Although DL models are a powerful tool for modeling data and improving performance, they, unfortunately, can complicate the model explanation process. Thus, DL models are considered to be complex black-box models. The tradeoff between performance and explanation is the main issue in black-box models. Though DL models exhibit high performance, they are difficult to explain. To overcome this issue, explanation methods have been expanded to interpret DL models and explain their predictions.
2. Explanation Methods
Linardatos et al.
[16][20] summarized the various aspects through which explanation methods can be categorized.
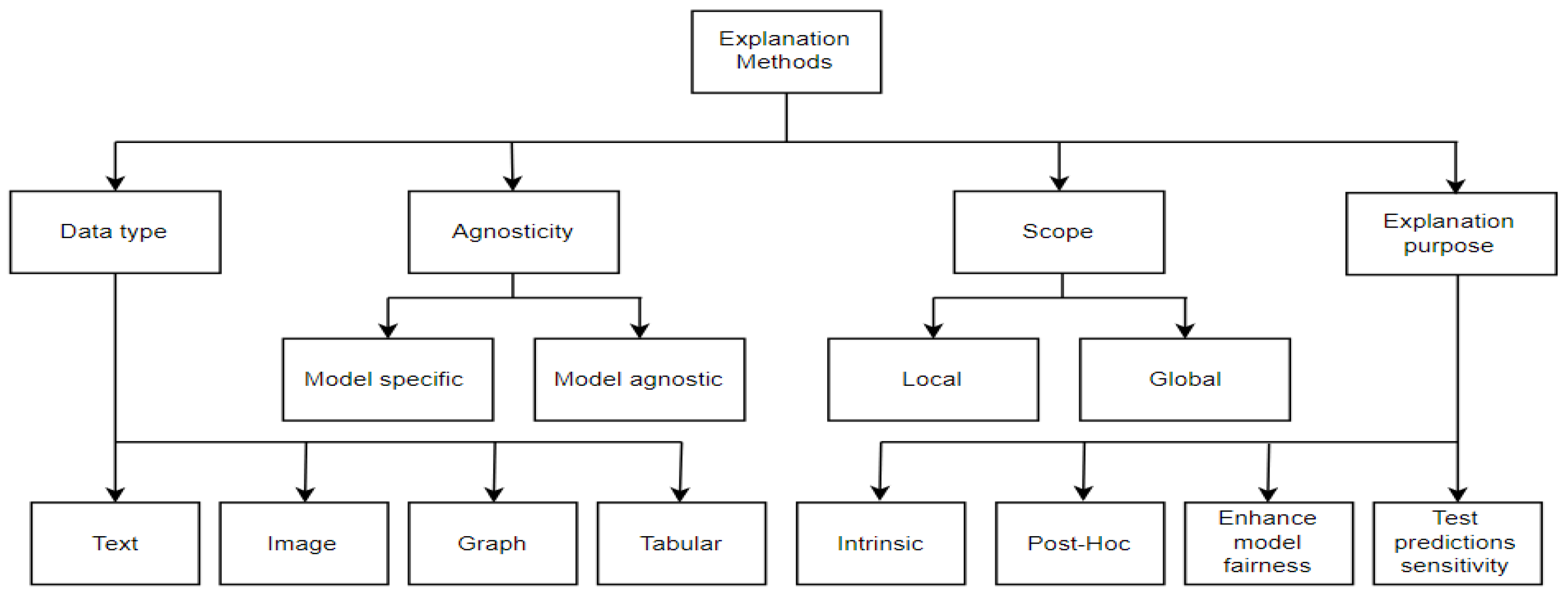
Figure 1 visualizes these aspects: data type, agnosticity, scope, and explanation purpose.
Figure 1.
Taxonomy of explanation methods.
Depending on the data that needs to be explained, explanation methods can be graph-based, image-based, text-based, and tabular-based, while the agnosticity indicates if the explanation method is applicable to explain any type of ML model or if it can explain only a specific type. Some of the explanation methods are local explanations because they are used to explain individual predictions instead of the whole model. The explanation methods can also be classified regarding the purpose of explanation into intrinsic, post hoc, enhanced model fairness, and test predictions sensitivity. Intrinsic-based explanation methods create interpretable models instead of complex models, while post hoc-based methods attempt to interpret complex models instead of using interpretable models. Although fairness is a surprisingly new field of ML explanation
[16][20], the development made in the closing few years was not trivial. Several explanation methods have been produced to improve the fairness of ML models and guarantee the fair allocation of resources.
