Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Hamed Rezapour and Version 4 by Camila Xu.
Following to a short-circuit fault in distribution networks, the fault should be located and isolated before restoring the supply. A fast and accurate fault location method can help to improve the continuity of supply considerably. In general, the distribution-network fault location methods can be categorized into impedance-based methods, state estimation-based methods, traveling wave-based methods, and artificial intelligence-based (AI-based) methods.
- fault location
- artificial intelligence
- power distribution networks
1. Introduction
Following to a short-circuit fault in distribution networks, the fault should be located and isolated before restoring the supply. A fast and accurate fault location method can help to improve the continuity of supply considerably. In general, the distribution-network fault location methods can be categorized into impedance-based methods, state estimation-based methods, traveling wave-based methods, and artificial intelligence-based (AI-based) methods.
The impedance-based methods determine the location of faults by measuring the apparent impedance seen from one or more measurement points. These methods estimate the fault location by comparing the measured impedance for the probable fault paths in the network with the measured one [1][2][3][4][5][1,2,3,4,5]. These methods can provide fault location estimations with acceptable accuracy, although they might estimate several candidate locations in the networks with several laterals. They require detailed data about the network topology, line impedances, and loads and are, hence, very sensitive to network-model inaccuracies.
State estimation-based methods consider a fault as bad data and try to locate it using the data collected from different measurement points of the network [6][7][8][6,7,8]. Similar to the impedance-based methods, these techniques need the distribution-network data. While they are less sensitive to input data inaccuracies, they can only be applied to networks with considerable measurement infrastructures.
Traveling wave-based methods estimate the fault location by calculating the sweep duration of the wave traveling from the measurement point to the fault location [9][10][11][12][9,10,11,12]. These methods are practically applicable to long transmission lines. However, their application to distribution networks with short line sections demands very high measurement sampling frequency which is not practical. Moreover, the application of these methods to networks with various laterals is challenging.
AI-based methods can be trained in off-line procedures to make fast online estimations of the fault location or faulted section. These methods need a considerable amount of training data which can be based on historical records or be generated in a simulation process.
AI-based algorithms are widely used in various fault diagnosis applications. In [13], an artificial neural network (ANN) based on ACO-DWT is developed for fault identification and classification in HVDC networks. In [14], a method combining attention mechanism and long short-term memory (LSTM) is proposed to investigate tool condition monitoring in milling applications. A tangent hyperbolic fuzzy entropy measure-based method for determining the most sensitive frequency band to easily identify defective components in an axial piston pump is proposed by [15].
2. AI-Based Methods
The application process of AI-based methods is illustrated in Figure 1. The first step of applications is to choose the input variables which comprehend the network condition. In the second step, the features of voltage or current are adopted by using transforms such as Wavelet, Stockwell, and Fast Fourier to generate informative features. Some features are based on high-frequency spectra of signals, and some are based on the fundamental frequency spectrum of the signal such as the root mean square (RMS) value of the fundamental signal. Finally, in the last step, the main algorithm analyzes the input features and gives an estimation of the fault location as the output. In the following, some of the main algorithms employed by the AI-based fault location methods are discussed in details and discussions about each of these steps are provided in their corresponding sections.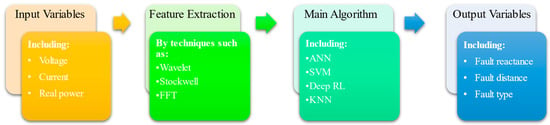
Figure 1.
The process of AI-based fault location methods.
