Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Jessie Wu and Version 3 by Jessie Wu.
Detection of Cyber Attacks in Social Media Messages Based on Convolutional Neural Networks and natural language processing (NLP) Techniques is a messages preprocessing proposal independent of social media source and validations based on threat hunting techniques.
- cyberattack
- deep learning
- malware
- NLP
- phishing
- social networks
- spam
1. Introduction
There are four types of cyberattacks: spam, phishing, malware distribution, and bot attacks (which refers to the spreading of harmful messages among users, whether or not the attacker interacts with the victim). Therefore, the problem is defined as follows: given a message m, consider four subsets of a set C – C1 for spam, C2 for phishing, C3 for malware, and C4 for a bot attack. The task is to detect whether m belongs to the C set. If m is in C, classify m according to which subset of C it belongs to.
To address this problem, this research presents the following methodology, which involves analyzing the content of texts from diverse social networks, discussion forums, and blogs to detect and classify the content according to the previously mentioned problem. This methodology utilizes tools and techniques such as natural language processing (NLP)NLP and a deep learning (DL)DL model based on a CNN to detect and classify each message. Therefore, it only considers the text and disregards multimedia elements like images, videos, animations, or audio. Moreover, the importance of creating a model capable of detecting a more significant number of threats and being utilized regardless of the data source is seen as an opportunity for extending the landscape of cyberattack detection tasks in this kind of content.
Figure 1 illustrates the proposed pipeline for cyberattack detection in social network messages, depicting the stages from gathering the message to detecting and classifying it using the convolutional neural network (CNN) model.
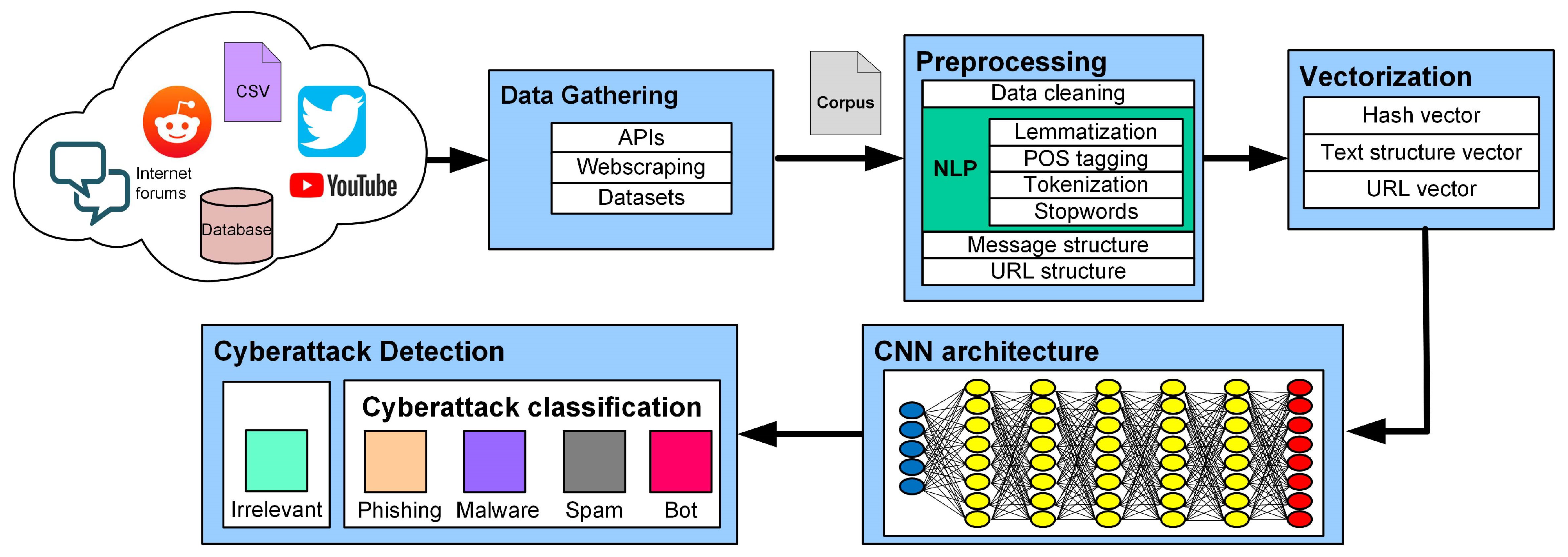
Figure 1. Pipeline of stages of cyberattack detection in social network messages.
