Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Manuel Mazzara and Version 2 by Sirius Huang.
Prostate imaging refers to various techniques and procedures used to visualize the prostate gland for diagnostic and treatment purposes. Deep learning (DL) architectures have shown promising effectiveness and relative efficiency in prostate cancer (PCa) diagnosis due to their ability to analyze complex patterns and extract features from medical imaging data.
- machine learning
- deep learning
- prostate cancer
1. Introduction
Prostate cancer (PCa) is the second most lethal and prevalent non-cutaneous tumor in males globally [1]. Published statistics from the American Cancer Society (ACS) show that it is the most common cancer in American men after skin cancer, with 288 and 300 new cases in 2023, resulting in about 34,700 deaths. By 2030, it is anticipated that there will be 11 million cancer deaths, which would be a record high [2]. Worldwide, this type of cancer affects many males, with developing and underdeveloped countries having a higher prevalence and higher mortality rates [3]. PCa is a type of cancer that develops in the prostate gland, a small walnut-shaped gland located below the bladder in men [4]. The male reproductive system contains the prostate, which is a small gland that is located under the bladder and in front of the rectum. It surrounds the urethra, which is the tube that carries urine from the bladder out of the body. The primary function of the prostate (Figure 1) is to produce and secrete a fluid that makes up a part of semen, which is the fluid that carries sperm during ejaculation [5]. The development of PCa in an individual can be caused by a variety of circumstances including age (older men are more likely to develop prostate cancer), family history (having a close relative who has prostate cancer increases the risk), race (African American males are more likely to develop prostate cancer) and specific genetic mutations [6][7][6,7].
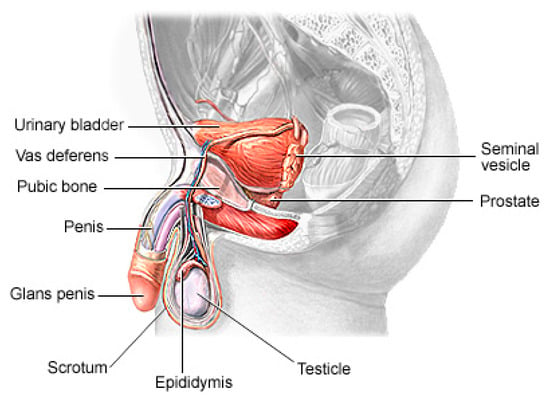
Figure 1.
The physiology of a human prostate.
The recent advances in sophisticated computers and algorithms in recent decades have paved the way for improved PCa diagnosis and treatment [8]. Computer-aided diagnosis (CAD) refers to the use of computer algorithms and technology to assist healthcare professionals in the prognosis and diagnosis of patients [9]. CAD systems are designed to serve as Decision Support (or Expert) Systems, which analyze medical data, such as images or test results, and provide experts with additional information or suggestions to aid in the interpretation and diagnosis of various medical conditions. They are commonly used in medical imaging fields to detect anomalies or assist in the interpretation and analysis of medical images such as X-rays, Computed Tomography (CT) scans, Magnetic Resonance Imaging (MRI) scans and mammograms [10]. These systems use pattern recognition, machine learning algorithms and deep learning algorithms to identify specific features or patterns that may indicate the presence or absence of a disease or condition [11]. It can also help radiologists by highlighting regions of interest (ROI) or by providing quantitative measurements for further analysis. Soft computing techniques play a major role in decision making across several sectors of the field of medical image analysis [12][13][12,13]. Deep learning, a branch of artificial intelligence, has shown promising performance in the identification of patterns and the classification of medical images [14][15][14,15].
2. Imaging Modalities
Prostate imaging refers to various techniques and procedures used to visualize the prostate gland for diagnostic and treatment purposes. These imaging methods help in evaluating the size, shape and structure of the prostate, as well as detecting any abnormalities or diseases, such as prostate cancer [16][17][24,25], and they include Transrectal Ultrasound (TRUS) [18][26], Magnetic Resonance Imaging (MRI) [19][27], Computed Tomography (CT) [20][28], Prostate-Specific Antigen (PSA) [21][29], Prostate-Specific Membrane Antigen (PET/CT) [22][30] and bone scans [23][31]. A TRUS involves inserting a small probe into the rectum, which emits high-frequency sound waves to create real-time images of the prostate gland. A TRUS is commonly used to guide prostate biopsies and assess the size of the prostate [18][24][26,32]. MRI, one of the most common prostate imaging methods, uses a powerful magnetic field and radio waves to generate detailed images of the prostate gland. It can provide information about the size, location and extent of tumors or other abnormalities. A multiparametric MRI (mpMRI) combines different imaging sequences to improve the accuracy of prostate cancer detection [25][26][33,34]. A CT scan uses X-ray technology to produce cross-sectional images of the prostate gland. It may be utilized to evaluate the spread of prostate cancer to nearby lymph nodes or other structures. PSMA PET/CT imaging is a relatively new technique that uses a radioactive tracer targeting PSMA, a protein that is highly expressed in prostate cancer cells [27][35]. It provides detailed information about the location and extent of prostate cancer, including metastases. Bone scans are often performed in cases where prostate cancer has spread to the bones. A small amount of radioactive material is injected into the bloodstream, which is then detected by a scanner [23][31]. The scan can help to identify areas of bone affected by cancer. PSA (density mapping) combines the results of PSA blood tests with transrectal ultrasound measurements to estimate the risk of prostate cancer. It helps to assess the likelihood of cancer based on the size of the prostate and the PSA level [28][36]. The choice of imaging technique depends on various factors, including the specific clinical scenario, the availability of resources and the goals of the evaluation [29][30][37,38].3. Risks of PCa
