Images constitute one of the most important forms of communication used by society and contain a large amount of important information. The human vision system is usually the first form of contact with media and has the ability to naturally extract important, and sometimes subtle, information, enabling the execution of different tasks, from the simplest, such as identifying objects, to the more complex, such as the creation and integration of knowledge. However, this system is limited to the visible range of the electromagnetic spectrum. On the contrary, computer systems have a more comprehensive coverage capacity, ranging from gamma to radio waves, which makes it possible to process a wide spectrum of images, covering a wide and varied field of applications. On the other hand, the exponential growth in the volume of images created and stored daily makes their analysis and processing a difficult task to implement outside the technological sphere. In this way, image processing through computational systems plays a fundamental role in extracting necessary and relevant information for carrying out different tasks in different contexts and application areas.
- artificial intelligence
- deep learning
- reinforcement learning
- image processing
1. Graphics Processing Units
2. Image Processing
3. Machine Learning Overview
-
In supervised learning, wresearchers can determine predictive functions using labeled training datasets, meaning each data object instance must include an input for both the values and the expected labels or output values [21][16]. This class of algorithms tries to identify the relationships between input and output values and generate a predictive model able to determine the result based only on the corresponding input data [3,21][15][16]. Supervised learning methods are suitable for regression and data classification, being primarily used for a variety of algorithms like linear regression, artificial neural networks (ANNs), decision trees (DTs), support vector machines (SVMs), k-nearest neighbors (KNNs), random forest (RF), and others [3][15]. As an example, systems using RF and DT algorithms have developed a huge impact on areas such as computational biology and disease prediction, while SVM has also been used to study drug–target interactions and to predict several life-threatening diseases, such as cancer or diabetes [23][18].
-
Unsupervised learning is typically used to solve several problems in pattern recognition based on unlabeled training datasets. Unsupervised learning algorithms are able to classify the training data into different categories according to their different characteristics [21,24][16][19], mainly based on clustering algorithms [24][19]. The number of categories is unknown, and the meaning of each category is unclear; therefore, unsupervised learning is usually used for classification problems and for association mining. Some commonly employed algorithms include K-means [3][15], SVM, or DT classifiers. Data processing tools like PCA, which is used for dimensionality reduction, are often necessary prerequisites before attempting to cluster a set of data.
3.1. Deep Learning Concepts
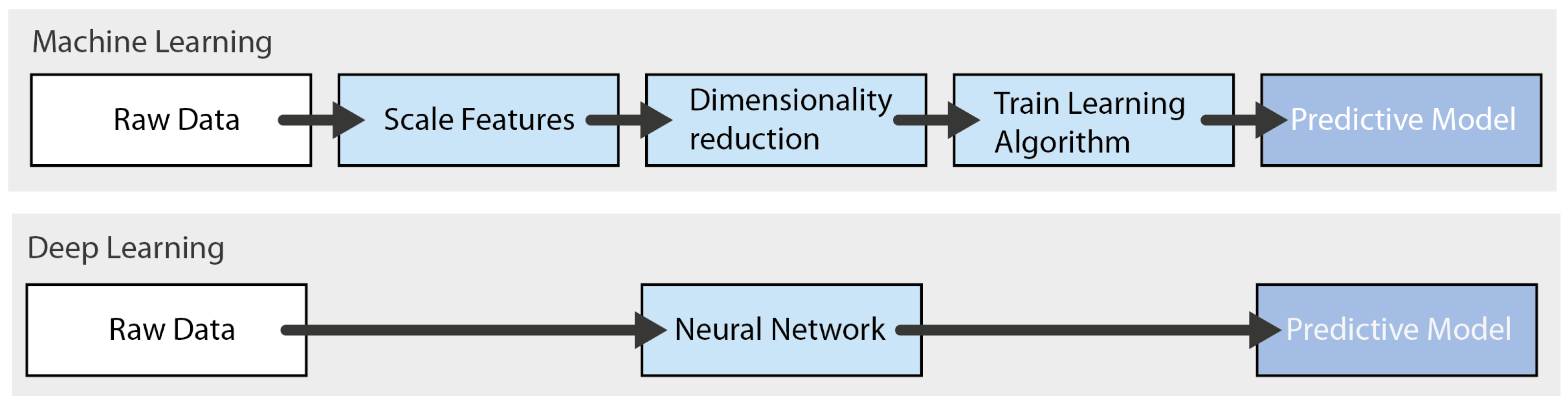
-
Training a DNN implies the definition of a loss function, which is responsible for calculating the error made in the process given by the difference between the expected output value and that produced by the network. One of the most used loss functions in regression problems is the mean squared error (MSE) [30][25]. In the training phase, the weight vector that minimizes the loss function is adjusted, meaning it is not possible to obtain analytical solutions effectively. The loss function minimization method usually used is gradient descent [30][25].
