sEMG signal analysis refers to a series of processing steps applied to the acquired human sEMG signals using signal acquisition devices. The primary objective is to eliminate irrelevant noise unrelated to the intended movements while retaining as many useful features as possible. This process aims to accurately identify the user’s intended movements.
The feature engineering techniques allow for the mapping of high-dimensional sEMG signals into a lower-dimensional space. This significantly reduces the complexity of signal processing, retaining the useful and distinguishable portions of the signal while eliminating unnecessary information. However, due to the stochastic nature of sEMG signals and the interference between muscles during movement, traditional feature engineering inevitably masks or overlooks some useful information within the signals, thereby limiting the accuracy of intent recognition. Additionally, since sEMG signals contain rich temporal and spectral information, relying on specific and limited feature combinations may not yield the optimal solution
[8][45]. Moreover, a universally effective feature has not been identified thus far, necessitating further exploration of features that can make significant contributions to improving intent recognition performance.
2. Decoding Model
Decoding models serve as a bridge between user motion intentions and myoelectric prosthetic hand control commands, playing a significant role in motion intention recognition schemes. The purpose of a decoding model is to represent the linear or nonlinear relationship between the inputs and outputs of the motion intention recognition scheme, which can be achieved through either establishing an analytical relationship or constructing a mapping function. The former are known as model-based methods, while the latter are referred to as model-free methods
[9][8], which include traditional machine learning algorithms and deep learning algorithms.
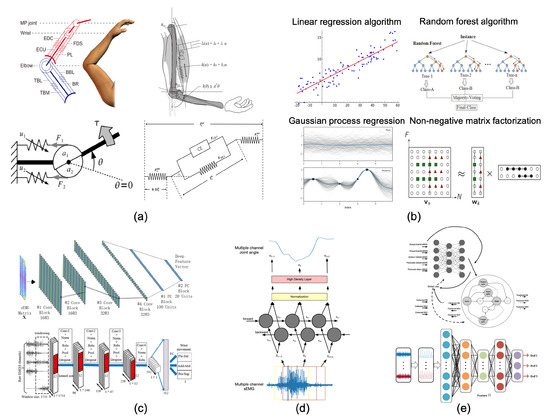
Figure 2. Application examples of decoding models: (
a) Example of musculoskeletal model applications
[10][11][12][13][23,60,61,62]. (
b) Examples of traditional machine learning model applications. (
c) Example of CNN-based model applications.
[14][15][46,49]. (
d) Example of RNN-based model applications
[16][37]. (
e) Example of hybrid-structured model applications
[17][18][40,41].
2.1. Musculoskeletal Models
Musculoskeletal models are the most commonly used model-based approaches for myoelectric prosthetic hand control. These models aim to understand how neural commands responsible for human motion are transformed into actual physical movements by modeling muscle activation, kinematics, contraction dynamics, and joint mechanics
[19][63]. Incorporating detailed muscle–skeletal models in the study of human motion contributes to a deeper understanding of individual muscle and joint loads
[20][64]. The earliest muscle model was first proposed by A. V. Hill in 1938. It was a phenomenological lumped-parameter model that provided an explanation of the input–output data obtained from controlled experiments
[21]. Through the efforts of researchers, the muscle–skeletal models commonly used in the field of EMG prosthetic hand control include the Mykin
[10][23] and simplified muscle–skeletal models
[22][25].
Musculoskeletal models, which encode the explicit representation of the musculoskeletal system’s anatomical structure, can better simulate human physiological motion
[23][65], and are, therefore, commonly applied in research on human motion intention recognition. However, for EMG prosthetic hand human–machine interfaces based on motion skeletal models, it is necessary to acquire sEMG signals corresponding to the muscles represented by the model. This may require the use of invasive electrodes, which inevitably pose physical harm to the subjects’ limbs and require the involvement of expert physicians, leading to various inconveniences and obstacles. Another promising approach to facilitate the wider application of muscle–skeletal models is the localization of specific muscles in the subjects’ limbs through high-density sEMG signal decomposition techniques.
2.2. Traditional Machine Learning Models
Machine learning algorithms typically establish mappings between inputs and desired target outputs using approximated numerical functions
[9][8]. They learn from given data to achieve classification or prediction tasks and are widely applied in the field of motion intention recognition.
Gaussian processes are non-parametric Bayesian models commonly applied in research on human motion intention recognition. Non-negative matrix factorization (NMF) is one of the most popular algorithms in motion intention recognition based on sEMG. As the name suggests, the design concept of this algorithm is to decompose a non-negative large matrix into two non-negative smaller matrices. In the field of motion intention recognition based on sEMG, the sEMG signal matrix is often decomposed into muscle activation signals and muscle weight matrices using non-negative matrix factorization algorithms. The muscle weight matrix is considered to reflect muscle synergies
[24][29].
Despite achieving certain results, motion intention decoding models based on traditional machine learning algorithms often rely on tedious manual feature engineering. Research has shown that methods utilizing traditional machine learning algorithms still fail to meet the requirements of current human–machine interaction scenarios, such as EMG prosthetic hand control, in terms of accuracy and real-time responsiveness
[25][66].