The risk of PCa varies in men depending on several factors, and identifying these factors can aid in the prevention and early detection of PCa, personalized healthcare, research and public health policies, genetic counseling and testing and lifestyle modifications. The most common clinically and scientifically verified risk factors include age, obesity and family history [31][32][39,40]. In low-risk vulnerable populations, the risk factors include benign prostatic hyperplasia (BPH), smoking, diet and alcohol consumption [33][41]. Although PCa is found to be rare in people below 40 years of age, an autopsy study on China, Israel, Germany, Jamaica, Sweden and Uganda showed that 30% of men in their fifties and 80% of men in their seventies had PCa [34][42]. Studies also found that genetic factors, a lack of exercise and sedentary lifestyles are cogent risk factors of PCa, including obesity and an elevated blood testosterone level [35][36][37][38][43,44,45,46]. The consumption of fruits and vegetables, the frequency of high-fat meat consumption, the level of Vitamin D in blood streams, cholesterol level, infections and other environmental factors are deemed to contribute to PCa occurrence in men [39][40][47,48].4. Generic Overview of Deep Learning Architecture for PCa Diagnosis
Deep learning (DL) architectures have shown promising effectiveness and relative efficiency in PCa diagnosis due to their ability to analyze complex patterns and extract features from medical imaging data [13]. One commonly used deep learning architecture for cancer diagnosis is Convolutional Neural Networks (CNNs). CNNs are particularly effective in image analysis tasks, including medical image classification, segmentation, prognosis and detection [41][49]. Deep learning, given its ever-advancing variations, has recorded significant advancements in the analysis of cancer images including histopathology slides, mammograms, CT scans and other medical imaging modalities. DL models can automatically learn hierarchical representations of images, enabling them to detect patterns and features that are indicative of cancer. They are also trained to classify PCa images into different categories or subtypes. By learning from labeled training data, these models can accurately classify new images, aiding in cancer diagnosis and subtyping [42][50]. Transfer learning is often employed in PCa image analysis. Pre-trained models, such as CNNs trained on large-scale datasets like ImageNet, are fine-tuned or used as feature extractors for PCa-related tasks. This approach leverages the learned features from pre-training, improving performance even with limited annotated medical image data. One image dataset augmentation framework is a Generative Adversarial Network (GAN). GANs can generate realistic synthetic images, which can be used to supplement training data, enhance model generalization and improve the performance of cancer image analysis models. The performance and effectiveness of deep learning models for PCa image analysis, however, depend on various factors, including the quantity and quality of labeled data, the choice of architecture, the training methodology and careful validation of diverse datasets. The key compartments in a typical deep CNN model for PCa diagnosis, as shown in Figure 2, include the convolutional layers, the pooling layers, the fully connected layers, the activation functions, the data augmentation and the attention mechanisms [43][44][51,52]. The convolutional layers are the fundamental building blocks of CNNs. They apply filters or kernels to input images to extract relevant features. These filters detect patterns at different scales and orientations, allowing for the network to learn meaningful representations from the input data. The pooling layers downsample feature maps, reducing the spatial dimensions while retaining important features. Max pooling is a commonly used pooling technique, where the maximum value in each pooling window is selected as the representative value [45][53]. The fully connected layers are used at the end of CNN architectures to make predictions based on the extracted features. These layers connect all the neurons from the previous layer to the subsequent layer, allowing for the network to learn complex relationships and make accurate classifications. Activation functions introduce non-linearity into the CNN architecture, enabling the network to model more complex relationships. Common activation functions include ReLU (Rectified Linear Unit), sigmoid and tanh [46][47][54,55]. Transfer learning involves leveraging pre-trained CNN models on large datasets (such as ImageNet, ResNet, VGG-16, VGG-19, Inception-v3, ShuffleNet, EfficientNet, GoogleNet, ResNet-50, SqueezeNet, etc.) and adapting them to specific medical imaging tasks. By using pre-trained models, which have learned general features from extensive data, the model construction time can be saved, as well as computational resources, and can achieve good performance even on smaller medical datasets. Data augmentation techniques, such as rotation, scaling and flipping, can be employed to artificially increase the diversity of the training data. Data augmentation helps to improve the generalization of a CNN model by exposing it to variations and reducing overfitting. Attention mechanisms allow for the network to focus on relevant regions or features within the image. These mechanisms assign weights or importance to different parts of the input, enabling the network to selectively attend to salient information [48][49][56,57].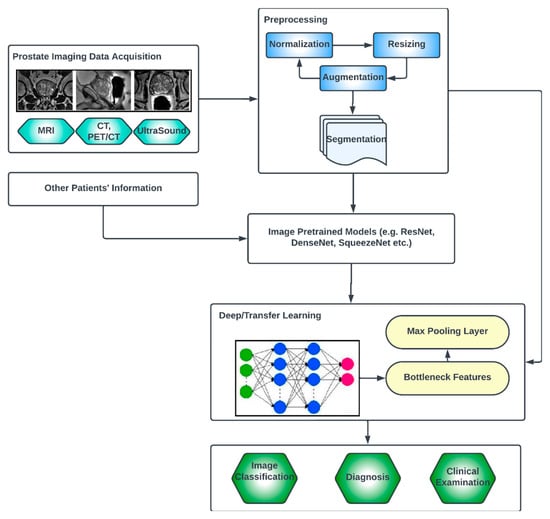
Figure 2.
Generic deep learning architecture for PCa image analysis.