One of the purposes of the explanation methods is to test the sensitivity of model prediction. Several explanation methods try to evaluate and challenge ML models to support the trustworthiness and reliability of predictions of these models. These methods employ a composition used to analyze the sensitivity, where models are examined in terms of how sensitive their predictions are regarding the fine fluctuations in the corresponding inputs.
The taxonomy in
Figure 1 focuses on the purpose for which these methods were created and the approaches they use to accomplish that purpose. In accordance with the taxonomy, four main categories for explanation methods can be distinguished
[16][20]: methods to interpret complex black-box models, methods to generate white-box models, methods to ensure fairness and restrict the existence of discrimination, and, finally, methods to analyze the model prediction sensitivity. According to
[16][20], methods to interpret complex black-box models can be categorized into methods to interpret DL models and methods to interpret any black-box models. Methods to analyze the model prediction sensitivity can also be classified as traditional analysis methods and adversarial example-based analysis methods. The LIME, SHAP, Anchor, and LORE explanation methods belong to the methods to explain any black-box models.
Ribeiro et al.
[12] proposed the LIME explanation framework that can interpret the outputs of any classification model in an explainable and trusted way. This method relies on learning an explainable model in a local manner around the model output. They proposed an extension framework called (SP-LIME) to interpret models globally by providing representative explanations of individual outputs in a non-redundant manner. The proposed frameworks were evaluated with simulated and human subjects by measuring the impact of explanations on trust and associated tasks. The authors also showed how understanding the predictions of a neural network on images helps practitioners know when and why they should not trust a model.
Lundberg and Lee
[13] proposed the SHAP method to explain the ML model, where the importance of the input features is measured by the Shapley values. These values are inspired by the field of cooperative game theory, which aims to quantify each player’s contribution to the game. They arise in situations where the number of players (features of input data) collaborates to acquire a reward (prediction of ML model). The proposed approach was evaluated by applying kernel SHAP and Deep SHAP approximations on the CNN’s DL model used to classify digital images from the MNIST dataset.
In another work, Ribeiro et al.
[14] introduced a model diagnostic system called Anchor. The Anchor model utilizes a strategy that is based on the perturbation technique to generate local explanations for the ML model outputs. Therefore, instead of the linear regression models implemented by the LIME method, the Anchor explanations are presented as IF–THEN rules that are easy to understand. Anchors adopt the concept of coverage to state exactly which other and possibly unseen instances they apply to. Anchors are determined by methods of an exploration or multi-armed bandit problem, which has its roots in the discipline of reinforcement learning. Several ML models, Logistic Regression (LR), Gradient-Boosted trees (GB), and Multilayer Perceptron (MLP), were explained in this paper to show the flexibility of the Anchor method.
Guidotti et al.
[15] proposed an agnostic method called LORE which provides interpretable and faithful explanations of the ML models. Firstly, a genetic algorithm is used to generate a synthetic neighborhood around the intended instance to allow LORE to learn a local explainable predictor. Then, LORE exploits the concept of the local explainable predictor to derive significant explanations, including decision rules that explain the causes behind the decision and counterfactual rules. These rules present the fluctuations in the features of inputs that lead to a different prediction. SVM, RF, and MLP ML models were explained, in this work, using LORE on three datasets (adult, German, and compass).
3. DDoS Detection Using DL Models
Elsayed et al.
[17][27] leveraged and proposed a DL framework using RNN-autoencoder that aims to detect DDoS attacks in Software Defined Networks (SDN). They exploited the combination of RNN-autoencoder and the SoftMax regression model at the output layer of their framework to differentiate malicious network traffic from normal traffic. Their proposed framework was held in two phases: the unsupervised pre-training phase and the fine-tuning phase. The first phase was utilized to obtain the valuable features that represent the inputs. The RNN-autoencoder was trained in an unsupervised mode to obtain the compressed representation of the inputs. The second phase was implemented to further optimize the whole network, where the supervised mode was exploited to train the output layer of the framework by the labeled instances. The authors evaluate their approach by performing only binary classification on the CICDDoS2019 dataset, which includes a wide variety of DDoS attacks.