-
Activation functions are fundamental in the process of learning neural network models, as well as in the interpretation of complex nonlinear functions. The activation function adds nonlinear features to the model, allowing it to represent more than one linear function, which would not happen otherwise, no matter how many layers it had. The Sigmoid function is the most commonly used activation function in the early stages of studying neural networks [30][25].
-
As their capacity to learn and adjust to data is greater than that of traditional ML models, it is more likely that overfitting situations will occur in DL models. For this reason, regularization represents a crucial and highly effective set of techniques used to reduce the generalization errors in ML. Some other techniques that can contribute to achieving this goal are increasing the size of the training dataset, stopping at an early point in the training phase, or randomly discarding a portion of the output of neurons during the training phase [30][25].
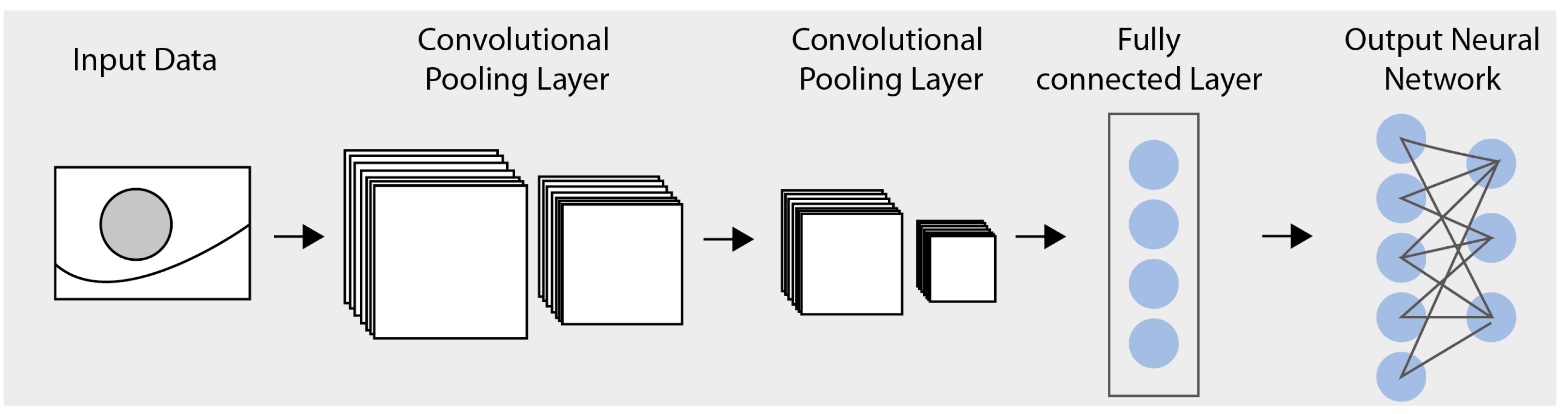
3.2. Reinforcement Learning Concepts
4. Current Challenges
References
- Raschka, S.; Patterson, J.; Nolet, C. Machine Learning in Python: Main Developments and Technology Trends in Data Science, Machine Learning, and Artificial Intelligence. Information 2020, 11, 193.
- Wu, Q. Research on deep learning image processing technology of second-order partial differential equations. Neural Comput. Appl. 2023, 35, 2183–2195.
- Ying, C.; Huang, Z.; Ying, C. Accelerating the image processing by the optimization strategy for deep learning algorithm DBN. EURASIP J. Wirel. Commun. Netw. 2018, 232, 232.
- Protopapadakis, E.; Voulodimos, A.; Doulamis, A.; Doulamis, N.; Stathaki, T. Automatic crack detection for tunnel inspection using deep learning and heuristic image post-processing. Appl. Intell. 2019, 49, 2793–2806.
- Yong, B.; Wang, C.; Shen, J.; Li, F.; Yin, H.; Zhou, R. Automatic ventricular nuclear magnetic resonance image processing with deep learning. Multimed. Tools Appl. 2021, 80, 34103–34119.
- Jardim, S.; António, J.; Mora, C. Graphical Image Region Extraction with K-Means Clustering and Watershed. J. Imaging 2022, 8, 163.
- Freeman, W.; Jones, T.; Pasztor, E. Example-based super-resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65.
- Barros, D.; Moura, J.; Freire, C.; Taleb, A.; Valentim, R.; Morais, P. Machine learning applied to retinal image processing for glaucoma detection: Review and perspective. BioMed. Eng. OnLine 2020, 19, 20.
- Rodellar, J.; Alférez, S.; Acevedo, A.; Molina, A.; Merino, A. Image processing and machine learning in the morphological analysis of blood cells. Int. J. Lab. Hematol. 2018, 40, 46–53.
- Kasinathan, T.; Uyyala, S.R. Machine learning ensemble with image processing for pest identification and classification in field crops. Neural Comput. Appl. 2021, 33, 7491–7504.