2. Data Gathering
The gathered information integrates the dataset utilized for the training and testing activities of the CNN model, making these data the corpus for the model. The messages obtained through the following mechanisms and resources serve as inputs for the preprocessing stage of this methodology:
-
APIsThis software mechanism enables the execution of activities to request samples of publications through functionalities specific to each social network. These functionalities include searching by keywords, specific accounts, retrieval of messages by ID, publication dates, and other properties. For example, to collect Tweets and Retweets from Twitter, an endpoint connection from their API was used to download available public messages.
-
ScrapingWebsites such as blogs and discussion forums operate based on browsing through the HTTP protocol. To extract messages from these interaction spaces, this research utilized web-scraping and -crawling techniques to simulate recursive browsing through different websites.
-
Datasets
3. Preprocessing
The next step is preprocessing, which involves using NLP techniques to create three arrays. These arrays represent the properties of each message, such as the grammar, lexical, and semantics through tokens, the structural composition of the message, and the representation of features based on the URL structure.
3.1. Content of Message
The details of the corpus and NLP tools utilized for content extraction from each message in this stage are shown below:
-
CorpusThis corpus comprises two values for each message: the raw text content and the label that categorizes the message into one of the subsets related to the initial problem. In addition, this corpus includes a selection of messages labeled “irrelevant” due to their non-malicious content, according to the data sources used for this research. Hence, there are five labels in this corpus: malware, phishing, spam, bot, and irrelevant.
-
Data CleaningThis activity removes unnecessary characters from the text without altering the main idea of the message. To filter each message, different tasks are performed, such as eliminating unrecognized characters, replacing repetitive line breaks and blank spaces with only one, and removing emoticons and emojis by using regular expression rules.
-
LemmatizationThe lemmatization procedure reduces the morphological variants of a word to their roots or lexemes. Thus, the number of words that appear in this corpus is reduced, making it possible to minimize the diversity of the words needed to represent the content of a message.
| (3) # Hashtags |
| (11) # Uppercase |
Once information about the structure of the text has been extracted, specific text components, such as email addresses and mentioned users, are replaced with predefined tokens like “email_nlp” and “at_user_nlp” to simplify the message and reduce the number of words that exist in the corpus. Furthermore, the hash symbol “#” is removed from the aforementioned tags to be used as tokens.
3.3. Uniform Resource Locator Structure
Uniform Resource Locators (URLs) in a message sometimes may not show the true website domain to the user because of URL shortening services, causing users to be redirected to a different website than expected when clicking the URL. By utilizing software tools to reveal the final website of shortened URLs, this stage analyzed the authentic domain and extracted characteristics from the resulting URL. Table 2 shows 27 characteristics used to represent the properties of a URL present in a message, which delivered the most satisfactory results during the subsequent stages of this research.
Table 2. Features extracted from the URL structure.
This step involves encoding the arrays containing the tokens, text structure, and URL structure into numeric values, which will serve as the input, as vectors, to the CNN architecture. The procedures to obtain these vectors are explained below:
-
Hashing VectorEach word in the dictionary of this corpus is assigned a unique integer hash using the hashing model. The hash acts as an identifier for each token in the array, resulting in a vector of integers representing the initial token array. In addition to the token array, two characteristics from the URL structure are appended as tokens, such as the “domain suffix” and “registrant,” which complement the content using information referring to each URL that appears. Likewise, if the message does not have a URL, the tokens “no_domain” and “no_suffix” are appended to the URL_ZERO values.Finally, unlike other models such as the bag-of-words model, the size of the vectors used in this model does not depend on the number of words in the vocabulary. Therefore, the vector size was determined based on the length of the message with the maximum number of tokens after the content analysis from the training dataset. This value defines the size of these vectors.
-
Text StructureThis vector represents the structural and typographic characteristics of the raw text in a message. The vector consists of the extracted values, as shown in Table 1, from the message structure array. Thus, the size of this vector is equal to the number of extracted features, with a total of 16 values.
-
URL StructureThis vector is created for each URL present in the message. The extracted values from the URL structure array, as shown in Table 2, integrate this vector. Likewise, if the message does not have a URL, this vector is created using predefined values, defined as “URL_ZERO” values, that symbolize the lack of a URL in the message.Although the quantity of elements in the URL structure is 27, this vector utilizes 25 because two of them (the “domain suffix” and “registrant” values) are utilized as tokens for the hashing vector process. Therefore, the final number of elements represents the size of the resulting URL vector.
5. Deep Learning Model
Kim [4] stated that a CNN model can utilize documents as a matrix of words, similar to how it handles pixels for image recognition and computer vision tasks. For this reason, and according to the earlier review of the works in the literature that employ this model, this part presents a CNN architecture that utilizes the three resulting vectors from the previous stages to detect and classify the cyberattacks defined in the initial problem.