Kim
[18][28] leveraged two machine learning models: a basic neural network (BNN) and a long short-term memory recurrent neural network (LSTM) to analyze DDoS attacks. The author investigated the effect of combining both preprocessing methods and hyperparameters on the model performance in detecting DDoS attacks. In addition, he investigated the suboptimal values of hyperparameters that enable quick and accurate detection. Kim also studied the effect of learning the former on learning sequential traffic and learning one dataset on another dataset in a DDoS attack. In Kim’s work, the well-known methods Box–Cox transformation (BCT) and min-max transformation (MMT) were utilized to preprocess two datasets, CAIDA and DARPA, and then the detection approach was used to perform binary classification.
Hawing et al.
[19][29] proposed an LSTM-based DL framework to conduct packet-level classification in Intrusion Detection Systems (IDSs). Instead of analyzing the entire flow, such as a document, the proposed method considered every packet (as a paragraph). The approach then constructed the key sentence from every considered packet. After that, it applied word embedding to obtain semantics and syntax features from the sentence. The knowledge of the sentence was chosen instead of using the entire paragraph as long as the paragraph content can be obtained from the key sentence. Their work utilized ISCX2012 and USTC-TFC2016 datasets, which include DDoS attacks, to evaluate the binary classification using the proposed approach.
Yuan et al.
[20][30] proposed an approach called DeepDefense that leveraged different neural network models, CNN, RNN, LSTM, and GRU, to distinguish DDoS attacks from normal network traffic. The DeepDefense approach identifies DDoS attacks depending on Recurrent Neural Networks, such as LSTM and GRU, by utilizing a sequence of continuous network packets. Feeding historical information into the RNN model is helpful in figuring out the repeated patterns representing DDoS attacks and setting them in a long-term traffic series. DeepDefense also adopts the CNN model to obtain the local correlations of network traffic fields. In this work, DeepDefense compared four combinations of models (LSTM, CNNLSTM, GRU, and 3LSTM) to detect DDoS attacks. These components were evaluated on the binary classification of the ISCX2012 dataset.
Cui et al.
[21][31] performed a systematic comparison of the DL models based on IDSs to provide fundamental guidance for DL network selection. They compared the performance of basic CNN, inception architecture CNN, LSTM, and GRU models on binary and multiclass classification tasks. The comparison carried out on the ISCX2012 dataset shows that CNNs are suitable for binary classification, while the RNNs provide better performance of some complicated attacks in multiclassification detection tasks.
Zhang et al.
[22][32] presented a deep hierarchical network that combines the LeNet-5 model and the LSTM model. This network consists of two layers: the first layer is established on the inhancedLeNet-5 network to obtain the spatial features from the flow, while the second layer utilizes the LSTM to obtain the temporal features. Both layers are concurrently trained to allow the network to figure out the spatial and temporal features. The extracted features from the flow do not ask for prior knowledge; hence there is no need to manual extracting of the flow features with certain meanings. The proposed approach was used to detect intrusions, including DDoS attacks, in CICIDS2017 and the CTU dataset.
Azizjon et al.
[23][33] proposed a DL framework to develop an effective and flexible IDS by exploiting 1DCNN. They established an ML model based on the 1D-CNN by sending the TCP/IP packets in series over a time range to mimic invasion traffic for the IDS. Using the proposed approach, normal and abnormal network traffic were classified. The authors also performed a comparison between the performance of their framework and two traditional ML models (Random Forests and SVM). The proposed detection model is evaluated by performing a binary classification of the UNSWNB15 dataset that includes DDoS attacks.