- Yadav, P.; Gupta, N.; Sharma, P.K. A comprehensive study towards high-level approaches for weapon detection using classical machine learning and deep learning methods. Expert Syst. Appl. 2023, 212, 118698.
- Suganyadevi, S.; Seethalakshmi, V.; Balasamy, K. Reinforcement learning coupled with finite element modeling for facial motion learning. Int. J. Multimed. Inf. Retr. 2022, 11, 19–38.
- Zeng, Y.; Guo, Y.; Li, J. Recognition and extraction of high-resolution satellite remote sensing image buildings based on deep learning. Neural Comput. Appl. 2022, 34, 2691–2706.
- Singh, V.; Chen, S.S.; Singhania, M.; Nanavati, B.; kumar kar, A.; Gupta, A. How are reinforcement learning and deep learning algorithms used for big data based decision making in financial industries–A review and research agenda. Int. J. Inf. Manag. Data Insights 2022, 2, 100094.
- Zhu, M.; Wang, J.; Yang, X.; Zhang, Y.; Zhang, L.; Ren, H.; Wu, B.; Ye, L. A review of the application of machine learning in water quality evaluation. Eco-Environ. Health 2022, 1, 107–116.
- Pratap, A.; Sardana, N. Machine learning-based image processing in materials science and engineering: A review. Mater. Today Proc. 2022, 62, 7341–7347.
- Mahesh, B. Machine Learning Algorithms—A Review. Int. J. Sci. Res. 2020, 9, 1–6.
- Singh, D.P.; Kaushik, B. Machine learning concepts and its applications for prediction of diseases based on drug behaviour: An extensive review. Chemom. Intell. Lab. Syst. 2022, 229, 104637.
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the 4th International Conference on Learning Representations 2016, San Juan, Puerto Rico, 2–4 May 2016.
- Dworschak, F.; Dietze, S.; Wittmann, M.; Schleich, B.; Wartzack, S. Reinforcement Learning for Engineering Design Automation. Adv. Eng. Inform. 2022, 52, 101612.
- Khan, T.; Tian, W.; Zhou, G.; Ilager, S.; Gong, M.; Buyya, R. Machine learning (ML)-centric resource management in cloud computing: A review and future directions. J. Netw. Comput. Appl. 2022, 204, 103405.
- Botvinick, M.; Ritter, S.; Wang, J.X.; Kurth-Nelson, Z.; Blundell, C.; Hassabis, D. Reinforcement Learning, Fast and Slow. Trends Cogn. Sci. 2019, 23, 408–422.
- Moravčík, M.; Schmid, M.; Burch, N.; Lisý, V.; Morrill, D.; Bard, N.; Davis, T.; Waugh, K.; Johanson, M.; Bowling, M. DeepStack: Expert-level artificial intelligence in heads-up no-limit poker. Science 2017, 356, 508–513.
- ElDahshan, K.A.; Farouk, H.; Mofreh, E. Deep Reinforcement Learning based Video Games: A Review. In Proceedings of the 2nd International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 8–9 May 2022.
- Huawei Technologies Co., Ltd. Overview of Deep Learning. In Artificial Intelligence Technology; Springer: Singapore, 2023; Chapter 1–4; pp. 87–122.
- Le, N.; Rathour, V.S.; Yamazaki, K.; Luu, K.; Savvides, M. Deep reinforcement learning in computer vision: A comprehensive survey. Artif. Intell. Rev. 2022, 55, 2733–2819.
- Melanthota, S.K.; Gopal, D.; Chakrabarti, S.; Kashyap, A.A.; Radhakrishnan, R.; Mazumder, N. Deep learning-based image processing in optical microscopy. Biophys. Rev. 2022, 14, 463–481.
- Winovich, N.; Ramani, K.; Lin, G. ConvPDE-UQ: Convolutional neural networks with quantified uncertainty for heterogeneous elliptic partial differential equations on varied domains. J. Comput. Phys. 2019, 394, 263–279.
- Pham, H.; Warin, X.; Germain, M. Neural networks-based backward scheme for fully nonlinear PDEs. SN Partial. Differ. Equ. Appl. 2021, 2, 16.
- Wei, X.; Jiang, S.; Li, Y.; Li, C.; Jia, L.; Li, Y. Defect Detection of Pantograph Slide Based on Deep Learning and Image Processing Technology. IEEE Trans. Intell. Transp. Syst. 2020, 21, 947–958.
- E, W.; Yu, B. The deep ritz method: A deep learning based numerical algorithm for solving variational problems. Commun. Math. Stat. 2018, 6, 1–12.
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629.
- Archarya, U.; Oh, S.; Hagiwara, Y.; Tan, J.; Adam, M.; Gertych, A.; Tan, R. A deep convolutional neural network model to classify heartbeats. Comput. Biol. Med. 2021, 89, 389–396.
