Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Padraig Corcoran and Version 2 by Lindsay Dong.
Self-supervised representation learning (SSRL) concerns the problem of learning a useful data representation without the requirement for labelled or annotated data. This representation can, in turn, be used to support solutions to downstream machine learning problems. SSRL has been demonstrated to be a useful tool in the field of geographical information science (GIS).
- self-supervised representation learning
- Machine learning
- geographical data
- :geographical data
- self-supervised representation learning
1. Introduction
Machine learning may be defined as the use of methods that can automatically detect patterns in data, and in turn use these patterns to predict future data, or to perform other kinds of decision making under uncertainty [1]. Deep learning is a type of machine learning which involves the use of artificial neural networks with many layers [2]. Deep learning has proven to be useful for solving problems in the fields of natural language processing (NLP) and computer vision, where it significantly outperforms traditional statistical machine learning models such as the support vector machine (SVM) and random forest. More recently, the success of deep learning translated to many other fields. This includes the field of geographical information science (GIS), where it has been successfully applied to a large array of problems. For example, Derrow-Pinion et al. [3] describe how Google Maps uses deep learning to predict travel times. Zhang et al. [4] describe how deep learning can also be used to perform land-use and land-cover classification.
Supervised learning is an approach for training machine learning models using labelled or annotated data [1]. In most cases, the labels are created by manual annotation. Statistical machine learning models can be successfully trained using supervised learning with relatively small amounts of labelled data. On the other hand, to successfully train deep learning models using supervised learning, it is generally necessary to use large amounts of labelled data. However, in some cases, obtaining large amounts of labelled data represents a significant challenge [5], which limits the applicability of deep learning models. In the context of problems within the GIS domain, this challenge stems from many reasons, including user privacy concerns related to sharing data, the cost of labelling data, and the lack of physical access to some geographical locations. For example, it is challenging to obtain labelled data necessary to train models for location or point-of-interest (POI) recommendation [6]. This is known as the cold start problem and occurs when some POIs and users have no known previous visits or check-ins [7]. It is also challenging to obtain labelled data necessary to train models for predicting spatiotemporal phenomena such as air quality [8].
Many solutions to this challenge have been proposed, including transfer learning, semi-supervised learning, and active learning. However, one of the most promising solutions, which has gained a lot of recent attention in the domains of computer vision and NLP, is self-supervised representation learning (SSRL) [9]. An SSRL model aims to learn a useful data representation where semantically similar inputs have similar representations, which in turn simplifies the problem of supervised learning from such representations. Consequently, subsequent or downstream supervised deep learning models can be successfully trained using less-labelled data. SSRL models pose the problem of learning a data representation as a supervised learning problem where the labels in question are derived from unlabelled data in an automated manner. For example, this can be done by masking or hiding parts of the unlabelled data and defining these parts as labels. The most famous examples of SSRL models are word embeddings in the field of NLP, such as word2vec [10] and BERT [11], which learn representations of individual words. These learnt representations capture the semantics of words and as such are commonly used to solve many downstream NLP problems, such as sentiment analysis and question answering.
SSRL can be considered a special form of unsupervised learning. However, SSRL models are distinct from traditional unsupervised learning models, such as clustering, because SSRL models formulate the learning problem as a supervised learning problem using pseudo-labels. To help relate and contrast different SSRL models, it is useful to define a taxonomy or classification scheme for these models. In many cases, the boundaries between different types of models are not clearly defined and this has resulted in different scholars defining the boundaries differently. Furthermore, as the research field of SSRL developed, different taxonomies have been proposed to reflect the development of new and improved models.
The taxonomy divides SSLR models into two main groups of generative and discriminative models. Generative models attempt to learn a useful data representation by learning to generate new data elements that have similar characteristics to the original data elements. An example of a generative model is a variational autoencoder. On the other hand, discriminative models attempt to learn a useful data representation by learning to discriminate between different elements of the original data. The taxonomy subdivides this group of discriminative models into the four subgroups of pretext, contrastive, clustering, and non-contrastive models.
Clustering models attempt to learn a useful data representation such that data elements with similar pseudo-labels are clustered together in this representation. Clustering models can be considered a generalisation of contrastive models where the generalisation in question is from data points to data clusters. Examples of clustering models are DeepCluster [12][17] and SwAV [13][18].
Non-contrastive models attempt to learn a useful data representation such that data elements with similar pseudo-labels are close in this representation. Non-contrastive models are distinct from contrastive models in the sense that they do not require one to explicitly specify pairs of data elements with dissimilar pseudo-labels. Specifying such pairs is one of the greatest challenges to implementing contrastive models, and this was the motivation for the development of non-contrastive models [14][19]. Examples of non-contrastive models are BYOL [14][19] and Barlow twins [15][20].
