Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Weiliang Xie and Version 2 by Lindsay Dong.
Sensor-based Human Action Recognition (HAR)R is a fundamental component in human–robot interaction and pervasive computing. It achieves HAR by acquiring sequence data from embedded sensor devices (accelerometers, magnetometers, gyroscopes, etc.) of multiple sensor modalities worn at different body locations for data processing and analysis.
- human action recognition
- machine learning
- HAR
- Sensor
1. Introduction
Human Action Recognition (HAR) is gradually attracting attention, and it is widely used in the fields of human–robot interaction, elderly care, healthcare, and sports [1][2][3][1,2,3]. In addition, it plays an important role in areas such as biometrics, entertainment, and intelligent-assisted living. Examples include fall behavior detection for the homebound elderly population, rehabilitative exercise training for patients, and exercise action assessment for athletes [4][5][4,5]. HAR can be performed from both visual and non-visual modalities [6][7][8][6,7,8], where the visual modalities are mainly data modalities such as RGB video, depth, bone, and point cloud; and the non-visual modalities are mainly data modalities such as sensor signals, radar, magnetic field, and Wi-Fi signals based on wearable devices [9]. These data modalities encode different sources of information, and different modalities have their own advantages and characteristics in different application scenarios.
Visual-modality-based approaches perform feature extraction from video streams captured by cameras; although this approach can visualize the characteristics of human actions, its performance is affected by the viewing angle, camera occlusion, and the quality of the background illumination, and there may be privacy issues. On the contrary, the non-visual modality-based approach, which acquires sensor data of human actions through wearable devices, does not suffer from privacy issues, has a relatively small amount of data, does not have occlusion issues, and is adaptable to the environment. Better results are expected by processing and analyzing sensor data for HAR.
Sensor-based HAR is a fundamental component in human–robot interaction and pervasive computing [10]. It achieves HAR by acquiring sequence data from embedded sensor devices (accelerometers, magnetometers, gyroscopes, etc.) of multiple sensor modalities worn at different body locations for data processing and analysis. Generally, the data collected by the sensors in a HAR system form a time series of information. After noise reduction and normalization of the data sequence, it is segmented into individual windows by a sliding window method with a fixed window size and overlap rate. Then, each window is categorized as an action by the HAR method. Figure 1 illustrates an example of window action on the PAMAP2 dataset. In daily life, human physical actions include not only some simple actions, but also some complex actions consisting of multiple microscopic processes. For example, the action of running includes many microscopic processes, such as starting, accelerating, maintaining, sprinting, decelerating, and so on.
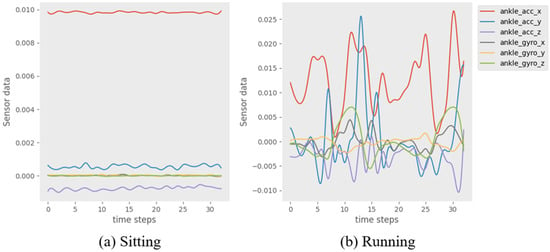
Figure 1.
Example of a window of “Sitting” (
a
) and “Running” (
b
) actions on the PAMAP2 dataset, timestep = 1 s.
Traditional machine learning methods [11][12][11,12] rely heavily on hand-crafted features and expert knowledge [13] and only capture shallow features, making it difficult to perform HAR accurately. Recently, deep learning methods have provided promising results in the field of HAR [14]. It can learn feature representations for classification tasks without involving domain-specific knowledge, which achieves more accurate HAR. Therefore, many researchers have applied CNNs and RNNs to HAR to effectively perform feature extraction, automatic learning of feature representations, and removal of hand-crafted features [15][16][17][15,16,17]. However, since action recognition is a time-series classification problem, CNNs may have difficulty in capturing time-dimensional information. The Long Short-Term Memory (LSTM) network can effectively capture the temporal context information and long-term dependency of sequence data, so some works successfully apply LSTM to HAR [18][19][20][18,19,20].
In addition, since CNNs can extract local spatial feature information and LSTMs can capture temporal context information, hybrid models can effectively capture spatio-temporal motion patterns from sensor signals. Some recent work combining hybrid models of CNNs and RNNs has shown promising results [21][22][23][24][21,22,23,24]. However, since LSTMs compress all the input information into the network, this will lead to the incorporation of noise from the sensor data acquisition when extracting features, which will affect the effectiveness of action recognition. Based on this, there are some works to solve this problem by introducing the attention mechanism [25][26][27][28][29][25,26,27,28,29]. The attention mechanism enables the model to focus more on the parts that are relevant to the current recognition to improve accuracy. Also, some works optimize the action recognition and window segmentation problems by multi-task learning for HAR [30].
