35]. For instance, a large indoor scene often encompasses both smaller instances (such as chairs and lamps) and larger objects (like tables). Recognizing and understanding the relationships between these entities necessitates a multi-scale attention mechanism. Moreover, when delving into large-scale scene point clouds, an optimal blend of both coarse-grained and fine-grained features becomes pivotal [36]. Coarse-grained features present a bird’s eye view, providing a general overview of the scene, whereas fine-grained ones are key in identifying and interpreting small details. Integrating both these feature dimensions can significantly amplify the potential and accuracy of point cloud semantic segmentation, particularly in heterogeneous and complex scenarios.
In addressing the challenges discussed previously, reswearchers present a novel dual-branch block named the Regional-to-Local Point-Voxel Transformer Block (R2L Point-Voxel Transformer Block), specifically engineered for the semantic segmentation of large-scale indoor point cloud scenes. This block is designed to effectively capture both coarse-grained regional and fine-grained local features within large-scale indoor point cloud senses with linear computational complexity. TheOur method has two key components, including a voxel-based regional self-attention for coarse-grained features modeling and a window-based point-voxel self-attention for fine-grained features learning and multi-scale feature fusion. More specifically, researcherswe first spatially partition the raw point clouds into non-overlapping cubes, termed “windows”, following the concept similar to that of the Swin Transformer [14]. Then, rwesearchers voxelize the point clouds using a window size unit and establish a hash table [37] between the points and voxels. Voxel-based regional self-attention is subsequently applied among the nearest neighboring voxels to obtain coarse-grained features. Finally, the aggregated voxels serving as special “points” participate in the window-based point-voxel self-attention with their corresponding points to obtain fine-grained features. The voxel-based regional self-attention achieves information interaction between different windows while aggregating voxel features. Meanwhile, the window-based point-voxel self-attention not only focuses on learning fine-grained local features, but also captures high-level voxel information, enabling multi-scale feature fusion by treating voxels as specialized points.
Building upon the R2L Point-Voxel Transformer Block, researchwers propose a network for large-scale indoor point cloud semantic segmentation, named RegionPVT (Regional-to-Local Point-Voxel Transformer), as depicted in Figure 1.
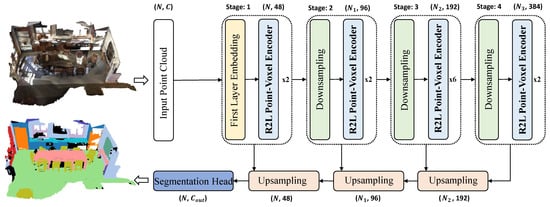
Figure 1. Network structure of theour proposed RegionPVT. R2L Point-Voxel Encoder represents the proposed Regional-to-Local Point-Voxel Transformer Encoder. An encoder–decoder architecture is employed, comprising multiple stages connected via downsampling layers to learn hierarchical multi-scale features in a progressive manner. The numbers of point clouds and feature dimensions for each stage are provided on the top and below of the model.
2. Semantic Segmentation on Point Clouds
In the realm of 3D semantic segmentation on point clouds, methods can be divided into three predominant paradigms: voxel-based approaches [18][19][32][18,19,32], point-based techniques [8][9][20][38][39][40][8,9,20,41,42,43], and hybrid methodologies [41][42][43][44][44,45,46,47]. Voxel-based strategies strive to transform the inherently irregular structure of point clouds into a structured 3D voxel grid, leveraging the computational strengths of 3D CNNs. To enhance voxel efficiency, notable frameworks such as OctNet [16], O-CNN [17], and kd-Net [45][48] shift their focus to tree structures for non-empty voxels. Meanwhile, SparseConvNet [18] and MinkowskiNet [19] promote the use of discrete sparse tensors, making it easier to create efficient, fully sparse convolutional networks designed for fast voxel processing. However, the granularity of voxel-based methods, constricted by resolution constraints, occasionally sacrifices minute geometric details during the voxelization phase. On the other hand, point-based methods aim to create advanced neural networks that can process raw point clouds. Leading the way in this field, PointNet [8] pioneered the approach of using raw point clouds as clean inputs for neural networks. This was followed by a series of creative efforts [9][20][38][40][9,20,41,43] that focused on using hierarchical local structures and incorporating valuable semantic features through complex feature combination methods. While these techniques are excellent at capturing detailed local structures and avoiding issues related to quantization, they come with significant computational costs, especially for large-scale situations. Connecting the two approaches, hybrid techniques cleverly combine both point-based and voxel-based features. By combining the advantages of both approaches, they use the precise details provided by point clouds and the broader context provided by voxel structures. For instance, frameworks like PVCNN [41][44] and DeepFusionNet [43][46] smoothly blend layers from both approaches, cleverly avoiding any potential issues that could arise from voxelization.
3. Vision Transformers
Recently, the Transformer architecture, initially designed for natural language processing, has established itself as a significant player in the computer vision field, demonstrating compelling results. The groundbreaking Vision Transformer (ViT) [26] is proof that using a transformer encoder for image classification can work, competing with traditional Convolutional Neural Networks (CNNs) in terms of performance, especially when provided with plenty of data. Inspired by ViT’s discoveries, a series of innovations [13][14][15][26][27][28][13,14,15,26,27,28] began journeys to improve and enhance vision transformer designs. For example, when dealing with the subtle difficulties of tasks like semantic segmentation and object detection that require detailed predictions, Pyramid Vision Transformer (PVT) [13] uses a pyramid structure, aiming to extract hierarchical features while also including spatial reduction attention, which helps reduce the computational load. Battling the inherent quadratic complexity characterizing global attention’s computation and memory footprints, the Swin Transformer [14] introduces a partitioned, non-overlapping window-based local attention, further bolstered by a shifted window strategy, fostering inter-window feature exchanges. Expanding the range of perception, the Focal Transformer [15] introduces “focal attention”, a skillful mechanism skilled at blending detailed local features with broader global interactions. Adding another layer of sophistication, RegionViT [46][49] infuses global insights directly into localized tokens via a regional-to-local attention mechanism.
4. Transformer on Point Cloud Analysis
In recent years, the Transformer approach has made a lasting impact on a wide range of point cloud analysis tasks, demonstrating its strength in tasks like semantic segmentation [30][31][32][47][30,31,32,40], object detection [36][48][49][36,50,51], and registration [50][52]. In the domain of 3D semantic segmentation, the Point Transformer [30] extends the original PointNet architecture [8]. It cleverly divides point cloud data into smaller groups and performs vector attention computations within these groups. On the other hand, the Fast Point Transformer [32] provides an efficient self-attention mechanism that can incorporate 3D voxel information while reducing computational complexity. On a similar trajectory, the Stratified Transformer [47][40] computes self-attention within small cubic areas, utilizing a layered key-sampling technique along with a modified window framework. However, even though they have made significant progress in understanding point clouds, these Transformer-based approaches struggle with the inherent computational challenges of self-attention, which grows quadratically. This computational bottleneck often confines their explorations to localized interactions with circumscribed receptive fields, thus leading to an unintended neglect of complex scene structures and the important details of multi-scale features.