Multiple object tracking detects and tracks multiple targets in videos, such as pedestrians, vehicles, and animals. It is an important research direction in the field of computer vision, and has been widely applied in intelligent surveillance and behavior recognition. High-speed vision is a computer vision technology that aims to realize real-time image recognition and analysis through the use of fast and efficient image processing algorithms at high frame rates of 1000 fps or more. It is an important direction in the field of computer vision and is used in a variety of applications, such as intelligent transportation, security monitoring, and industrial automation.
1. Introduction
Multi-target tracking and high-definition image acquisition are important issues in the field of computer vision
[1]. High-definition images of many different targets can provide more details, which is helpful for object recognition and improves the accuracy of image analysis. It has been widely used in traffic management.
[2], security monitoring
[3], intelligent transportation systems
[4], robot navigation
[5], auto pilot
[6], and video surveillance
[7].
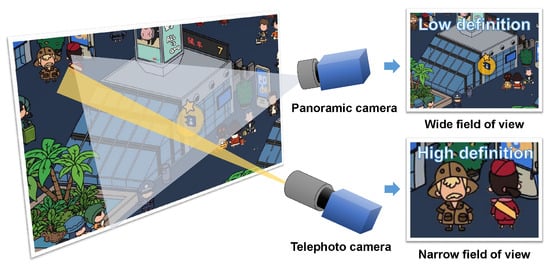
However, there is a contradiction between wide field of view and high-definition resolution, as shown in
Figure 1. The discovery and tracking of multiple targets depends on a wide field of view. While a panoramic camera with a short focal length can provide a wide field of view, the definition of the image is low. A telephoto camera is the exact opposite of a panoramic camera. Using a panoramic camera with a larger resolution is a feasible solution; however, it requires greater expenditure and larger camera size
[8]. With the rapid development of deep learning in the image field, the super-resolution reconstruction method based on autoencoding has become the mainstream, and its reconstruction accuracy is significantly better than that of traditional methods
[9]. However, due to the huge network model and large amount of model training required in the super-resolution method based on deep learning, there are defects in the reconstruction speed and the flexibility of the model
[10].
Figure 1.
Contradiction between wide field of view and high-definition images.
Therefore, researchers have tried to use telephoto cameras to obtain a larger field of view and track multiple targets. A feasible solution is to stitch the images obtained from a telephoto camera array together into high-resolution images and track multiple targets
[11]. Again, this results in greater expenditure and an increase in device size. Another research method is to make the telephoto camera an active system by mounting it on a gimbal. Through the horizontal and vertical movement of the gimbal, the field of view of a pan-tilt-zoom (PTZ) camera can be changed to obtain a wide field of view
[12]. However, the original design of such a gimbal camera is not intended for multi-target tracking. Due to the limited movement speed of the gimbal and the size of the telephoto lens, it is difficult for gimbal-based PTZ cameras to move at high speeds and observe multiple objects
[13]. Compared to traditional camera systems operating at 30 or 60 fps, high-speed vision systems can work at 1000 fps or more
[14]. The high-speed vision system acquires and processes image information with extremely low latency and interacts with the environment through visual feedback control
[15]. In recent years, a galvanometer-based reflective camera system has been developed that can switch the perspective of a telephoto camera at hundreds of frames per second
[16]. This reflective PTZ camera system is able to virtualize multiple virtual cameras in a time-division multiplexing manner in order to observe multiple objects
[17]. Compared with traditional gimbal-based and panoramic cameras, galvanometer-based reflective PTZ cameras have the advantages of low cost, high speed, and high stability
[18], and are suitable for multi-target tracking and high-definition capture.