4. Explanation Methods
Batchu and Seetha
[24][34] developed an approach to address several issues that make the detection of DDoS attacks in the CICDDoS2019 dataset using ML models less efficient. These issues include the existence of irrelevant dataset features, class imbalance, and lack of transparency in the detection model. The authors first preprocessed CICDDoS2019 and used the adaptive synthetic oversampling technique to address the imbalance issue. They then conducted a selection mechanism for the dataset features through embedding SHAP importance to eliminate recursive features with GB, DT, XGBM, RF, and LGBM models. After that, LIME and SHAP explanation methods are performed on the dataset with selected features to ensure model transparency. Finally, binary classification is performed by feeding the selected features to KNORA-E and KNORA-U dynamic ensemble selection techniques. The classification experiment is performed on balanced and imbalanced datasets. The finding shows that the balanced dataset performance outperformed the imbalanced datasets. The obtained accuracy was 99.9878% and 99.9886% when using KNORA-E and KNORA-U, respectively.
Barli et al.
[25][35] proposed two approaches, LLC-VAE and LBD-VAE, to mitigate DoS using the structure of the Variational Autoencoder (VAE). The goal of Latent Layer Classification (LLC-VAE) is to differentiate various types of network traffic using the representations from the latent layer of the VAE, while Loss Based Detection algorithm (LBD-VAE) attempts to discover the patterns of benign and malicious traffic using the VAE loss function. Their approaches were designed to show deep learning algorithms (VAE) able to detect certain types of DoS attacks from network traffic and test how to generalize the model to detect other types of attacks. Authors in this work used CICIDS2017 and CSECICIDS2018 datasets to evaluate their framework. As a further adjustment, they utilized the LIME explanation method to test how the LLC-VAE can be enhanced and to define whether it could be used as a method for constructing a mitigation framework. The result from this work demonstrates that deep learning-based frameworks could be efficient against DoS attacks, and LBD-VAE does not currently conduct enough to be applied as a mitigation framework. The superior findings were obtained using the LLC-VAE for its ability to identify benign and malicious traffic at an accuracy of 97% and 93%, respectively. In this work, the LLC-VAE has shown its capability to compete with the traditional mitigation frameworks, but it needs more settings to achieve better performance.
Han et al.
[26][36] developed an approach to explain and enhance anomaly detection based on DL in security fields called DeepAID. DeepAID was developed by utilizing two techniques, Interpreter and Distiller, to provide interpretation for unsupervised DL models that meet demands in security domains and to solve several problems such as decision understanding, model diagnosing and adjusting, and decreasing false positives (FPs). The Interpreter produces interpretations of certain anomalies to help understand why anomalies happen, while a model-based extension Distiller uses the interpretations from the Interpreter to improve security systems. The authors, in this work, divided the detection methods into three types based on the structure of source data: tabular, time-series, and graph data. They then provided prototype applications of DeepAID Interpreter through three representative frameworks (Kitsune, DeepLog, and GLGV) and Distiller over tabular data-based systems (Kitsune). The results showed that DeepAID could introduce explanations for unsupervised DL models well while meeting the specific demands of security fields and can guide the security administrators to realize the model decisions, analyze system failures, pass feedback to the framework, and minimize false positives.
Le et al.
[27][37] proposed ensemble tree models approach, Decision Tree (DR) and Random Forest (RF), to improve IoT-IDSs performance that evaluated on three IoT-based IDS datasets (IoTID20, NF-BoT-IoT-v2, and NF-ToN-IoT-v2). The authors claim that their proposed approaches provide 100% performance in terms of accuracy and F1 score compared to other methods of the same used datasets, while they demonstrate lower AUC compared to previous DFF and RF methods using the NF-ToN-IoT-v2 dataset. The authors, in this work, also exploited the SHAP method in both global and local explanations. The global explanation was used to interpret the model’s general characteristics by analyzing all its predictions by the heatmap plot technique. On the other hand, the local explanation was used to interpret the prediction results of each input (instance) of the model using the decision plot technique. The object of this work is to provide experts in cyber security networks with more trust and well-optimized decisions when they deal with vast IoT-IDS datasets.
Keshk et al.