2.1. Artificial Neural Networks (ANNs)
ANN is the most used AI-based algorithm in the field of fault location due to its flexibility and high precision [10][16][17][18][19][20][21][22][23][24][25][26][27][28][29][30][31][32][33][34][35][36][37][10,18,19,20,21,22,23,25,27,28,30,31,32,33,34,35,38,39,40,41,42,43,44]. ANNs are a class of supervised regression algorithms that can be used as a prediction tool. The training procedure of ANNs is based on a series of experienced samples of the system. In a fault location method, the training samples are formed of tuples including inputs (e.g., current or voltage features) and outputs (e.g., fault distance or fault reactance). The training data is often adopted from simulations because this data is extracted from the fault condition, and it is not possible to apply several faults on real-world systems to generate data. However, there might be a record of previous fault signals; ANN needs a large amount of data in different network conditions and fault situations, and the recorded data are often insufficient. An ANN is simply constructed of different layers. There are three types of layers in ANNs: the first as the input layer, the last as the output layer, and hidden layers in between. The input layer connects the input variables (features) to the neurons in the first hidden layer. The hidden layers construct a network connection from the input layer to the output layer and the output layer contains a number of neurons (equal to the number of outputs) connected to the last hidden layer. Figure 2 shows a typical example of an ANN.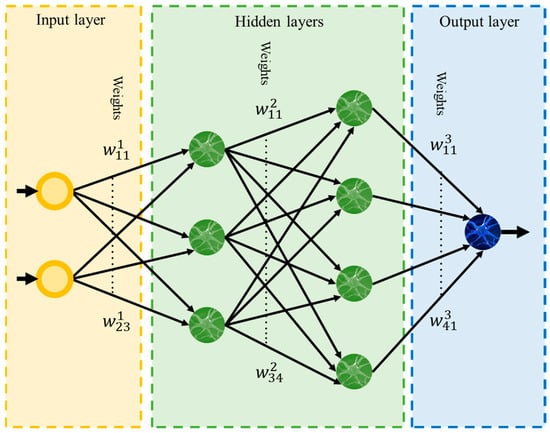
Figure 2.
A typical ANN showing network layers connection.
2.2. Support Vector Machine (SVM)
SVM is a powerful tool for handling classification and regression problems [16][18]. This method determines hyperplanes for separating different classes. For example, in a two-dimension two-class problem, the SVM method determines the line separating the classes, as shown in Figure 3 [47][48][58,59].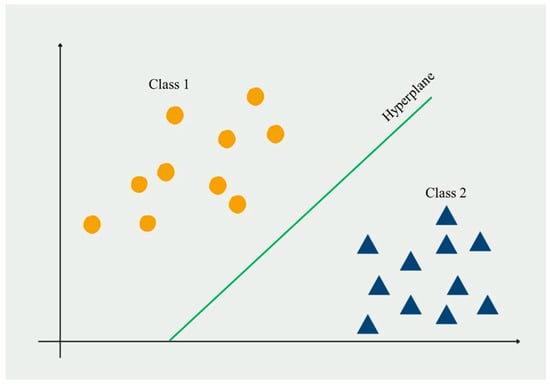
Figure 3.
SVM method applied to a simple two-dimension two-class problem.
2.3. K-Nearest Neighbor
KNN is a simple supervised machine-learning algorithm for both objectives of regression and classification. In fault location applications, KNN is used for both classification and regression purposes, faulted line section and fault type detection are of the classification applications, and determination of fault location is of the regression applications [50][51][26,36]. In this method, the test sample is assigned to the nearest classes depending on the value of K, e.g., if K equals to 1, the sample will be assigned to the first nearest neighbor and if the K equals to 3, the sample will be assigned to the class that is more repeated in the three closest neighbors. Figure 4 shows an example to assign a sample (green square) into two classes; if k equals to 1 (dashed red circle) the sample assigns to class 2 (blue triangles) and if k equals to 3, (solid red circle) the sample assigns to class 1 (orange circles). In some applications, the sample is assigned using weights based on the distance of the sample to the class samples.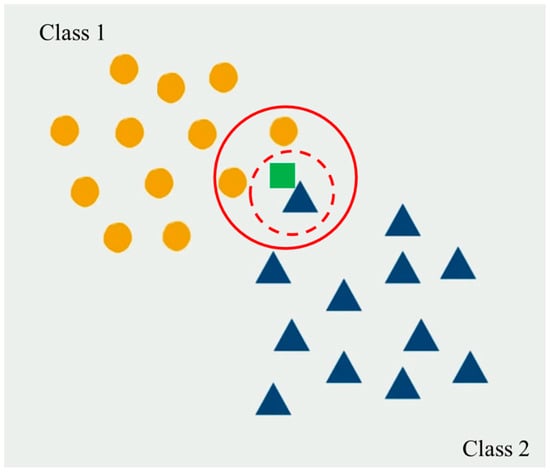
Figure 4. A typical example of the KNN classification method (the green square is the test data, and the red line shows the neighboring area).