2. Sensor-Based Human Action Recognition
Research work on sensor-based HAR can be categorized into two types: machine learning methods and deep learning methods. Earlier research works on HAR were mainly based on traditional machine learning methods such as the Random Forest (RF), Support Vector Machine (SVM), and Hidden Markov Model (HMM). Gomes et al. [31] compared the performances of three classifiers: SVM, RF, and KNN. Kasteren et al. [32] proposed a sensor that can automatically recognize actions and data labeling system; they demonstrated the performance of a HMM in recognizing actions. Tran et al. [33] constructed a HAR system via an SVM that was able to recognize six human actions by extracting 248 features. However, traditional machine learning methods rely heavily on hand-crafted features such as mean, maximum, variance, and fast Fourier transform coefficients [34]. Since extracting hand-crafted features relies on human experience and expert knowledge and only captures shallow features, the accuracy is limited.
Unlike traditional machine learning methods, deep learning can learn the feature representation of a classification task without involving domain-specific knowledge, and HAR can be achieved without extracting hand-crafted features. Yang et al. [15] proposed that CNNs can effectively capture salient features in the spatial dimension and outperform traditional machine learning methods. Jiang et al. [35] proposed a CNN model that arranges raw sensor signals into signal images as model inputs and learns low-level to high-level features from action images to achieve effective HAR.
Meanwhile, since action recognition is a time-series classification problem, it may be difficult for CNNs to capture time dimension information. In contrast, Hammerla et al. [18] and Dua et al. [19] used the LSTM network for HAR, which can effectively capture contextual information and long-term dependencies of the temporal dimension of the sensor sequence data. Ullah et al. [36] proposed a stacked LSTM network for recognizing six types of human actions using smartphone data, with 93.13% recognition accuracy. Mohsen et al. [37] used GRU to classify human actions, achieving 97% accuracy on the WISDM dataset. Gaur et al. [38] achieved a high accuracy in classifying repetitive and non-repetitive actions over time based on LSTM–RNN networks. Although the above methods can recognize some simple human actions (e.g., cycling, walking) well, the recognition of some complex actions (e.g., stair up/down, open/close door) is still challenging, which is due to the difficulty in capturing the spatio-temporal correlation of sensor signals using a single CNN or RNN network.
Recently, much of the work in HAR has focused on hybrid models of CNN and RNN. Ordóñez et al. [21] combined an CNN and an LSTM to achieve significant results in capturing spatio-temporal features from sensor signals. Yao et al. [22] constructed separate CNNs for the different types of data in the sensor inputs, and then merged them to form global feature information; they then extracted temporal relationships through an RNN to achieve HAR. Nafea et al. [39] used CNN with varying kernel dimensions and BiLSTM to capture features with different resolutions. They effectively extracted spatio-temporal features from sensor data with high accuracy.
In addition, some works address the problem that LSTMs may compress the noise of sensor data into the network. They introduce the attention mechanism to prevent the incorporation of noisy and irrelevant parts when extracting features, thus improving the effectiveness of HAR. Murahari et al. [27] added an attention layer to the DeepConvLSTM architecture proposed in Ordóñez et al. [21] to learn the correlation weight of the hidden state outputs of the LSTM layer to create context vectors, instead of directly using the last hidden state. Ma et al. [25] also proposed an architecture based on attention-enhanced CNNs and GRUs, which uses attention to augment the weight of the sensor modalities and encapsulate the temporal correlation and temporal context information of specific sensor signal features. In contrast, Mahmud et al. [26] completely discarded the recurrent structure and adapted the transformer architecture [40] proposed in the field of machine translation to use a self-attention-based neural network model to generate feature representations for classification to better recognize human actions. Zhang et al. [41] proposed a hybrid model ConvTransformer for HAR, which can fully extract local and global information of sensor signals and use attention to enhance the model feature characterization capability. Xiao et al. [42] proposed a two-stream transformer network to extract sensor features from temporal and spatial channels that effectively model the spatio-temporal dependence of sensor signals.