However, the current galvanometer-based PTZ cameras rarely perform active visual control in the process of capturing multiple targets. Instead, they mainly rely on panoramic cameras, laser radars, and photoelectric sensors to obtain the positions of multiple targets, and finally use reflective PTZ cameras for multi-angle capture
[19]. Due to the impact of detection delay and accuracy, it is difficult for multiple objects to be tracked smoothly. With the victory of AlexNet in the visual competition, CNN-based detectors continue to develop, and can now detect various objects in an image at a dozens of frames per second
[20]. For high-speed vision at a speed of hundreds of frames per second, however, it is difficult to achieve real-time detection with deep learning.
2. Object Detection
Object detection is a computer vision task that involves detecting instances of semantic objects of a certain class (such as a person, bicycle, or car) in digital images and videos
[21][22]. The earliest research in the field of object detection can be traced back to the Eigenface method for face detection proposed by researchers at MIT
[22][23]. Over the past few decades, object detection has received great attention and achieved significant progress. Object detection algorithms are roughly divided into two stages, namely, traditional object detection algorithms and the object detection algorithms based on deep learning
[23][24].
Due to the limitations of computing speed, traditional object detection algorithms focus mainly on pixel information in images. Traditional object detection algorithms can be divided into two categories, sliding window-based methods
[24][25] and region proposal-based methods
[25][26]. The sliding window-based approach achieves object detection by sliding windows of different sizes over an image and classifying the contents within the different windows. Many such feature extraction methods have been proposed, such as histogram of oriented gradients (HOG), local binary patterns (LBP), and Haar-based classifiers. These features, in conjunction with traditional machine learning methods such as SVM and BOOST, have been widely applied in pedestrian detection
[26][27] and face recognition
[27][28]. Region proposal-based methods achieve object detection by proposing regions in which objects may exist in generated images, then classifying and regressing these regions
[28][29].
Traditional algorithms have been proven effective; however, with continuous improvements in computing power and dataset availability, object detection technologies based on deep learning have gradually replaced the traditional manual feature extraction methods and become the main research direction. Thanks to continuous development, convolutional neural network (CNN)-based object detection methods have evolved into a series of high-performance structural models such as AlexNet
[29][30], VGG
[30][31], GoogLeNet
[31][32], ResNet
[32][33], ResNeXt
[33][34], CSPNet
[34][35], and EfficientNet
[35][36]. These network models have been widely employed as backbone architectures in various CNN-based object detectors. According to the differences in the detection process, object detection algorithms based on deep learning can be divided into two research directions, One-Stage and Two-Stage
[36][37]. Two-stage object detection algorithms transform the detection problem into a classification problem for generated local region images based on region proposals. Such algorithms generate region proposals in the first stage, then classify and regress the content in the region of interest in the second stage. There are many efficient object detection algorithms that use a two-stage detection process, such as R-CNN
[37][38], SPP-Net
[38][39], Fast R-CNN
[39][40], Faster R-CNN
[40][41], FPN
[41][42], R-FCN
[42][43], and DetectoRS
[43][44]. R-CNN was the earliest method to apply deep learning technology to object detection, reaching an MAP of 58.5% on the VOC2007 data. Subsequently, SPP-Net, Fast R-CNN, and Faster R-CNN sped up the running speed of the algorithm while maintaining the detection accuracy. One-stage object detection algorithms, on the other hand, are based on regression, which converts the object detection task into a regression problem for the entire image
[44][45]. Among the one-stage object detection algorithms, the most famous are single shot multibox detector (SSD)
[45][46], YOLO
[46][47], RetinaNet
[47][48], CenterNet
[48][49], and Transformer
[49][50]-based detectors
[50][51]. YOLO was the earliest one-stage target detection algorithm applied to actual scenes, obtaining stable and high-speed detection results
[51][52]. The YOLO algorithm divides the input image into
𝑆 × 𝑆 grids, predicts
B bounding boxes for each grid, and then predicts the objects in each grid separately. The result of each prediction includes the location, size, confidence of the bounding box, and the probability that the object in the bounding box belongs to each category. This method of dividing the grid avoids a large number of repeated calculations, helping the YOLO algorithm to achieve a faster detection speed. In follow-up studies, algorithms such as YOLOv2
[52][53], YOLOv3
[53][54], YOLOv4
[54][55], YOLOv5
[55][56], and YOLOv6
[56][57] have been proposed. Owing to its high stability and detection speed, in this
rstudy we
search use yolov4
is used as the AI detector.