2. Self-Supervised Representation Learning for Geographical Data
A large proportion of all data has a geographical or spatial element. In fact, some scholars argue that this proportion is 80% or more [16][33]. A taxonomy of geographical data types is displayed in Figure 12. Other scholars have previously proposed taxonomies of geographical data types. However, it found that these mostly contained classical geographical data types and did not capture many of the data types encountered in theour study.
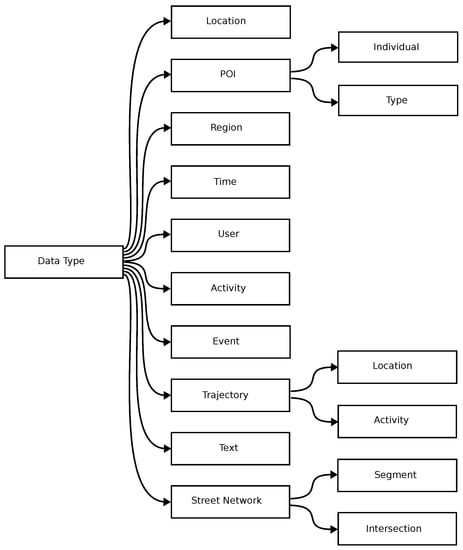
Figure 12.
A taxonomy of geographical data types is displayed.
A location is a geographical location represented by a latitude and longitude pair. Location data is commonly obtained using a GPS receiver. A POI is a location with additional data attached that describes the type or category of an object at that location. Examples of POIs include pubs, shops, and gyms. SSRL can be used to learn specific representations for each individual POI or learn general representations of each POI type. For example, one could learn a representation of a particular pub (e.g., Pen & Wig pub located at 1 Park Grove, Cardiff, CF10 3BJ) or learn a more general representation of a pub as a class of objects (e.g., a kind of drinking establishment that is licensed to serve alcoholic drinks for consumption on the premises). A region is a geographical object that has an area greater than zero and examples include postal codes, cities, and countries. Note that a region may contain many locations and/or POIs. The above definitions of location, POI and region are motivated by the definitions of location, POI, and place, respectively, proposed by the World Wide Web Consortium (W3C) (https://www.w3.org/2010/POI/wiki/Main_Page (accessed on 29 December 2022)).
A user is a person who uses something, such as a place, facility, product, or service, e.g., a user of a location-based social network (LBSN). An activity is an action performed by one or more users. An example is a user performing a POI check-in operation in a LBSN or posting on a social media platform such as Twitter. An event is something that happens or takes place, especially something of importance. Examples of events include a party, a traffic accident, or a weather event such as a storm. An activity is distinct from an event in the sense that the former is user centric while the latter is not.
An example of text is a social media post on Twitter or a postal address. Street segments and street intersections are two types of street network elements. A trajectory corresponds to a sequence of elements where the elements in question may be locations or activities. An example is a sequence of POI check-in operations in a LBSN performed by a given user. Note that there exist a lot of inconsistencies in the literature with respect to the names and definitions of the above geographical data types.
Many articles learnt representations of more than one data type. For example, Yang et al. [17][36] proposed to learn representations of both individual POIs and users in an LBSN. There are two main approaches by which such representation can be learnt. In the first approach, the different representations are learnt independently and sometimes even concurrently. For example, this approach was used in the article by Yang et al. [17][36] mentioned above. In the second approach, the different representations are learnt hierarchically, where one representation is used to define another recursively. For example, Chen et al. [18][49] used this approach to learn representations of activities and users. The scholars first learnt activity representations and subsequently used these representations to learn user representations. In this case, the process of learning user representations equates to modelling a user as a distribution of their corresponding activity representations.
SSRL has been used to learn representations of many geographical data types. Some of the most commonly considered data types are locations, individual POIs, users, and regions. This is partially driven by the public availability of the corresponding datasets. For example, there exist several LBSN datasets from platforms such as Gowalla and Foursquare, that have frequently been used to learn representations of individual POIs and users.
The SSRL models most commonly used to learn representations of geographical data types are pretext and contrastive models.
Representations of geographical data types learnt using SSRL have been used in a diverse collection of downstream applications or problems. Many of these articles used a single data-type representation while many others used multiple data-type representation. The machine learning models most commonly used to solve these problems include neural networks, linear models, visualisation models, and clustering models. It was found that applying machine learning models to representations learnt using SSRL provided superior performance. This demonstrates that the success of SSRL in the fields of computer vision and NLP does also translate to the field of GIS. This finding should further promote and accelerate the adoption of SSRL methods in the field of GIS. Furthermore, in the future, learned representations in all three fields could be fused to enable more useful and powerful machine learning applications.