After the flattening layer, an additional layer is added to the architecture. This layer concatenates the resulting convolutional vector using the “text” and “URL” structure vectors before continuing with the fully connected layers. The details of each stage in this CNN architecture are shown below:
-
Convolution LayerThe initial layer of this architecture is a convolution layer, which extracts the features from the hash tokens to preserve the relationship between each value. This layer utilizes a ReLU activation function to break the linearity and increase the non-linearity during this process.
-
Dropout Layer
-
POS TaggingThe purpose of the Part-of-Speech (POS) tags in this research is to accurately define the intended lemma based on the context and grammar of a message, rather than assuming a generic lemma transformation of a word. By applying POS tagging analysis to correctly convert words into lemmas, the number of words in this corpus is reduced compared to considering the text of a message in its raw form.
-
TokenizationTokenization involves breaking down the text of each message from this corpus at the word level to produce an array of individual elements called tokens.
-
StopwordsStopwords play a crucial role in the text by serving as the connecting point for syntax and grammar. However, they do not have meaning when written alone. Thus, to represent the main idea of each message with a reduced number of tokens, the stopwords in each token array were removed.
3.2. Message Structure
The text structure of a message shows how the content was posted and shared on social networks. In this sense, the use of features based on the structure of the text derives from the following hypothesis: extracting morphological properties from the structure of the text of a message could reveal characteristics that harmful content may share with written messages from malicious users. Through experimental analysis of diverse characteristics from messages in this corpus, the 16 properties that yielded the most satisfactory results during the subsequent stages of this research were determined, as shown in Table 1.
Table 1. Features extracted from the message structure.
- This layer utilizes a downsampling operation[5] to make this model more robust to variation, absence, and distortion.
-
Pooling LayerThe pooling operation involves sliding a two-dimensional filter to summarize the features within a region covered by a filter and reduce the number of parameters to learn during the computation performed in the DL model.
-
Flattening LayerThis layer converts the pooling output into a one-dimensional matrix.
-
Concatenation LayerThis layer concatenates the resulting flattened vector with the text and URL structure vectors, creating an input vector for the fully connected layers.
-
Fully Connected LayersThese layers utilize the resulting concatenated vector as input. It is composed of input, hidden, and output layers, where the output layer utilizes the Softmax activation as an activation function to generate the final results.
| (1) Length of message | (9) # Sentences | |||
| (1) Length of URL | (10) # Words | (19) # Equal symbols | ||
| (2) # Tokens | (10) # Mentioned users | |||
| (2) Has security protocol (Y/N) | (11) # IPs | (20) # Question marks | ||
| (3) Creation date (Days) | (12) # Digits | (21) # Wave symbols | (4) # Emails | (12) # Question marks |
| (4) Last update date (Days) | (13) # Hyphens | (22) # Plus signs | (5) # URLs | (13) # Exclamation marks |
| (5) Shortened URL | (14) # Periods | (23) # Colon symbols | (6) # Periods | (14) # Emojis and emoticons |
| (6) # Underscores | (15) # Slashes | (24) # Other characters | (7) # Commas | (15) # Dollar symbols |
| (8) # Digits | (16) # Other symbols |
| (7) # Strings divided by periods | ||
| (16) # Uppercase | ||
| (25) Has extension (Y/N) | ||
| (8) # Strings divided by hyphens | (17) # Lowercase | (26) Domain suffix (Tokens) |
| (9) # Strings divided by slashes | (18) # Ampersand symbols | (27) Registrant (Tokens) |
Furthermore, if a message does not contain a URL, the structure uses specific values called “URL_ZERO” to indicate the absence of a URL in the message. Sometimes, messages may have more than one URL. In such cases, each URL is analyzed separately, resulting in a structure for every URL included in the message.
4. Vectorization
References
- Lampu, B. SMS_ Spam_Ham_Prediction. Available online: https://www.kaggle.com/datasets/lampubhutia/email-spam-ham-prediction (accessed on 22 June 2022).
- Behzadan, V.; Aguirre, C.; Bose, A.; Hsu, W. Corpus and Deep Learning Classifier for Collection of Cyber Threat Indicators in Twitter Stream. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5002–5007.
- Chen, W.; Yeo, C.K.; Lau, C.T.; Lee, B.S. A study on real-time low-quality content detection on Twitter from the users’ perspective. PLoS ONE 2017, 12, e0182487.
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751.
- Brownlee, J. Deep Learning for Natural Language Processing, 1st ed.; Machine Learning Mastery: Vermont, VIC, Australia, 2017; p. 322.
More