3. Multiple Object Tracking (Mot)
Currently, there are three popular research directions in multi-object tracking: detection-based MOT, detection and tracking-based joint MOT, and attention-based MOT. In detection-based MOT algorithms, object detection is performed on each frame to obtain image patches of all detected objects. A similarity matrix is then constructed based on the IoU and appearance between all objects across adjacent frames, and the best matching result is obtained using a Hungarian or greedy algorithm; representative algorithms include SORT
[57][63] and DeepSORT
[58][64]. In detection and tracking-based joint MOT algorithms, detection and tracking are integrated into a single process. Based on CNN detection, multiple targets are fed into the feature extraction network to extract features and directly output the tracking results for the current frame. Representative algorithms include JDE
[59][65], MOTDT
[60][66], Tracktor++
[61][67], and FFT
[62][68]. The attention mechanism-based MOT is inspired by the powerful processing ability of the Transformer model in natural language processing. Representative algorithms include TransTrack
[63][69] and TrackFormer
[64][70]. TransTrack takes the feature map of the current frame as the key and the target feature query from the previous frame and a set of learned target feature queries from the current frame as the input query of the whole network.
4. High-Speed Vision
High-speed vision has two properties: (1) the image displacement from frame to frame is small, and (2) the time interval between frames is extremely short. In order to realize vision-based high-speed feedback control, it is necessary to process massive images in a short time. Unfortunately, current image processing algorithms, such as noise reduction, tracking, and recognition, are all based on traditional image data involving dozens frames per second. An important idea in high-speed image processing is that it reduces the amount of work required for small-scale shifts between high-speed frames. Field programmable gate arrays (FPGAs) and graphics processing units (GPU), which support massively parallel operations, are ideal for processing two-dimensional data such as images. In
[65][74], the authors presented a high-speed vision platform called
𝐻3 vision. This platform employs dedicated FPGA hardware to implement image processing algorithms and enables simultaneous processing of a
256 × 256 pixel image at 10,000 fps. The hardware implementation of image processing algorithms on an FPGA board provides high performance and low latency, making it suitable for real-time applications that require high-speed image processing. In
[66][75], a super-high-speed vision platform (HSVP) was introduced that was capable of processing 12-bit
1024 × 1024 grayscale images at a speed of 12,500 frames per second using an FPGA platform. While the fast computing speed of FPGA is ideal for high-speed image processing, its programming complexity and limited memory capacity can pose significant challenges. Compared with FPGA, GPU platforms can realize high-frame-rate image processing with lower programming difficulty. A GPU-based real-time full-pixel optical flow analysis method was proposed in
[67][76].
In addition to high-speed image processing, high-speed vision feedback control is very important. Gimbal-based camera systems are specifically designed for image streams with dozens of frames per second. Due to the limited size and movement speed of the camera, it is often difficult to track objects at high speeds while simultaneously observing multiple objects. Recently, a high-speed galvanometer-based reflective PTZ camera system was proposed in
[68][77]. The PTZ camera system can acquire images from multiple angles in an extremely short time and virtualize multiple cameras from a large number of acquired image streams. In
[69][78], a novel dual-camera system was proposed which is capable of simultaneously capturing zoomed-in images using an ultrafast pan-tilt camera and wide-view images using a separate camera. The proposed system provides a unique capability for capturing both wide-field and detailed views of a scene simultaneously. To enable the tracking of specific objects in complex backgrounds, a hybrid tracking method that combines convolutional neural networks (CNN) and traditional object tracking techniques was proposed in
[70][21]. This hybrid method achieves high-speed tracking performance of up to 500 fps and has shown promising results in various applications, such as robotics and surveillance.