2.4. Deep Reinforcement Learning
Deep learning is inspired by the evolution of mammals’ brains. In this method, an agent is trained based on its experiences where actions with rewards registered as good choices and actions with harm registered as unfavorable choices and the agent chooses its next action trying to maximize its reward. Favorable or unfavorable conditions are determined depending on the agent and the environment, e.g., for a mammal, finding food is a favorable situation, and falling from a cliff is unfavorable. In optimization or classification applications, favorability is determined by the operator. For example, for a can gatherer robot, finding new cans is a situation with pleasure, and losing battery is not encouraging. The fundamentals of deep learning are based on reinforcement Q-learning. Q-learning is an efficient optimization tool for solving multistage problems. In each stage of the problem, the next stage (state) is a function of the present stage and the chosen action is based on the following: where 𝑥𝑘 is the present state, 𝑎𝑘 is the chosen action, and 𝑥𝑘+1 is the next state. In this method, each state-action tuple (𝑥𝑘,𝑎𝑘)has a related Q-value and the agent in each state chooses the action with maximum Q-value and reaches the next state. The Q-values are in relation to rewards or penalties the agent gained during its training process (experiences). Q-value for each state action is dependent on its immediate reward and those it might gain in the following next states based on the following equation: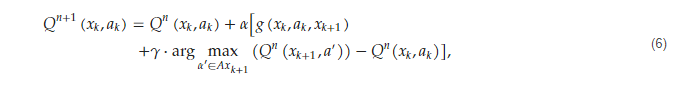 where 𝑛 is the number of the training iteration, is the immediate reward, 𝛼 is the training rate, and 𝛾 is the discount factor.
is dependent to the situation of the next state representing what the agent will experience.
Due to the curse of dimensionality, determining is not an easy job in high dimension or continuous problems and needs high calculation efforts. To cope with this problem, deep neural networks are hired as a regression tool to estimate
for each state-action tuple. The training procedure of DNNs can be performed by using batch-constrained sets of data, including agent experiences, that simulate the behavior of the agent and responses of the environment.
In fault location applications, the agent should be able to classify the fault type and determine the fault location. Hence, the agent should be trained as a tool for regression and classification applications. The input variables can be voltage or current features and the output variables are fault type (e.g., the line to ground (LG), line to line (LL), line to line to ground (LLG), three phase (LLL)), and fault location (a continuous value).
In [52][29], the authors developed a deep neural network-based (DNN-based) method for fault location and identification in low-voltage grids that is topology independent and can also localize high-impedance faults. In [28][33], the authors presented a DRL algorithm for fault diagnosis applications that is goal-oriented and independent of a large amount of labelled data.
where 𝑛 is the number of the training iteration, is the immediate reward, 𝛼 is the training rate, and 𝛾 is the discount factor.
is dependent to the situation of the next state representing what the agent will experience.
Due to the curse of dimensionality, determining is not an easy job in high dimension or continuous problems and needs high calculation efforts. To cope with this problem, deep neural networks are hired as a regression tool to estimate
for each state-action tuple. The training procedure of DNNs can be performed by using batch-constrained sets of data, including agent experiences, that simulate the behavior of the agent and responses of the environment.
In fault location applications, the agent should be able to classify the fault type and determine the fault location. Hence, the agent should be trained as a tool for regression and classification applications. The input variables can be voltage or current features and the output variables are fault type (e.g., the line to ground (LG), line to line (LL), line to line to ground (LLG), three phase (LLL)), and fault location (a continuous value).
In [52][29], the authors developed a deep neural network-based (DNN-based) method for fault location and identification in low-voltage grids that is topology independent and can also localize high-impedance faults. In [28][33], the authors presented a DRL algorithm for fault diagnosis applications that is goal-oriented and independent of a large amount of labelled data.