2.3. Deep Learning Models
Deep learning algorithms can be used to classify input data into corresponding types or regress them into continuous sequences in an end-to-end manner, without the need for manual feature extraction and selection
[26][9]. The concept of deep learning originated in 2006
[27][67], and, since then, numerous distinctive new algorithm structures have been developed.
CNN-based models: CNN was first proposed in 1980
[28][68]. Due to its design of convolutional layers, it has the capability to learn general information from a large amount of data and provide multiple outputs. CNN has been applied in various fields such as image processing, video classification, and robot control. It has also found extensive applications in the field of motion intention recognition;
RNN-based models: The introduction of RNN was aimed at modeling the temporal information within sequences and effectively extracting relevant information between input sequences. However, due to the issue of vanishing or exploding gradients, RNN struggles to remember long-term dependencies
[26][9]. To address this inherent limitation, a variant of RNN called Long short-term memory (LSTM) was introduced, which has gained significant attention in research on recognizing human motion intentions. Numerous studies have been conducted on the application of LSTM in this field;
Hybrid-structured models: Hybrid-structured deep learning algorithms typically consist of combining two or more different types of deep learning networks. For motion intention recognition based on sEMG, hybrid-structured deep learning algorithms often outperform other approaches in intention recognition tasks. One compelling reason for this is that hybrid-structured algorithms extract more abstract features from sEMG signals, potentially capturing more hidden information. This leads to improved performance in motion intention recognition.
Deep learning algorithms have been widely applied in the recognition of human motion intentions due to their unique end-to-end mapping approach. They eliminate the need for researchers to manually extract signal features and instead learn more abstract and effective features through the depth and breadth of their network structures. However, their lack of interpretability makes it challenging to integrate them with biological theories for convincing analysis. Moreover, the increased complexity of networks associated with improved recognition accuracy results in significant computational demands. This poses challenges for tasks such as EMG prosthetic hand control that require fast response times within specific time frames. Currently, most research in this area is based on offline tasks. Therefore, key technical research focuses on how to incorporate human biological theories into the design of deep learning algorithms and achieve high accuracy and fast response in motion intention recognition solely through lightweight network structures.
3. Mapping Parameters
Mapping parameters, as the output part of the motion recognition scheme, serve as the parameterization of user motion intention and control commands for the myoelectric prosthetic hand system. Human hand motion is controlled by approximately 29 bones and 38 muscles, offering 20–25 degrees of freedom (DoF)
[29][69], enabling flexible and intricate movements. The movement of the human hand is achieved through the interaction and coordination of the neural, muscular, and skeletal systems
[30][70]. This implies that the parameterization of motion intention should encompass not only the range of motion of each finger but also consider the variations in joint forces caused by different muscle contractions. In myoelectric hand control, two commonly used control methods exist
[9][8]: (1) Using surface electromyography (sEMG) as the input for decoding algorithms, joint angles are outputted as commands for controlling low-level actuators; (2) Using sEMG as the input, joint torques are output and sent to either the low-level control loop or directly to the robot actuators (referred to as a force-/torque-based control algorithm).
3.1. Kinematic Parameters
Parameterizing human motion intention typically involves kinematic parameters such as joint angles, joint angular velocity, and joint angular acceleration:
Joint angle: Analyzing biomechanical muscle models reveals
[8][45] that joint angles specifically define the direction of muscle fibers and most directly reflect the state of motion;
Joint angular velocity: Joint angular velocity is more stable compared to other internal physical quantities, making it advantageous for better generalization to new individuals. It is closely related to the extension/flexion movement commands of each joint
[31][71];
Joint angular acceleration: Joint angular acceleration describes the speed at which the joint motion velocity in the human body changes. The relationship between joint angular acceleration and joint angular velocity is similar to the relationship between joint angles and joint angular velocity. Some studies suggest a significant correlation between joint angular acceleration and muscle activity
[32][72].
3.2. Dynamics Parameters
When using a myoelectric prosthetic hand to perform daily grasping tasks, the appropriate contact force is also a crucial factor in determining task success rate for individuals with limb loss. Among the dynamic parameters commonly used for parameterizing human motion intention, joint torque has been proven to be closely related to muscle strength
[21]. For laboratory-controlled prostheses operated through a host computer, suitable operation forces can be achieved using force/position hybrid control or impedance control. However, for myoelectric prosthetic hands driven by user biological signals, effective force control of the prosthetic hand must be achieved by decoding the user’s intention. Therefore, the conversion of human motion intention into dynamic parameters is necessary.
3.3. Other Parameters
A common approach to parameterizing human motion intention using specific indicators involves guiding the subjects to perform specific tasks to obtain target data and using these cues as labels
[33][73]. Motion intention recognition is then achieved using supervised learning decoding models. Representing human motion intention using other forms of parameters to some extent reduces the complexity of intention decoding tasks, simplifying the process and facilitating the application of motion intention recognition schemes to practical physical platforms. However, when relying on end-to-end mapping established by decoding models, if the mapping variables lack meaningful biological interpretations, this further reduces the persuasiveness and interpretability of the already less interpretable decoding models. Therefore, when considering non-biological alternative parameter schemes, it is important to strike a balance between control performance and the interpretability of human physiological mechanisms.