Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Matt Roach and Version 2 by Camila Xu.
Vehicle detection in parking areas provides the spatial and temporal utilisation of parking spaces. Parking observations are typically performed manually, limiting the temporal resolution due to the high labour cost.
- transfer learning
- vehicle detection
- LiDAR sensor
- faster-RCNN
1. Introduction
In our real-world context, one of the biggest challenges facing city planners and governments is the environmental impact of traffic congestion. In the UK alone, the DEFRA (UK Government Department for Environment Food & Rural Affairs, London, UK) clean air strategy includes a Three billion plan to improve air quality and reduce harmful emissions. Moreover, ≈30% of urban traffic comes from cars searching for parking spaces, with drivers in the UK wasting nearly two whole days (44 h) on average annually (close to three full days in London—67 h) circling the city streets to find vacant spaces. Furthermore, ≈33% of parking spaces are underutilised daily [1], making parking an essential component of sustainable transportation management, especially for high-density large cities.
The topic of parking has received comparatively little study upon which to ground the future development of smart city policies [2]. A primary contributor is that many cities lack the basic information about parking resources [3], particularly on-street parking, due to the effort required to obtain the necessary data through traditional, labour-intensive parking surveys [2]. Detailed data describing the usage of parking spaces over temporal and spatial regions of interest would provide valuable insight, revealing the parking needs, habits, and trends of motorists [4][5][4,5]. However, due to the vast and sparse spatial and temporal regions of interest, on-street parking does not lend itself to easy assessment. Conventional methodologies of performing surveys of on-street parking are to walk or drive through the area of interest, manually tally the number of parked vehicles, and typically only provide coarse measures, such as percentage occupancy [2]. The data from these methods are thus used to gain insight into general parking trends in an area rather than real-time space occupancy, which could inform drivers contemplating a city centre visit [2]. A method which automatically assesses the availability of parking spaces in urban areas would ease congestion and pollution in city centres while increasing driver convenience and have an impact on the productivity of a city region. In practice, various types of sensors for automated traffic monitoring are employed in driving applications, such as loop detectors, road sensors, radar sensors, and Bluetooth sensors [6]. Loop detectors are reliable and cost-effective for detecting vehicles, triggering traffic signals, and managing traffic flow, but they require regular maintenance and can be affected by environmental factors [7]. Road sensors are durable and collect accurate data on traffic flow, occupancy, and speed, but they can be expensive to install and maintain [8]. Radar sensors are accurate and detect a wide range of vehicle types and sizes but can be affected by electromagnetic interference [9]. Bluetooth sensors are inexpensive and easy to install but are limited by the presence of Bluetooth-enabled devices [10]. These traditional sensors typically provide traffic frequency counts in a given location and do not provide high-resolution micro-traffic data, including speed, location, direction, and timestamp [11].
2. A Robust Vehicle Detection Model for LiDAR Sensor Using Simulation Data and Transfer Learning Methods
This section covers the research landscape for a multi-model vehicle or object classification for traffic applications. LiDAR and video are the two most popular choices of sensors to detect vehicle presence; each technique has distinct advantages and disadvantages. When thinking about the task of vehicle detection, humans find the use of camera data intuitive, and it can be straightforward to label data; as such, it has been the basis for many approaches [11][12][11,22]. These approaches use image data from a camera, each pixel represented by grey-scale or colour information, and any objects have to be recognised and segmented (boundaries identified) before their position in space can be determined. Moreover, this can become particularly challenging in low light, e.g., nighttime, conditions where object colours and boundaries can become increasingly hard to establish. Utilising equipment based on LiDAR technology is one approach to overcome this limitation. LiDAR data can be more computationally efficient to process and provide effective coverage of both short and long distances compared to camera images [2][13][2,23]. LiDAR collects high-fidelity point clouds, i.e., a set of data that provides a distance from the sensor to the surfaces in the scene; as such, the location and scale of any objects are captured in the raw data. Additionally, since LiDAR measures the return signal of light emitted from the device, the ambient conditions have very little impact on the returned data. Additionally, new advancements in low-cost LiDAR sensor manufacture also enable the capturing of high-resolution micro-traffic data.
LiDAR-Based Vehicle Detection: There are two different approaches commonly used for vehicle detection and classification with roadside LiDAR data: feature-based approaches and data-driven-based approaches.
Feature-based approaches use hand-crafted feature extraction, e.g., height, width, length, middle drop, etc., from the LiDAR data to classify the vehicles. Using this approach, there are several ways the LiDAR data can be utilised for vehicle detection; for example, the measured LiDAR distance decreases when a vehicle enters the beam, and the corresponding vehicle height is calculated using simple geometry [14][24]; Ref. [15][25] identified robust features for supervised vehicle classification with LiDAR profile data as an input; Ref. [16][26] developed a procedure to extract high-resolution vehicle trajectories with roadside LiDAR sensor data, and these trajectories are applied for traffic performance evaluation; Ref. [17][27] developed a laser-based vehicle classification system based on different criteria, geometrical configuration, occlusion reasoning, sensor specifications, and tracking information. In many cases, these extracted features from feature-based approaches are fed into different classification models such as decision trees, support vector machines and principal component analysis [18][28]. Whilst these approaches are simple and effective, they are not robust to noise and complex scenes; for example, they cannot completely deal well with occlusion, as inferred from [17][18][27,28].