- Ha, V.K.; Ren, J.C.; Xu, X.Y.; Zhao, S.; Xie, G.; Masero, V.; Hussain, A. Deep Learning Based Single Image Super-resolution: A Survey. Int. J. Autom. Comput. 2019, 16, 413–426.
- Jeong, C.Y.; Yang, H.S.; Moon, K. Fast horizon detection in maritime images using region-of-interest. Int. J. Distrib. Sens. Netw. 2018, 14, 1550147718790753.
- Olmos, R.; Tabik, S.; Lamas, A.; Pérez-Hernández, F.; Herrera, F. A binocular image fusion approach for minimizing false positives in handgun detection with deep learning. Inf. Fusion 2019, 49, 271–280.
- Zhao, X.; Wu, Y.; Tian, J.; Zhang, H. Single Image Super-Resolution via Blind Blurring Estimation and Dictionary Learning. Neurocomputing 2016, 212, 3–11.
- Qi, C.; Song, C.; Xiao, F.; Song, S. Generalization ability of hybrid electric vehicle energy management strategy based on reinforcement learning method. Energy 2022, 250, 123826.
- Ritto, T.; Beregi, S.; Barton, D. Reinforcement learning and approximate Bayesian computation for model selection and parameter calibration applied to a nonlinear dynamical system. Mech. Syst. Signal Process. 2022, 181, 109485.
- Hwang, R.; Lee, H.; Hwang, H.J. Option compatible reward inverse reinforcement learning. Pattern Recognit. Lett. 2022, 154, 83–89.
- Ladosz, P.; Weng, L.; Kim, M.; Oh, H. Exploration in deep reinforcement learning: A survey. Inf. Fusion 2022, 85, 1–22.
- Khayyat, M.M.; Elrefaei, L.A. Deep reinforcement learning approach for manuscripts image classification and retrieval. Multimed. Tools Appl. 2022, 81, 15395–15417.
- Nguyen, D.P.; Ho Ba Tho, M.C.; Dao, T.T. A review on deep learning in medical image analysis. Comput. Methods Programs Biomed. 2022, 221, 106904.
- Laskin, M.; Lee, K.; Stooke, A.; Pinto, L.; Abbeel, P.; Srinivas, A. Reinforcement Learning with Augmented Data. In Proceedings of the 34th Conference on Neural Information Processing Systems 2020, Vancouver, BC, Canada, 6–12 December 2020; pp. 19884–19895.
- Li, H.; Xu, H. Deep reinforcement learning for robust emotional classification in facial expression recognition. Knowl.-Based Syst. 2020, 204, 106172.
- Gomes, G.; Vidal, C.A.; Cavalcante-Neto, J.B.; Nogueira, Y.L. A modeling environment for reinforcement learning in games. Entertain. Comput. 2022, 43, 100516.
- Georgeon, O.L.; Casado, R.C.; Matignon, L.A. Modeling Biological Agents beyond the Reinforcement-learning Paradigm. Procedia Comput. Sci. 2015, 71, 17–22.
- Yin, S.; Liu, H. Wind power prediction based on outlier correction, ensemble reinforcement learning, and residual correction. Energy 2022, 250, 123857.
- Badia, A.P.; Piot, B.; Kapturowski, S.; Sprechmann, P.; Vitvitskyi, A.; Guo, D.; Blundell, C. Agent57: Outperforming the Atari Human Benchmark. arXiv 2020, arXiv:2003.13350.
- Zong, K.; Luo, C. Reinforcement learning based framework for COVID-19 resource allocation. Comput. Ind. Eng. 2022, 167, 107960.
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533.
- Ren, J.; Guan, F.; Li, X.; Cao, J.; Li, X. Optimization for image stereo-matching using deep reinforcement learning in rule constraints and parallax estimation. Neural Comput. Appl. 2023, 1–11.
- Morales, E.F.; Murrieta-Cid, R.; Becerra, I.; Esquivel-Basaldua, M.A. A survey on deep learning and deep reinforcement learning in robotics with a tutorial on deep reinforcement learning. Intell. Serv. Robot. 2021, 14, 773–805.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90.
- Krichen, M. Convolutional Neural Networks: A Survey. Computers 2023, 12, 151.
- Song, D.; Kim, T.; Lee, Y.; Kim, J. Image-Based Artificial Intelligence Technology for Diagnosing Middle Ear Diseases: A Systematic Review. J. Clin. Med. 2023, 12, 5831.
- Muñoz-Saavedra, L.; Escobar-Linero, E.; Civit-Masot, J.; Luna-Perejón, F.; Civit, A.; Domínguez-Morales, M. A Robust Ensemble of Convolutional Neural Networks for the Detection of Monkeypox Disease from Skin Images. Sensors 2023, 23, 7134.