[28][19] proposed the SPIP (S: Shapley Additive exPlanations, P: Permutation Feature Importance, I: Individual Conditional Expectation, P: Partial Dependence Plot) framework to assess explainable DL models for IDS in IoT domains. They implemented Long Short-Term Memory (LSTM) model to conduct binary and multiclassification in three datasets: NSL-KDD, UNSW-NB15, and ToN_IoT. The predictions of the LSTM model were interpreted locally and globally using SHAP, PFI, ICE, and PDP explanation methods. The proposed approach extracted a customized set of input features that were able to outperform the original set of features in the three datasets and enhanced the utilization of AI-based IDS in the cyber security system. The results of this work showed that the explanations of the proposed method depend on the performance of IDS models. This indicates that the performance of the framework is affected negatively in the presence of poorly built IDS, which causes the proposed framework to be unable to detect the exploited vulnerability by the attack.
Neupane et al.
[29][38] proposed a taxonomy to address some issues in the systematic review of recent state-of-the-art studies on explanation methods. These issues include the absence of consensus about the definition of explainability, the lack of forming explainability from the user’s perspective, and the absence of measurement indices to evaluate explanations. This work focused on the importance and applicability of the explanation models in the domain of intrusion detection. Two distinct approaches, white and black boxes, were presented in detail in the literature of this survey which addresses the concern of explainability in the IDS field. While the white-box explanation models can provide more detailed explanations to guide decisions, the performance of their prediction is, in general, exceeded by the performance of black-box explanation models. The authors also proposed architecture with three layers for an explanation-based IDS according to the DARPA-recommended architecture for the design of explanation models. They claim that their architecture is generic enough to back a wide set of scenarios and applications that are not limited to a certain specification or technological solution. This work provided research recommendations that state that the domain of IDS needs a high degree of precision to stop attack threats and evade false positives and recommend using black-box models when evolving an explanation-based IDS.
Zhang et al.
[30][39] proposed a survey of state-of-the-art research that uses XAI in cyber security domains. They conducted the basic principles and taxonomies of state-of-the-art explanation models with fundamental tools, including general frameworks and available datasets. Also, the most advanced explanation methods based on cyber security systems from various application scenarios were investigated. These scenarios included explanation methods applications to defend against different types of cyberattacks, including malware, spam, fraud, DoS, DGAs, phishing, network intrusion, and botnet, explanation methods in distinct industrial applications, and cyber threats that target explanation models and corresponding defensive models. The implementation of the explanation models in several smart industrial areas (such as healthcare, financial systems, agriculture, cities, and transportation) and Human–Computer Interaction was presented in this work.
Capuano et al.
[31][40] reviewed the published studies in the past five years that proposed methods that aim to support the relationship between humans and machines through explainability. They performed a careful analysis of explanation methods and the fields of cyber security most affected by the use of AI. The main goal of this work was to explore how each proposed method introduces its explanation for various application fields and illuminate the absence of general formalism and the need to move toward a standard. The final conclusion of this work stated that there is a need for considerable effort to guarantee that ad hoc frameworks and models are constructed for safety and not for the application of general models for post hoc explanation.
Warnecke et al.
[32][41] introduced a standard to compare and assess the explanation methods in the computer security domain. They classified the investigated explanation methods into black-box methods and white-box methods. In this work, six explanation methods (LIME, SHAP, LEMNA, Gradients, IG, and LRP) were investigated and evaluated. The evaluation metrics of completeness, stability, efficiency, and robustness were implemented in this work. The authors applied the DL model RNN to four selected security systems (Drebin+, Mimicus+, DAMD, and VulDeePecker) to provide a diverse view of security. They construct general recommendations to select and utilize explanation methods in network security from their observations of significant differences between the methods.
Fan et al.
[33][42] proposed principled instructions to evaluate the quality of the explanation methods. Five explanation approaches (LIME, Anchor, LORE, SHAP, and LEMNA) were investigated. These approaches were applied to detect Android malware and identify its family. The authors designed three quantitative metrics to estimate stability, effectiveness, and robustness. These metrics are principal properties that an explanation approach should fulfill for crucial security tasks. Their results show that the evaluation metrics are able to evaluate different explanation strategies and enable users to learn about malicious behaviors for accurate analysis of malware.
The aforementioned works included recent research that exploited the DL models to detect the DDoS attack in network traffic and explanation methods that are used to interpret the DL model’s decisions in security applications.