Data-driven approaches utilise different neural networks for the task of classification of 3D point clouds generated by the LiDAR sensor [19][29]. Recently, Convolutional Neural Networks (CNNs) have achieved great success in object detection tasks in both camera and LiDAR data. Several works [20][21][22][30,31,32] take images captured with cameras and apply end-to-end unified fully convolution network frameworks that predict object confidence and object location (bounding boxes) simultaneously. Moreover, detection and localisation have been expanded to 3D LiDAR data for autonomous driving systems [23][33]. Chen et al. [24][34] fused both the LiDAR point cloud features and local image features based on the region-based fusion network to regress the 3D localisation task and 3D object detection, and the method outperformed all other LiDAR-based methods for 2D detection when validating on open-source KITTI data set [25][35].
Two main challenges exist in our real-world application of retrospectively installed LiDAR scanners on street furniture. First, the scanners are installed and connected to IOT resource-constrained devices, which possess some computational power and latency limitations due to the wireless connection. Secondly, the location of the installation on the lamppost means that the data contain many occlusions of vehicles, as illustrated in Figure 1. Object detection algorithms are commonly used for detecting vehicles in images and videos. There are several popular object detection algorithms, such as YOLO (You Only Look Once) [26][36], SSD (Single Shot MultiBox Detector), and Faster R-CNN (Region-based Convolutional Neural Network) [27][37]. These algorithms are based on deep learning techniques, specifically Convolutional Neural Networks (CNNs), which have proven to be effective for image recognition tasks and are known for their adaptability and open-source capabilities. Each algorithm has its own strengths and weaknesses. YOLO is known for its speed and real-time performance, making it ideal for applications such as autonomous driving. SSD strikes a balance between speed and accuracy and is also a popular choice for vehicle detection [28][38]. On the other hand, Faster R-CNN is also known for its accuracy and is commonly used for tasks such as object tracking because of its ability to detect occluded objects [29][39]. It uses a region proposal network to generate potential object locations, which allows it to detect objects even when they are partially occluded or obscured by other objects in the scene [30][40], which is extremely useful in our vehicle parking application. In [28][38], it has been found that the Faster RCNN model is well balanced for recall and precision ratio; however, YOLOv3 has a higher recall ratio than its precision, which means YOLOv3 has more misclassifications. Hence, Faster RCNN was solely chosen to perform all the tasks for the proposed methodology.
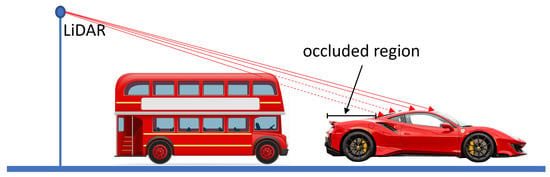
Figure 1.
Occluded region of the vehicle. The car is partially occluded by the bus parked behind it.
One of the most perennial challenges with data-driven approaches, such as CNN, RCNN and faster RCNN, in real-world settings, is the lack of large amounts of annotated data [31][41]. In the absence of real-world data, accurate synthetic data have been used in many applications [32][33][34][42,43,44]. For example, Wang et al. [31][41] generated a synthetic image for photorealistic and non-photorealistic images and then applied the transfer learning method for vehicle detection using a Faster RCNN. Transfer learning improves learning in a new task (target domain) through the transfer of knowledge from a related task (source domain) that has already been learned [35][45]. Specifically, transfer learning improves model performance by starting with the learnt weights from a base model [35][45] and then refining through learning based on limited data of the target task. It follows that the base models need to be well-built and validated to achieve greater performance. Moreover, transfer learning breaks the constraint that the training and test data sets need to follow the same distribution [36][46]. This has benefited several fields when there is insufficient data to train the model, such as denoising, plant sciences, seismic fault detection, structural damage recognition and risk prediction [37][38][39][47,48,49]. However, the two data sets employed should be in similar fields; transfer learning cannot be used if there is no relationship between them.
In transfer learning, there are usually two common strategies: feature extraction and fine-tuning [39][49]. In feature extraction, all parameters in the neural network model of the source domain, apart from the final fully connected layer (often called the softmax), are frozen. The tensor from the final output of the frozen layers is extracted and flattened as features, which is used as input to train a classifier such as a multilayer perceptron or Support Vector Machine (SVM) to achieve the target task [40][50]. For fine-tuning, a natural approach is to optimise all the parameters of the deep network using the target training data. However, fine-tuning the entire network may lead to overfitting if the target data set is limited. Alternately, the parameters of the remaining initial layers can be frozen at their previously trained values while the final few layers of the deep network are fine-tuned. Based on the data size, problem complexity and detection expectation, the above two strategies can be applied in different situations [39][49].